(数据科学学习手札51)用pymysql来操控MySQL数据库
Posted 费弗里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(数据科学学习手札51)用pymysql来操控MySQL数据库相关的知识,希望对你有一定的参考价值。
一、简介
pymysql是Python中专门用来操控MySQL数据库的模块,通过pymysql,可以编写简短的脚本来方便快捷地操控MySQL数据库,本文就将针对pymysql的基本功能进行介绍;
二、操控数据库
2.1 连接数据库
利用pymysql.connect(host,user,password,port,db)来实现对已知MySQL数据库的连接,其中各参数分别对应着目标数据库的各项属性,db用于指定要连接的database的名称,下面是一个示例:
要连接的数据库:
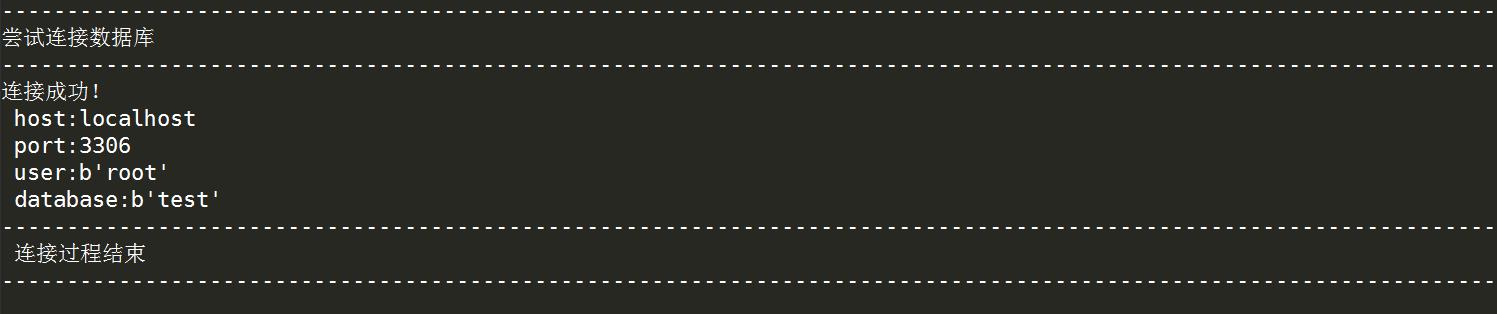
import pymysql \'\'\'连接数据库\'\'\' try: print(\'-\'*200) print(\'尝试连接数据库\') print(\'-\'*200) db = pymysql.connect(host=\'localhost\',user=\'root\',password=\'我的密码\',port=3306,db=\'test\') print(\'连接成功!\',\'\\n\', \'host:{}\'.format(db.host),\'\\n\', \'port:{}\'.format(db.port),\'\\n\', \'user:{}\'.format(db.user),\'\\n\', \'database:{}\'.format(db.db)) except Exception as e: print(\'因{},连接失败\'.format(e)) finally: print(\'-\'*200,\'\\n\',\'连接过程结束\') print(\'-\'*200)
若连接成功,显示如下信息:
2.2 插入数据
在成功连接数据库之后,我们使用db.cursor()来获取数据库的操作游标:
\'\'\'获取操作游标\'\'\' cur = db.cursor()
接下来我们使用.execute()来执行需要完成的SQL语句,其传入参数为字符串类型的SQL语句,譬如,下面的例子中我们创建一个新的表,并将sklearn中内置的鸢尾花数据传入进去:
from sklearn.datasets import load_iris \'\'\'获取鸢尾花数据,其中X,y为二维数组\'\'\' X,y = load_iris(return_X_y=True) \'\'\'建立指定鸢尾花类别名称的列表\'\'\' Species = [\'setosa\',\'versicolor\',\'virginica\'] \'\'\'通过操作游标执行SQL语句,以创建iris表\'\'\' cur.execute("CREATE TABLE IF NOT EXISTS iris" "(Sepal_Length float," "Sepal_Width float," "Petal_Length float," "Petal_Width float,Species char(20)" ")") \'\'\'构造将X,y数据一次性插入iris的SQL语句\'\'\' BaseSQL = "INSERT INTO iris VALUES" for i in range(X.shape[0]): BaseSQL += "({},{},{},{},\'{}\'),".format(X[i,0],X[i,1],X[i,2],X[i,3],Species[y[i]]) \'\'\'去除末尾多余的逗号\'\'\' BaseSQL = BaseSQL[:-1] \'\'\'执行插入鸢尾花数据的SQL语句\'\'\' cur.execute(BaseSQL)
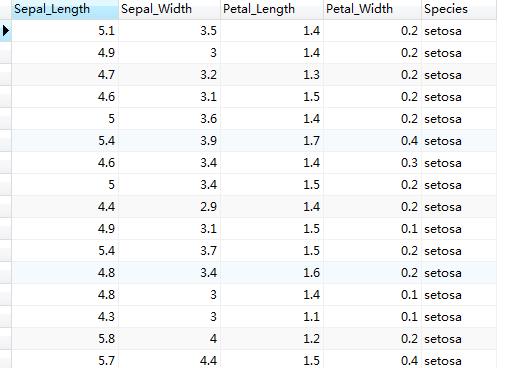
运行完上述语句,在已经连接数据库的navicat中查看iris表中的全部数据:
USE test; SELECT * FROM iris;

这是会发现,查询结果只有一张空表,这是因为在执行完插入数据的语句后,并没有提交结果,使用.commit()向数据库提交结果:
\'\'\'提交结果\'\'\' db.commit()
在navicat中再次查询得到想要的结果:
2.3 查询数据
查询功能是数据库中核心功能之一,查询取数也是数据分析人员在数据库上最常用的操作,在pymysql中想要完成查询取数的过程,要在执行SQL语句之后,对我们的游标对象使用.fetchall()方法来取得对应的查询结果:
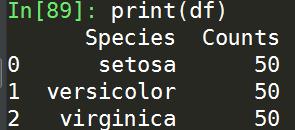
\'\'\'查询取数\'\'\' cur.execute("SELECT Species,COUNT(*) FROM iris GROUP BY Species") \'\'\'获取查询结果\'\'\' results = cur.fetchall() print(results)

可以看到,取回的结果为一个规整的tuple对象,可以按照其格式打印出查询结果:
print(\'Species\',\'|\',\'Counts\') for result in results: print(\'-\'*20) print(result[0],\'|\',result[1]) print(\'-\'*20)

或者转换为其他格式保存为其他规整的格式以便进一步分析:
import pandas as pd df = pd.DataFrame(list(results),columns=[\'Species\',\'Counts\']) print(df)
而关于其他对数据库的操作(如删除、更新等),与上面类似,只是涉及到更改数据库中数据时,不要忘记commit();
2.4 关闭数据库
在完成需要的操作后,不要忘记断开与数据库间的连接:
db.close()
以上就是本文的全部内容,如有笔误,望指出!
以上是关于(数据科学学习手札51)用pymysql来操控MySQL数据库的主要内容,如果未能解决你的问题,请参考以下文章