SQL Server-聚焦使用视图若干限制/建议视图查询性能问题,你懵逼了?(二十五)
Posted Jeffcky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server-聚焦使用视图若干限制/建议视图查询性能问题,你懵逼了?(二十五)相关的知识,希望对你有一定的参考价值。
前言
上一节我们简单讲述了表表达式的4种类型,这一系列我们来讲讲使用视图的限制,简短的内容,深入的理解,Always to review the basics。
避免在视图中使用ORDER BY
上一节我们也讲述了使用表表达式必须满足的3个要求,其中就有一个无法保证顺序,也就是说的ORDER BY的问题,我们还是重点看看在视图中的限制。在常规查询中对于排序我们是这样做的。
USE AdventureWorks2012 GO SELECT * FROM Sales.SalesOrderDetail ORDER BY SalesOrderDetailID DESC

接下来我们在视图中对数据进行排序,我们创建视图来看看
USE AdventureWorks2012 GO IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT * FROM Sales.SalesOrderDetail ORDER BY SalesOrderDetailID DESC GO
此时当我们执行创建视图时会发现如下错误

此时在视图内部不能使用ORDER BY我们创建视图后在外部视图使用ORDER BY看看
USE AdventureWorks2012 GO IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT * FROM Sales.SalesOrderDetail GO SELECT * FROM view_limit ORDER BY SalesOrderDetailID DESC

我们再来看看上述在视图内部进行ORDER BY时出现的错误,它说明可以使用TOP、OFFSET等,接下来我们利用TOP来看看实际结果是怎样的。
USE AdventureWorks2012 GO IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT TOP 100 PERCENT * FROM Sales.SalesOrderDetail ORDER BY SalesOrderDetailID DESC GO
我们再来查询该视图看看返回的结果集
USE AdventureWorks2012 GO SELECT * FROM dbo.view_limit
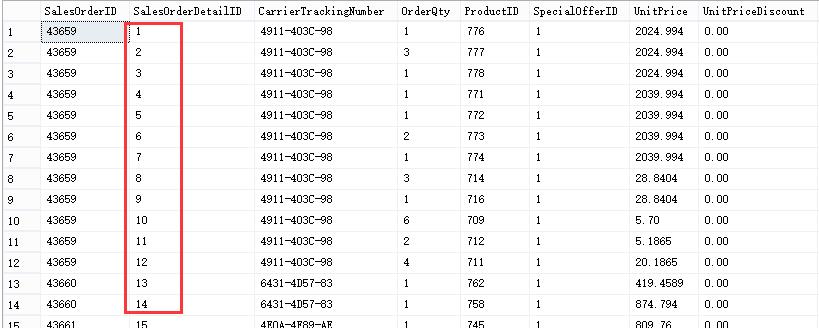

当我们在创建视图时内部使用ORDER BY对结果集进行降序,结果返回的数据压根没有进行降序,同时我们看到查询计划根本没有出现Sort排序操作。我们再来看另外一种情况将返回的数据设置为比100%少一点试试看。
IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT TOP 99.9 PERCENT * FROM Sales.SalesOrderDetail ORDER BY SalesOrderDetailID DESC GO
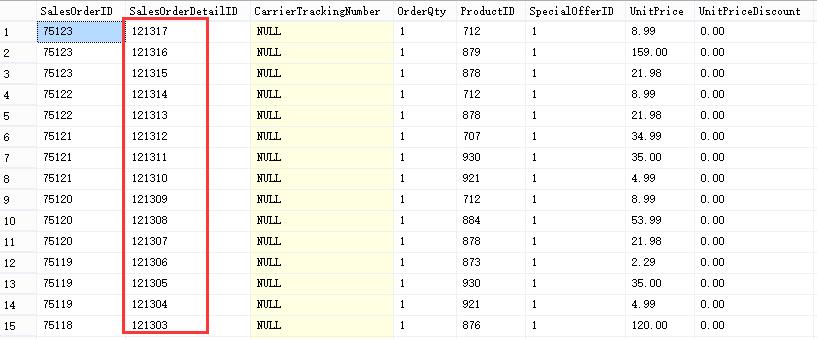
此时则进行了降序排序,说明在视图中利用TOP、OFFSET就好使了呢?上述查询我们没有做任何条件限制,我们查查表中总共有多少数据和利用视图查询时返回有多少数据看看。
