Redis4.0 主从复制(PSYN2.0)
Posted lshs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis4.0 主从复制(PSYN2.0)相关的知识,希望对你有一定的参考价值。
Redis4.0版本相比原来3.x版本,增加了很多新特性,如模块化、PSYN2.0、非阻塞DEL和FLUSHALL/FLUSHDB、RDB-AOF混合持久化等功能。尤其是模块化功能,作者从七年前的redis1.0版本就开始谋划,终于在4.0版本发布了,所以版本号也就从3.x直接迭代到了4.0以表示版本变化之大。简单看了一下新版的PSYN2.0,虽然很多细节没搞清楚,但是大概流程倒是搞明白了。
一、主要流程
在新版的PSYN2.0中,相比原来的PSYN功能,最大的变化支持两种场景下的部分重同步,一个场景是slave提升为master后,其他slave可以从新提升的master进行部分重同步。另外一个场景就是slave重启后,可以进行部分重同步。
在具体实现上redis服务器在生成RDB文件的时候会把当前的复制ID和复制偏移量一起保存到RDB文件中,后面服务器重启的时候,就可以从RDB文件中读取复制ID和复制偏移量,从而可以进行部分重同步功能。另外当服务器从slave提升为master后,会保存两个复制ID,其他slave复制的时候可以根据第二个复制ID来进行部分重同步。
假设两台Redis服务器A和B启动后,对B执行slaveof命令,使得B变为A的从服务器,整体流程如下
1、B在启动的时候,会尝试从RDB文件中加载复制ID和复制偏移量(loadDataFromDisk),如果没有配置RDB文件或者RDB文件中不包含主从复制相关信息,那么使用随机生成的复制ID
2、B接收到slaveof命令时候,设置复制状态为REPL_STATE_CONNECT(replicationSetmaster)
3、周期调度的时间事件中,如果检测到REPL_STATE_CONNECT状态,则会初始化连向master的套接字(serverCron->replicationCron->connectWithmaster),套接字关联事件对应的事件处理程序(syncWithmaster)
