kube-batch--简介
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kube-batch--简介相关的知识,希望对你有一定的参考价值。
参考技术A K8s本身的调度器具有一些缺陷:(1) 默认的调度器是以 pod 为粒度的,对机器学习任务很不利。
(2)默认的调度器无法提供队列调度的功能
Kube-batch 目前是 Kubernetes SIGs 旗下的一个孵化项目,是一个运行在 Kubernetes 上面向机器学习 / 大数据 /HPC 的批调度器(batch scheduler)。kubeflow中gang scheduler的实现就使用的是kube-batch.
"Batch" scheduling
Resource sharing between multi-tenant
(1)PodGroup
简单理解:一个PodGroup就是一个job中的所有Pod
(2)PodGroup
简单理解:一个PodGroup就是一个job中的所有Pod
Reclaim: 回收
Allocate: 分配
Backfill: 回填
Preempt: 抢占
Drf:维护了集群资源使用情况
Gang:实现了batch调度的一个核心逻辑,只有满足数量要求的PodGroup,才可
以调度
Predicates:注册预选函数
Priority:job优先级
Kube-batch 的基本流程如下图,它通过 list-watch 监听 Pod, Queue, PodGroup 和 Node 等资源,在本地维护一份集群资源的全局缓存,依次通过如下的策略(reclaim, allocate, preemption,predict) 完成资源的调度。
(1) Kube-batch向集群注册自己定义的Action和插件
