mysql对库,表,数据类型的操作以及完整性约束
Posted 欢迎来到七寸空间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql对库,表,数据类型的操作以及完整性约束相关的知识,希望对你有一定的参考价值。
一丶对库的操作
求救语法: help create database;
1.创建数据库
CREATE DATABASE 数据库名 charset utf8;
2.数据库的命名规则:


可以由字母、数字、下划线、@、#、$ 区分大小写 唯一性 不能使用关键字如 create select 不能单独使用数字 最长128位 # 基本上跟python或者js的命名规则一样
3.数据库的相关操作:
#查看数据库 show databases; #查看当前库 show create database db1; #查看所在的库 select database(); #选择数据库 use 数据库名 #删除数据库 DROP DATABASE 数据库名; # 修改数据库 alter database db1 charset utf8;
4.了解内容
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型: 1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER 2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT 3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
二丶对表的操作
1.存储引擎(了解)
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎.
mysql> show engines\\G;# 查看所有支持的引擎 mysql> show variables like \'storage_engine%\'; # 查看正在使用的存储引擎
1、InnoDB 存储引擎 支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其 特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。 InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。 InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。 对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。 InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。 2、MyISAM 存储引擎 不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 3、NDB 存储引擎 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。 4、Memory 存储引擎 正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。 5、Infobright 存储引擎 第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。 6、NTSE 存储引擎 网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。 7、BLACKHOLE 黑洞存储引擎,可以应用于主备复制中的分发主库。 MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
2.表的操作
语法:
create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的
1.创建数据库
create database db2 charset utf8;
2.使用数据库
use db2;
3.创建a1表:
create table a1( id int, name varchar(50), age int(3) );
4.插入表的记录
insert into a1 values (1,\'mjj\',18), (2,\'wusir\',28);
5.查看表的数据和结构
(1)查询a1表中的存储数据
select * from a1;
(2)查看a1表的结构
desc a1;
(3)查看表的详细结构
show create table a1\\G;
6.复制表
(1)新创建一个数据库db3
create database db3 charset utf8;
(2)使用db3
use db3
(3)复制db2.a1的表结构和记录
create table b1 select * from db2.a1;
(4)查看db3.b1中的数据和表结构
select * from db3.b1;
还有一种做法,使用like(只拷贝表结构,不拷贝记录)
create table b3 like db2.a1; desc b3; select * from db3.b3;
7.删除表
drop table 表名;
三丶数据类型
http://www.runoob.com/mysql/mysql-data-types.html
mysql常用数据类型概况:
#1. 数字: 整型:tinyint int bigint 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) 精准 内部原理是以字符串形式去存 #2. 字符串: char(10):简单粗暴,浪费空间,存取速度快 root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。 #3. 时间类型: 最常用:datetime #4. 枚举类型与集合类型 enum 和set
1.数值类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等
======================================== tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号: ~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 ======================================== int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: ~ 4294967295 ======================================== bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: ~ 18446744073709551615
2.浮点型
定点数类型: DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等
语法:
-------------------------FLOAT------------------- FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释:单精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 #无符号: 1.175494351E-38 to 3.402823466E+38 #精确度: **** 随着小数的增多,精度变得不准确 **** -------------------------DOUBLE----------------------- DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释: 双精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 #无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 #精确度: ****随着小数的增多,精度比float要高,但也会变得不准确 **** ====================================== --------------------DECIMAL------------------------ decimal[(m[,d])] [unsigned] [zerofill] #参数解释:准确的小数值,M是整数部分总个数(负号不算),D是小数点后个数。 M最大值为65,D最大值为30。 #精确度: **** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。
3.日期类型
DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
语法: YEAR YYYY(1901/2155) DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS(\'-838:59:59\'/\'838:59:59\') DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
datetime与timestamp的区别
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。 下面就来总结一下两种日期类型的区别。 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器, 操作系统以及客户端连接都有时区的设置。 3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。 4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP), 如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
注意:
============注意啦,注意啦,注意啦=========== #1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 #2. 插入年份时,尽量使用4位值 #3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 create table t12(y year); insert into t12 values (50),(71); select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+
练习:创建一张学生表(student),要求有id,姓名,出生年份,出生的年月日,进班的时间,以及来学习的具体时间
mysql> create table student( -> id int, -> name varchar(20), -> born_year year, -> birth date, -> class_time time, -> reg_time datetime -> ); Query OK, 0 rows affected (0.02 sec) mysql> insert into student values -> (1,\'alex\',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"), -> (2,\'egon\',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"), -> (3,\'wsb\',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13"); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from student; +------+------+-----------+------------+------------+---------------------+ | id | name | born_year | birth | class_time | reg_time | +------+------+-----------+------------+------------+---------------------+ | 1 | alex | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 | | 2 | egon | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 | | 3 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 | +------+------+-----------+------------+------------+---------------------+ rows in set (0.00 sec)
4.字符类型
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html #注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(设置SQL模式:SET sql_mode = \'PAD_CHAR_TO_FULL_LENGTH\'; 查询sql的默认模式:select @@sql_mode;) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果\'ab \',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
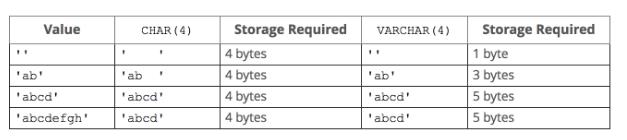
(1)char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形。
# 创建t1表,分别指明字段x为char类型,字段y为varchar类型 mysql> create table t1(x char(5),y varchar(4)); Query OK, 0 rows affected (0.16 sec) # char存放的是5个字符,而varchar存4个字符 mysql> insert into t1 values(\'你瞅啥 \',\'你瞅啥 \'); Query OK, 1 row affected (0.01 sec) # 在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少 mysql> select x,char_length(x),y,char_length(y) from t1; +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 你瞅啥 | 3 | 你瞅啥 | 4 | +-----------+----------------+------------+----------------+ row in set (0.02 sec) #略施小计,让char现原形 mysql> SET sql_mode = \'PAD_CHAR_TO_FULL_LENGTH\'; Query OK, 0 rows affected (0.00 sec) #查看当前mysql的mode模式 mysql> select @@sql_mode; +-------------------------+ | @@sql_mode | +-------------------------+ | PAD_CHAR_TO_FULL_LENGTH | +-------------------------+ row in mysql表操作之修改