4、连接建立后,对应的事件处理程序,则会依据相关设置等,依次发送PING、AUTH、PORT、IP、CAPA、PSYN等信息(syncWithmaster)
其中CAPA表示发送端在主从复制方面支持的能力,目前Redis4.0版本支持两种能力,一个是EOF、另外一个是PSYNC2。
EOF表示slave可以接收直接由套接字发送过来的RDB流。传统的全量复制方式是master首先生成一个RDB文件,然后以$<count> bulk format发送到slave。而EOF格式下,master并不会在硬盘上生成RDB文件,而是先通过$EOF:<40 bytes delimiter>通知slave一个随机生成的40byte结束符,master边生成RDB文件,边发往slave,在slave以接收到的delimiter来判断接收过程结束。
PSYNC2则表示支持Redis4.0最新的PSYN复制操作。
PSYN信息中,slave会把自己的复制ID和复制偏移量发给master
5、master根接收到PSYN消息后,根据复制ID如果复制ID与自己的复制ID相同且复制偏移量仍然存在于复制缓存区中(server.repl_backlog),那么执行部分重同步,回复CONTINUE消息,并从复制缓存区中复制相关的数据到slave。否则执行全量重同步,回复FULLRESYNC消息,生成RDB传输到slave。(实际上master会维护两个复制id,如果PSYN复制ID与第二个复制ID相同且PSYN的复制偏移量没有超过第二个复制ID的偏移量,也会执行部分重同步,参考后面的slave提升为master场景)
7、CONTINUE消息和FULLRESYNC消息中都会带有master的复制ID,slave需要将自己的复制ID更新为master的复制ID(如果两者不同)。
6、同步成功以后,后续master接收到修改数据库的新命令,则会把新命令传输到slave执行。
二、网络闪断超时