(2) list-watch 监听 Pod, Queue, PodGroup 和 Node 等资源,在本地维护一份集群资源的全局缓存
(3) 间隔一秒,执行调度,开启会话
(4) 执行Action
(1)Kube-batch如何Gang-Scheduler
a. 增加一个PodGruop的CRD。调度以PodGroup为单位。同时对应还有一个PodGroupController进行PodGroup的管理
b. 整个调度过程采用延迟创建Pod的过程。只有当PodGroup中的所有Pod都有合适的Node绑定时,才开始创建
c. 定义了一种新的Action-BackFill.当PodGroup还有Pod没绑定时,之前绑定Pod的资源会释放。
(2) Kube-batch如何共享多租户资源
a. 多租户的实现:Queue + Namespace
b. 租户间资源的共享:每个租户对应一个Namespace,以及一个Queue.每个Namespace的资源是按比例分配的。
优点:
Gang Scheduler 的调度方式
多租户的设计思想
缺点:
和默认的调度器冲突
没有优选就没有soft亲和性
目前还是孵化项目,文档不全面,特别是多租户这块,没有实例以及文档
HA简介以及HBase简介
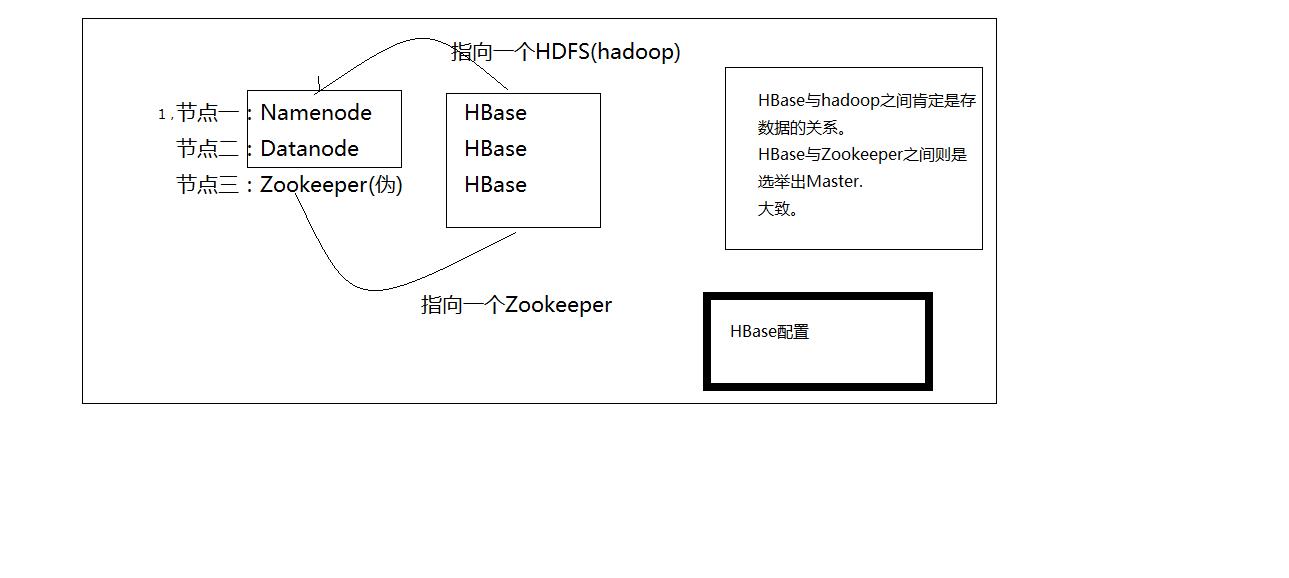
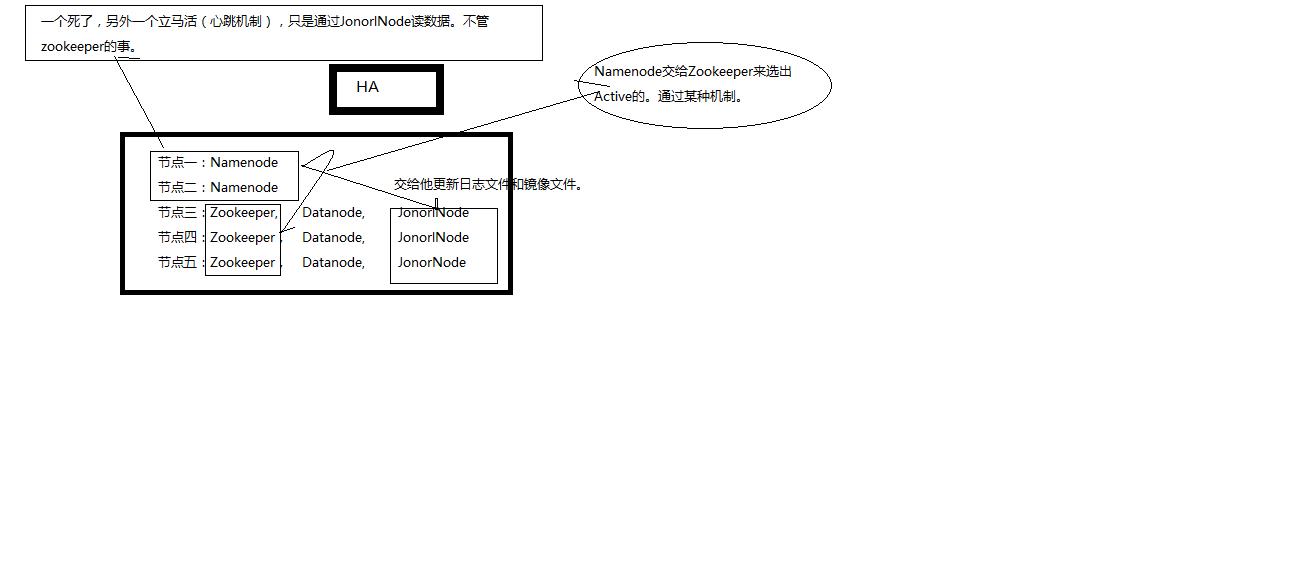
HBase基础知识:
一,HMater节点:可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
1,为Region server 分配region,2,负责region server 的负载均衡,3,发现失效的region server 并重新分配其上的region.