USE AdventureWorks2012 GO SELECT COUNT(*) AS originalCount FROM Sales.SalesOrderDetail SELECT COUNT(*) AS viewCount FROM dbo.view_limit

虽然在上述情况下我们限制返回的数据最终也按照降序来进行排序,这是相对于小表而言,如果表中数据量比较大的话,此时通过在视图中进行ORDER BY的话将会缺省很多值,所以建议不要在视图中进行ORDER BY而是在视图外部进行ORDER BY。好了这是我们说的第一种限制,我们给出结论。
(1)避免在视图内部使用ORDER BY,当表数据比较小时虽然通过TOP或OFFSET等能解决问题,但是当数据量比较大时此时在视图内部使用ORDER BY会导致更多的数据行缺失,建议在视图外部进行ORDER BY。
避免在视图中使用SELECT *
首先我们通过创建视图来看问题的出现。
USE AdventureWorks2012 GO IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT * FROM HumanResources.Shift GO
接下来我们通过查找原表和视图的方式来看看返回的数据
USE AdventureWorks2012 GO -- 查找原表 SELECT * FROM HumanResources.[Shift] GO -- 查找视图 SELECT * FROM view_limit GO
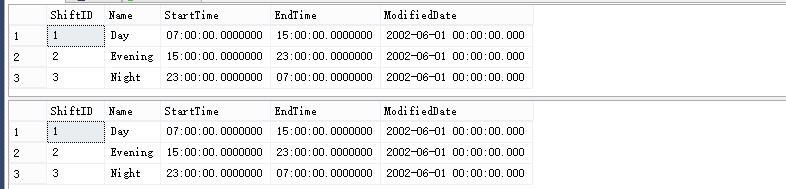
恩,没毛病,接下来我们在表中添加额外列
USE AdventureWorks2012
GO
ALTER TABLE HumanResources.[Shift]
ADD AdditionalCol INT
GO
我们再来进行上述查询,看看返回的结果集
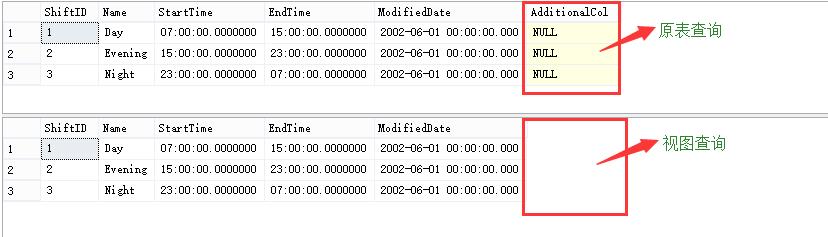
此时我们发现添加额外列后视图并未显示,当然数据也就不会显示了。此时我们在用视图查询之前进行刷新看看
USE AdventureWorks2012 GO -- 查找原表 SELECT * FROM HumanResources.[Shift] GO EXEC sp_refreshview \'view_limit\'
-- 查找视图 SELECT * FROM view_limit GO
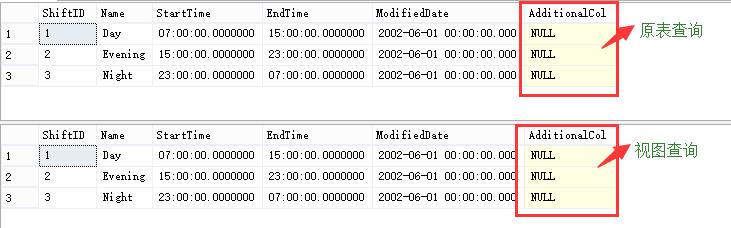
此时才能返回正确的结果。那么是什么原因导致添加额外列通过视图查询会出现意想不到的结果呢,因为视图在编译方式上对列是枚举的,并且新的表列不会自动添加到视图中,也就是说若我们额外添加了列,此时列根本不会添加到视图中,所以此时我们可以通过sp_refreshview或sp_refreshsqlmodule的方式来刷新视图的元数据。所以我们结论如下
(2)避免在视图中使用SELECT *,当表中添加额外列后会导致视图中不会自动进行添加,虽然我们可以通过sp_refreshview或sp_refreshmodule的方式来刷新视图,但是为了避免混淆,最好是在视图定义中显式列出所需要的列的名称,若添加了额外列,同时在视图中我们需要额外列的话,我们通过ALTER VIEW的方式来修改视图定义即可。
视图查询返回额外列通过JOIN表导致查询性能低效
下面我们直接通过例子进行演示。
