spark-sql执行流程分析
Posted ulysses_you
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark-sql执行流程分析相关的知识,希望对你有一定的参考价值。
spark-sql 架构
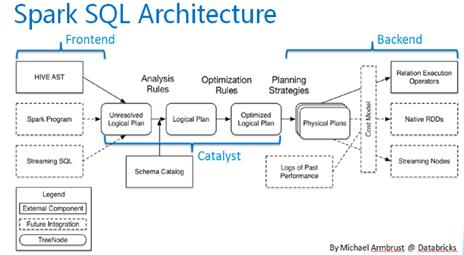
图1
图1是sparksql的执行架构,主要包括逻辑计划和物理计划几个阶段,下面对流程详细分析。
sql执行流程
总体流程
- parser;基于antlr框架对 sql解析,生成抽象语法树
- 变量替换,通过正则表达式找出符合规则的字符串,替换成系统缓存环境的变量
SQLConf中的`spark.sql.variable.substitute`,默认是可用的;参考` SparkSqlParser`
- parser;将antlr的tree转成spark catalyst的LogicPlan也就是unresolve logical plan;详细参考`AstBuild`, `ParseDriver`
- analyzer;通过分析器,结合catalog,把logical plan和实际的数据绑定起来,将unresolve logical plan生成 logical plan;详细参考`QureyExecution`
- 缓存替换,通过CacheManager,替换有相同结果的logical plan
- logical plan优化,基于规则的优化;优化规则参考Optimizer,优化执行器RuleExecutor
- 生成spark plan,也就是物理计划;参考`QueryPlanner`和`SparkStrategies`
- spark plan准备阶段
- 构造RDD执行,涉及spark的wholeStageCodegenExec机制,基于janino框架生成java代码并编译
其中`SessionState`类中维护了所有参与sql执行流程的实例对象,`QueryExecution`类则是实际处理SQL执行逻辑的类。需要注意的是,除了第1步,第2步和第3步是立即执行的,这是由于需要判断sql的合法性以及当前catalog环境下是否存在sql中的库表结构等,其他步骤都是在触发spark action的时候才被执行,也就是lazy加载。下面对整个流程的细节进行分析。
详细分析
变量替换
spark-sql通过正则匹配,将sql中的系统变量,环境变量等配置替换成真正的value,目前支持替换spark的配置和hive的配置
例如:
session.conf.set("spark.sql.test.key","1")
session.sql("select * from test where 1 =
${sparkconf:spark.sql.test.key}")
抽象语法树AST
先上一下wiki的解释,AST是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。说的可能有点抽象,翻译出来就是说把一个语言表达式的语法结构转换成树形结构,那这颗数就是抽象语法树。
举个例子,`1*2+3`这个表达式转成AST,如图2。

图2
SQL作为一种独立的语言,有自己的表达式,所以用AST作为对其语法进行分析是很灵活的。这里Spark选用的是anltr作为AST的构建框架,而不是hive用的calcite框架,antlr相比calcite更轻量,只涉及sql语法解析,这也便于spark自己在后续步骤做自己的sql执行定制化优化。
unresolve logical plan
spark通过visit antlr框架生成的AST,转换成unresolve LogicPlan,LogicPlan其实是spark定义的AST
分析器
spark所有的规则优化都是基于模式匹配来完成的。分析器这个步骤的主要工作是,基于catalog,完成对logical plan的resolve化。
是否resolved来源两个指标,1. 子节点是否resolved;2. 输入的数据类型是否满足要求,比如要求输入int类型,实际输入的string类型,那么就不满足要求。参考类`Expression`,`Analyzer`。
logical plan
常见的优化规则,下面列举部分:
移除group下的常量,对应` RemoveLiteralFromGroupExpressions`
移除重复的group表达式,对应` RemoveRepetitionFromGroupExpressions`
谓语下推,在进行其他操作之前,先进行Filter操作。当然这有很多条件限制,比如子查询中没有和父查询相同的条件字段,如果有那么下推会造成冲突
裁剪Filter操作,如果操作总是为True,那么移除,如果操作总是为False,那么用空替换
spark plan
结合LogicPlan和Strategy,将AST转换成实际执行的算子,参考`SparkPlanner`,内置了几个strategies。生成SparkPlan后,继续采用规则匹配的方式优化,其中就包括了著名的wholeStageCodegenExec机制,这个机制默认是开启的,`spark.sql.codegen.wholeStage`。
参考资料
以上是关于spark-sql执行流程分析的主要内容,如果未能解决你的问题,请参考以下文章