二,Region Server节点:
维护Master 分配给它的region,处理对这些region 的IO 请求。
负责切分在运行过程中变得过大的region、
三,Client:
HBase Client通过RPC方式和HMaster、HRegionServer通信;一个HRegionServer可以存放1000个HRegion;底层Table数据存储于HDFS中,而HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化;数据本地化并不是总能实现,比如在HRegion移动(如因Split)时,需要等下一次Compact才能继续回到本地化。
四,Zookeeper
Zookeeper Quorum存储-ROOT-表地址、HMaster地址
HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
Zookeeper避免HMaster单点问题
//http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html 这篇博客讲的比较详细。
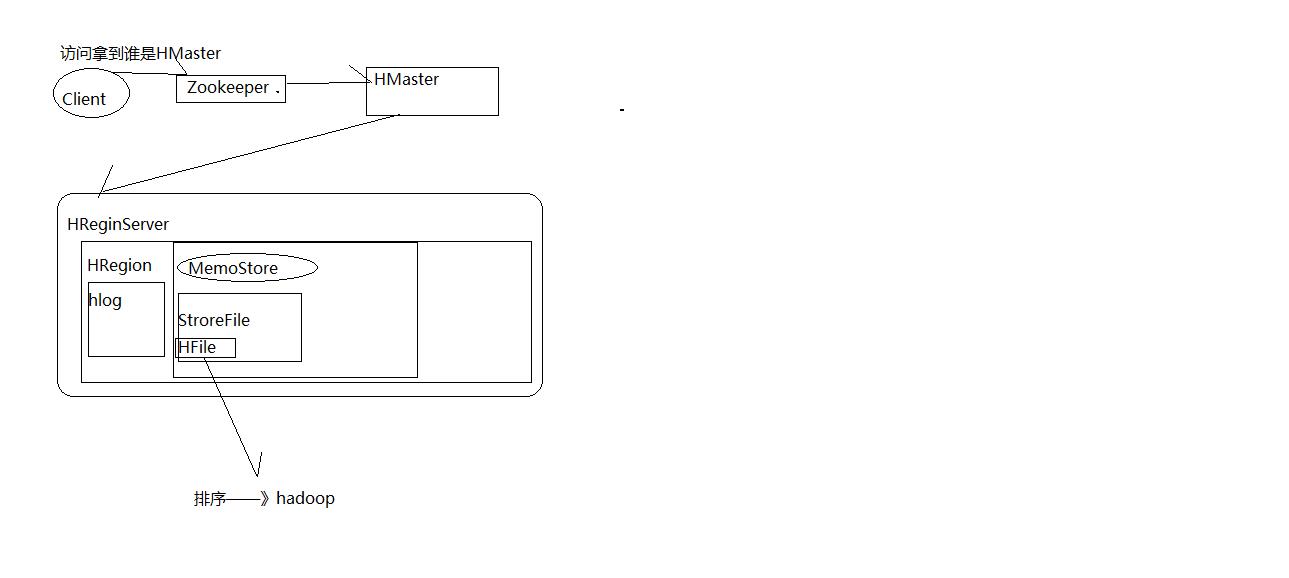
HBase:客户端有很多代码,可以远程访问ReginServer,Zookeeper。当在客户端创建一个表的时候,肯定就已经连上了一个ReginServer这样在这个节点上的Regin上直接占地方了,然后在往里写数据。客户端的另外的进程监视创建表,往.meta文件里写记录。Master怎么向ReginServer分配Regin估计是Reginserver通过Zookeeper注册,然后Master通过Zookeeper了解Reginserver的情况,然后给Reginserver分配资源。这种资源估计是只是一种数字而已。具体资源还得看Reginserver端的资源配置。
HBase有两张特殊的Table,-Root-和.META.
-Root-:记录了.META.表的Regin信息,-Root只有一个。
.META.:记录了用户创建的表的Regin信息,.META记录了多个region
Zookeeper中记录了-root-表的位置
Client访问用户数据之前需要首先访问Zookeeper,访问-ROOT-表。所以需要知道管理-ROOT-表的RegionServer的地址。这个地址被存在ZooKeeper中。默认的路径是:/hbase/root-region-server 。然后访问-root-表,接着访问.meta表,最后找到用户数据的位置去访问。
http://blog.csdn.net/chlaws/article/details/16918913
-ROOT-和.META.表结构
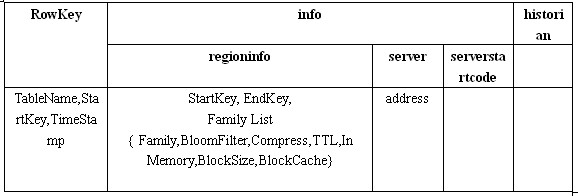
到目前为止我们已经学习了必须的背景知识,下面我们要正式开始介绍Client端寻找RegionServer的整个过程。我打算用一个假想的例子来学习这个过程,因此我先构建了假想的-ROOT-表和.META.表。
我们先来看.META.表,假设HBase中只有两张用户表:Table1和Table2,Table1非常大,被划分成了很多Region,因此在.META.表中有很多条Row用来记录这些Region。而Table2很小,只是被划分成了两个Region,因此在.META.中只有两条Row用来记录。这个表的内容看上去是这个样子的:
.META.行记录结构

假设.META.表被分成了两个Region,那么-ROOT-的内容看上去大概是这个样子的:
-ROOT-行记录结构


以上是关于kube-batch--简介的主要内容,如果未能解决你的问题,请参考以下文章
0-Volcano是什么,和 kube-batch与kubeflow是什么关系