IF EXISTS (SELECT * FROM sys.views WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[view_limit]\')) DROP VIEW [dbo].[view_limit] GO CREATE VIEW view_limit AS SELECT [SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber] ,[OrderQty],sod.[ProductID],[SpecialOfferID],[UnitPrice],[UnitPriceDiscount] ,[LineTotal],[ReferenceOrderID] FROM Sales.SalesOrderDetail sod INNER JOIN Production.TransactionHistory th ON sod.SalesOrderID = th.ReferenceOrderID GO
解下来我们进行常规SQL查询和视图查询
USE AdventureWorks2012 GO SELECT * FROM dbo.view_limit WHERE SalesOrderDetailID > 111111 GO SELECT [SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber] ,[OrderQty],sod.[ProductID],[SpecialOfferID],[UnitPrice],[UnitPriceDiscount] ,[LineTotal],[ReferenceOrderID] FROM Sales.SalesOrderDetail sod INNER JOIN Production.TransactionHistory th ON sod.SalesOrderID = th.ReferenceOrderID WHERE SalesOrderDetailID > 111111 GO
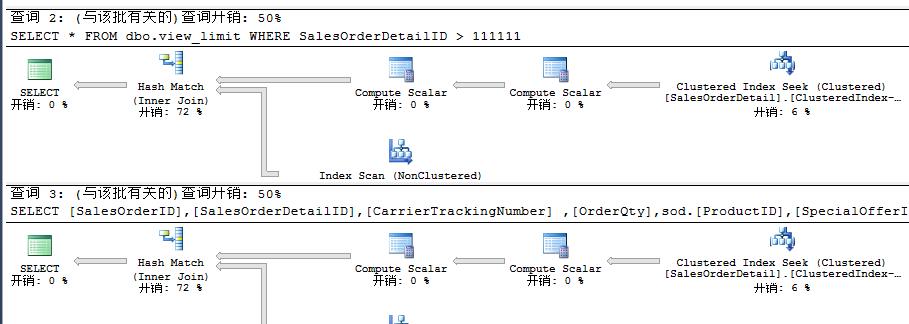
上述利用常规查询和视图查询开销样,但是现在我们有这样一个场景上述视图是被其他同事所写,但是当我们用时还需要返回额外其他列,所以为了不返回其他多余的数据而和同事撕逼,我们需要再次在视图外部进行JOIN来得到我们额外的列,我们下面来看看。
USE AdventureWorks2012 GO SELECT v1.* ,th.[Quantity] FROM dbo.view_limit v1 INNER JOIN Production.TransactionHistory th ON v1.SalesOrderID = th.ReferenceOrderID WHERE SalesOrderDetailID > 111111 GO SELECT [SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber] ,[OrderQty],sod.[ProductID],[SpecialOfferID],[UnitPrice],[UnitPriceDiscount] ,[LineTotal],[ReferenceOrderID] ,th.[Quantity] FROM Sales.SalesOrderDetail sod INNER JOIN Production.TransactionHistory th ON sod.SalesOrderID = th.ReferenceOrderID WHERE SalesOrderDetailID > 111111 GO
此时额外返回了Quantity列对视图再次进行JOIN,我们看看查询计划开销

此时发现利用视图查询开销更多,而常规查询不过是多添加一个列而已没有任何改变。我们继续往下看
默认情况下在视图上创建索引无效
我们在前面一直讨论过关于索引的建立的问题,而且索引都是建立在表上,那么我们将索引建立在视图上情况是怎样的呢,是不是查询效率会得到提升呢?我们首先创建测试表并插入数据