master在与slave同步后,slave每隔1s发送一个REPLCONF ACK消息给master,master每隔10s给slave发送一个PING消息。如果master在一定的时间内(server.repl_timeout)没有收到消息,则会释放slave连接。同样如果slave在一定的时间(server.repl_timeout)内没有收到master的PING消息,也会释放套接字连接(replicationCron)。但是slave会设置复制状态为REPL_STATE_CONNECT(replicationHandlemasterDisconnection),后续slave端定时事件调度的时候,则会根据复制状态尝试重新连接。
测试脚本如下
#!/bin/shTIMEOUT=15M_IP=127.0.0.1M_PORT=6379M_OUT=master.outS1_IP=127.0.0.2S1_PORT=6380S1_OUT=slave_1.outS1_RDB_NAME=slave_1.rdbnohup ../src/redis-server --port $M_PORT --bind $M_IP --repl-timeout $TIMEOUT > $M_OUT &nohup ../src/redis-server --port $S1_PORT --bind $S1_IP --dbfilename $S1_RDB_NAME --repl-timeout $TIMEOUT > $S1_OUT&echo set redis hello | nc $M_IP $M_PORTecho lpush num 1 2 3 | nc $M_IP $M_PORTsleep 1echo slaveof 127.0.0.1 6379 | nc $S1_IP $S1_PORTsleep 1echo set redis world | nc $M_IP $M_PORTecho lpush num 4 | nc $M_IP $M_PORTecho save | nc $S1_IP $S1_PORTsleep 5echo "modify iptables"sudo iptables -I INPUT -s 127.0.0.1 -d 127.0.0.2 -j DROPsudo iptables -I OUTPUT -s 127.0.0.2 -d 127.0.0.1 -j DROPecho set redis helloworld | nc $M_IP $M_PORTecho lpush num 5 | nc $M_IP $M_PORTsleep 25echo "restore iptables"sudo iptables -D INPUT -s 127.0.0.1 -d 127.0.0.2 -j DROPsudo iptables -D OUTPUT -s 127.0.0.2 -d 127.0.0.1 -j DROP
最终运行如上脚本,得到如下结果,可以看到在slave初始启动的时候,NO20处slave通过REPLCONF CAPA信息通知master,自己支持EOF格式的RDB传输同时支持PSYNC2.0协议,接着通过PSYNC发送了一个随机生成的复制ID,master收到这个ID后发现与自己的复制ID不相符,需要全量复制,因此回复FULLRESYNC消息,slave收到FULLRESYNC消息后,会把自己的复制ID更新为f8e28****,后续slave生成RDB文件的时候,就会把f8e28****这个复制ID和复制偏移量保存进去。
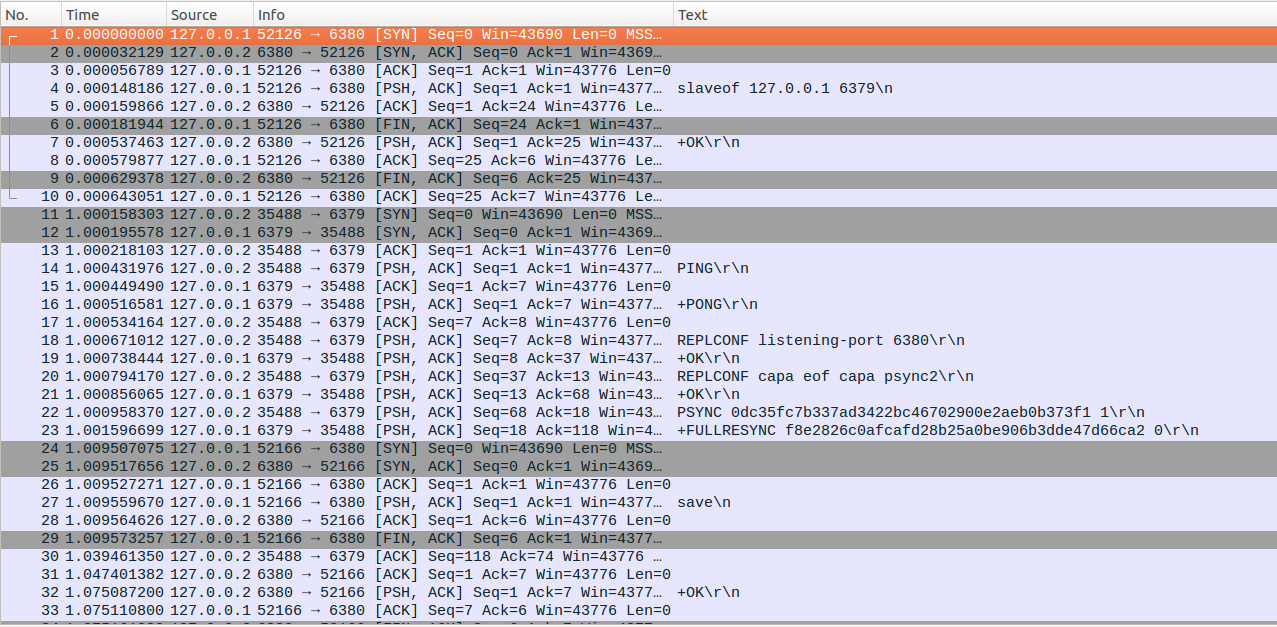
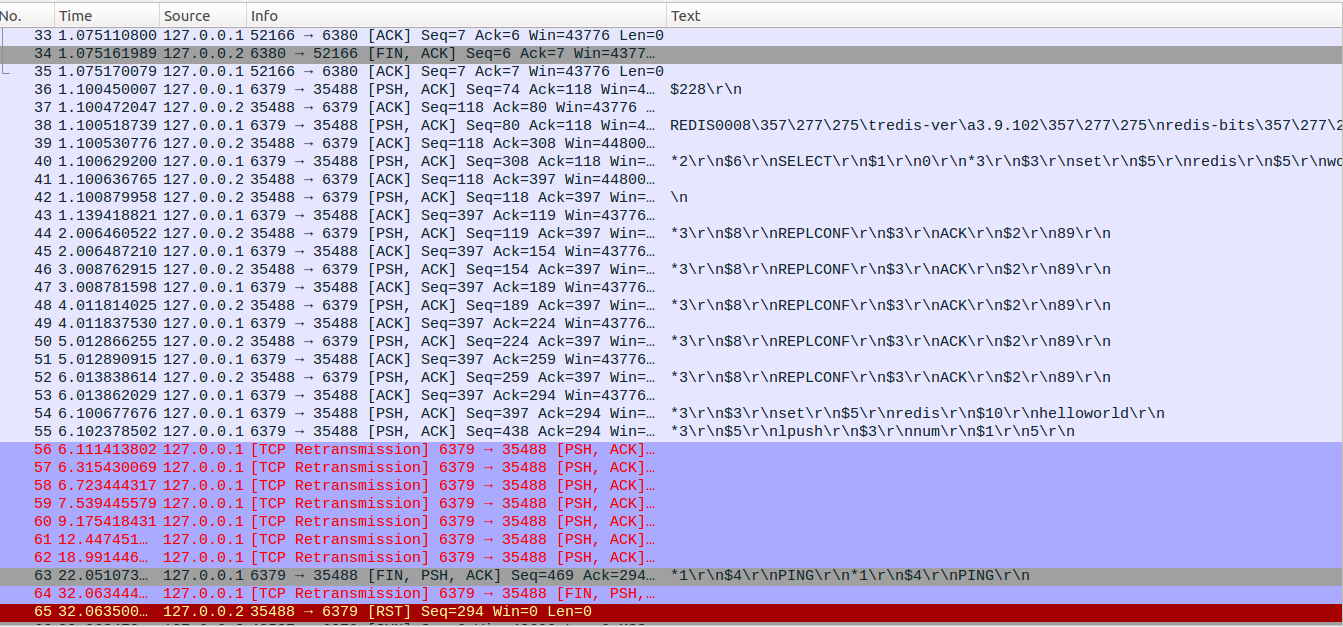
网络闪断超时后,master和slave都会释放连接,当网络恢复后,slave会重新建立连接,同时通过PSYNC消息把对应的复制ID和复制偏移量发给master,master收到PSYNC消息后,发现复制ID与自己相同,说明这个slave之前是自己的slave,同时复制偏移量位于缓存区范围内,因此满足进行部分重同步的条件,回复CONTINUE消息,指示slave进行部分重同步

三、slave提升为master以及slave重启场景
这两种场景是PSYN2.0新增支持的场景,原理也很容易理解,就是通过复制ID来进行匹配的。直接看示例吧,通过一个综合示例来看一下这两种场景
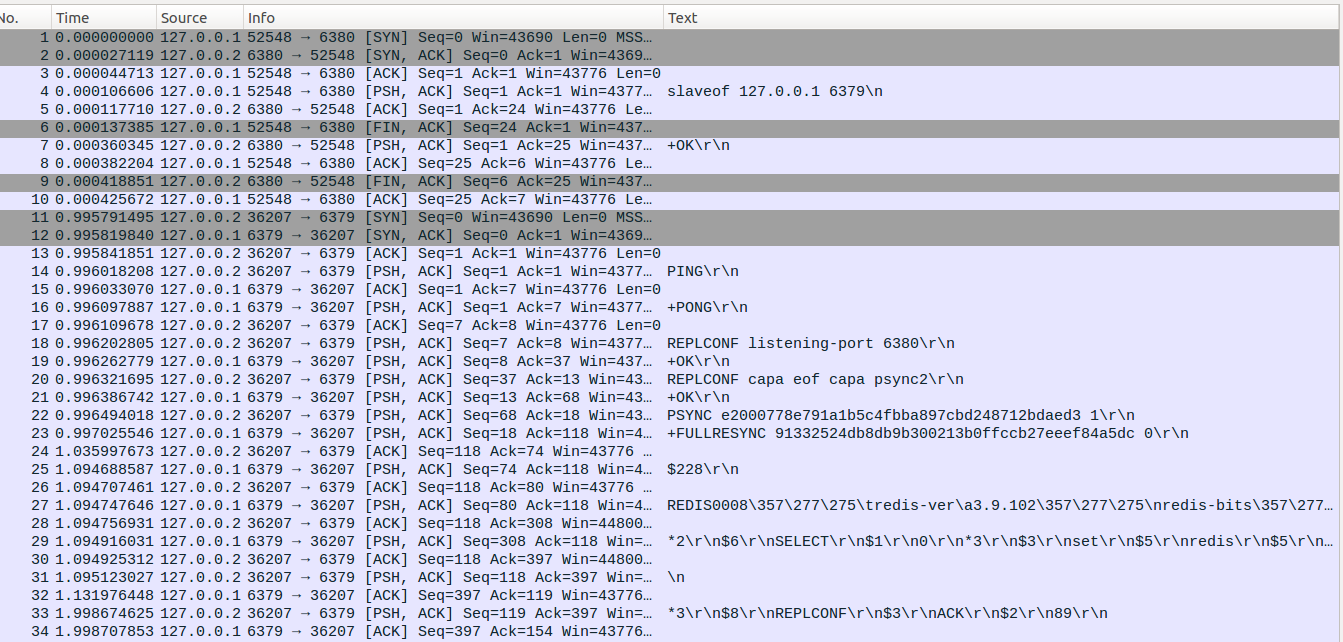
示例场景:首先有一个master和两个从服务器slave1和slave2,同步过程中首先把slave2进程kill掉,然后在master上执行两个命令同步到slave1后,把slave1手动提升为master,并把slave2重启指向之前的slave1
测试脚本
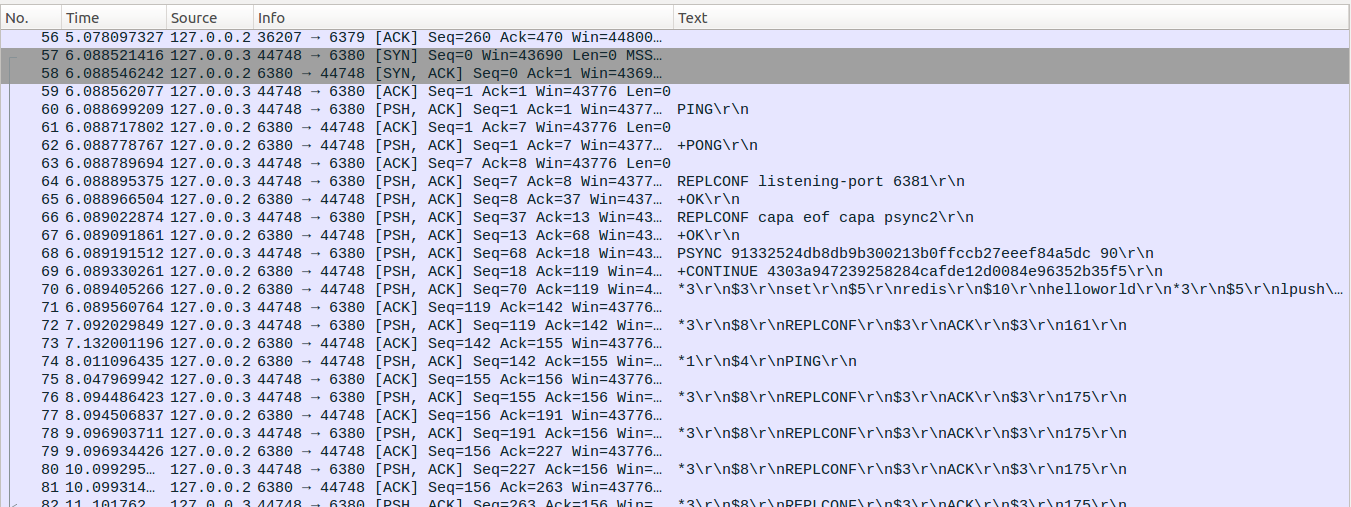