USE AdventureWorks2012 GO IF EXISTS (SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N\'[dbo].[ViewTable]\') AND TYPE IN (N\'U\')) DROP TABLE [dbo].[ViewTable] GO CREATE TABLE ViewTable (ID1 INT, ID2 INT, SomeData VARCHAR(100))
INSERT INTO ViewTable (ID1,ID2,SomeData) SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY o1.name), ROW_NUMBER() OVER (ORDER BY o2.name), o2.name FROM sys.all_objects o1 CROSS JOIN sys.all_objects o2 GO
上述我们创建了测试的视图表ViewTable并插入了10万条测试数据,接下来我们对表建立索引。
USE AdventureWorks2012
GO
CREATE UNIQUE CLUSTERED INDEX [idx_original_table] ON dbo.ViewTable
(
ID1 ASC
)
接下来我们来创建视图并在视图上创建索引
USE AdventureWorks2012
GO
CREATE VIEW ViewLimit
WITH SCHEMABINDING
AS
SELECT ID1,ID2,SomeData
FROM dbo.ViewTable
GO
CREATE UNIQUE CLUSTERED INDEX [idx_view_table] ON [dbo].[ViewLimit]
(
ID2 ASC
)
GO
上述我们需要注意,当在视图上创建索引时必须指定WITH SCHAMABINDING,否则不允许在视图上创建索引。我们最后通过常规查询和视图查询来看看查询计划情况
USE AdventureWorks2012
GO
SELECT ID1,ID2,SomeData
FROM dbo.ViewTable
GO
SELECT ID1,ID2,SomeData
FROM dbo.ViewLimit
GO
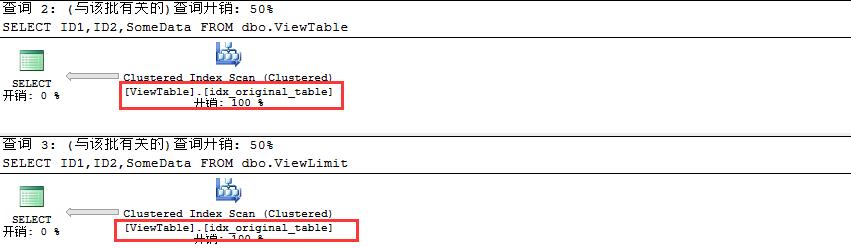
此时我们发现视图查询利用的索引不是我们创建的索引idx_view_table,主要原因是因为视图和表是关联的,所以查询计划决定在表上的索引比在视图上创建的索引更加高效。 当我们在WITH中强制指定noexpand此时将会执行在视图上创建的索引,因为此时视图已经和原始表没有关系,它是独立的,如下:
USE AdventureWorks2012
GO
SELECT ID1,ID2,SomeData
FROM dbo.ViewTable
GO
SELECT ID1,ID2,SomeData
FROM dbo.ViewLimit
WITH(NOEXPAND)
GO
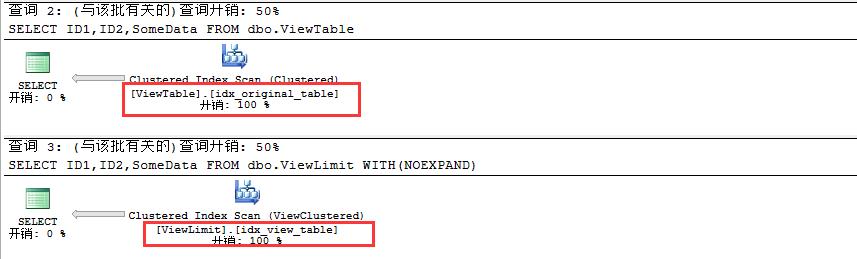
在视图上创建索引这个问题比较复杂,我们就不讨论了,一般通过常规查询都能解决的问题何必劳驾视图呢。这个我们需要注意一下就行。
总结
本节我们讲了几个使用视图时的限制以及建议等问题,下节我们还是会讨论使用视图的其他限制,简短的内容,深入的理解,我们下节再会。
以上是关于SQL Server-聚焦使用视图若干限制/建议视图查询性能问题,你懵逼了?(二十五)的主要内容,如果未能解决你的问题,请参考以下文章