#!/bin/shTIMEOUT=15M_IP=127.0.0.1M_PORT=6379M_OUT=master.outS1_IP=127.0.0.2S1_PORT=6380S1_OUT=slave_1.outS1_RDB_NAME=slave_1.rdbS2_IP=127.0.0.3S2_PORT=6381S2_OUT=slave_2.outS2_RDB_NAME=slave_2.rdbnohup ../src/redis-server --port $M_PORT --bind $M_IP --repl-timeout $TIMEOUT > $M_OUT &nohup ../src/redis-server --port $S1_PORT --bind $S1_IP --dbfilename $S1_RDB_NAME --repl-timeout $TIMEOUT > $S1_OUT&nohup ../src/redis-server --port $S2_PORT --bind $S2_IP --dbfilename $S2_RDB_NAME --repl-timeout $TIMEOUT > $S2_OUT&sleep 1s1_pid=`cat $S1_OUT|grep PID`s1_pid=`echo ${s1_pid#*PID:}`echo s1_pid:$s1_pids2_pid=`cat $S2_OUT|grep PID`s2_pid=`echo ${s2_pid#*PID:}`echo s1_pid:$s2_pidecho set redis hello | nc $M_IP $M_PORTecho lpush num 1 2 3 | nc $M_IP $M_PORTsleep 1echo slaveof $M_IP $M_PORT | nc $S1_IP $S1_PORTecho slaveof $M_IP $M_PORT | nc $S2_IP $S2_PORTsleep 1echo set redis world | nc $M_IP $M_PORTecho lpush num 4 | nc $M_IP $M_PORTsleep 1echo save | nc $S2_IP $S2_PORTkill -9 $s2_pidsleep 3echo set redis helloworld | nc $M_IP $M_PORTecho lpush num 5 | nc $M_IP $M_PORTecho "slave1提升为master"echo slaveof no one | nc $S1_IP $S1_PORTecho "重启slave2 并设置 slaveof $S1_IP $S1_PORT"nohup ../src/redis-server --port $S2_PORT --bind $S2_IP --dbfilename $S2_RDB_NAME --repl-timeout $TIMEOUT > $S2_OUT&sleep 1echo slaveof $S1_IP $S1_PORT | nc $S2_IP $S2_PORT
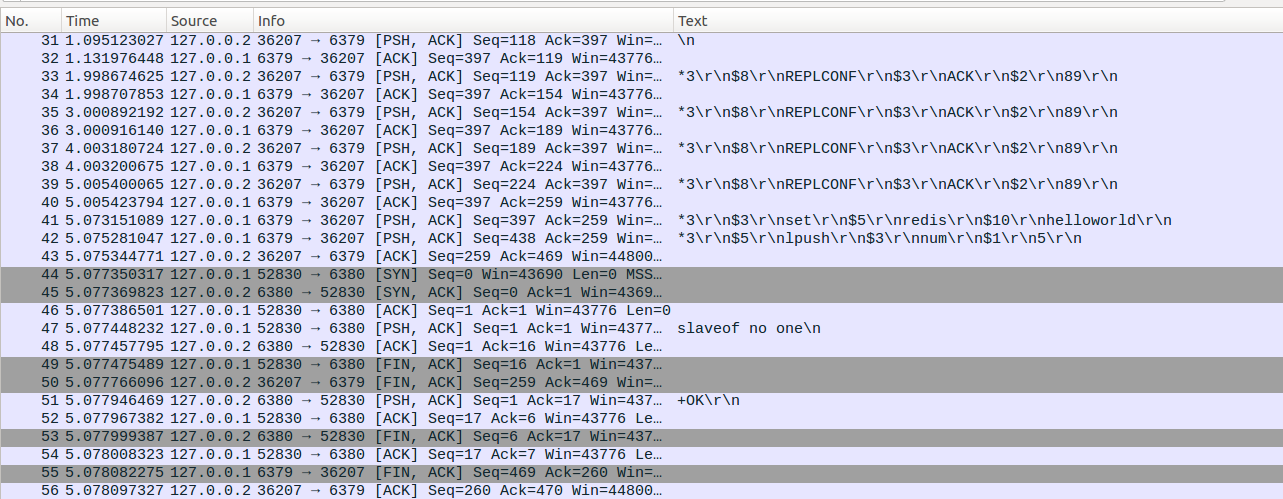
需要注意的是在No68和No69处,slave2重启并设置slaveof 127.0.0.2 6380的时候,127.0.0.2:6380虽然回复了CONTINUE消息,但是复制ID却发生了变化。原因是在127.0.0.2 6380执行slaveof no one的时候,Redis服务器会把当前的复制ID和复制偏移量保存起来,并重新生成一个新的复制ID(shiftReplicationId)。如果后续PSYN收到的复制ID与先前保存的复制ID相同,且复制偏移量小于先前保存的复制偏移量那么就可以进行部分重同步(当前如果与新生成的复制ID相同,且偏移量在缓存区内,同样可以进行部分重同步)。这里需要重新生成一个复制ID的原因就是旧有的复制ID的复制偏移量在执行完slaveof no one后不能在继续增加,否则会导致数据混淆。(masterTryPartialResynchronization)
补充说明
1、Redis的RESP协议https://redis.io/topics/protocol
2、Redis4.0 http://antirez.com/news/110
以上是关于Redis4.0 主从复制(PSYN2.0)的主要内容,如果未能解决你的问题,请参考以下文章