数据库Mysql中主键的几种表设计组合的实际应用效果
Posted 张泰峰的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库Mysql中主键的几种表设计组合的实际应用效果相关的知识,希望对你有一定的参考价值。
写在前面
前前后后忙忙碌碌,度过了新工作的三个月。博客许久未新,似乎对忙碌没有一点点防备。总结下来三个月不断的磨砺自己,努力从独乐乐转变到众乐乐,体会到不一样的是,连办公室的新玩意都能引起莫名的兴趣了,作为一只忙碌的 “猿” 倒不知正常与否。
咳咳, 正题, 今天要写一篇关于mysql的主键、索引的文章,mysql的研究博主进行还不够深入,今天讨论的主题主要是,主键对增删改查的具体影响是什么? 博主将用具体的实验说明。
如果你不了解主键,你可以先看看下面的小节,否则你可以直接跳转到实验步骤
了解主键、外键、索引
主键
主键的主要作用是保证表的完整、保证表数据行的唯一性质,
① 业务主键(自然主键):在数据库表中把具有业务逻辑含义的字段作为主键,称为“自然主键(Natural Key)”。
自然主键的含义就是原始数据中存在的不重复字段,直接使用成为主键字段。 这种方式对业务的耦合太强,一般不会使用。
② 逻辑主键(代理主键):在数据库表中采用一个与当前表中逻辑信息无关的字段作为其主键,称为“代理主键”。
逻辑主键提供了一个与当前表数据逻辑无关的字段作为主键,逻辑主键被广泛使用在业务表、数据表,一般有几种生成方式:uuid、自增。其中使用最多的是自增,逻辑主键成功的避免了主键与数据表关联耦合的问题,与业务主键不同的是,业务主键的数据一旦发生更改,那么那个系统中关于主键的所有信息都需要连带修改,这是不可避免的,并且这个更改是随业务需求的增量而不断的增加、膨胀。而逻辑主键与应用耦合度低,它与数据无任何必要的关系,你可以只关心:第一条数据; 而不用关心: 名字是a的那条数据。 某一天名字改成b, 你还是只关心:第一条数据。
业务的更改几乎是不可避免的,前期任何产品经理言之凿凿的不修改论调都是不可靠、不切实际的。我们必须考虑主键数据在更改的情况下,数据能否平稳度过危机。
② 复合主键(联合主键):通过两个或者多个字段的组合作为主键。
复合主键可以说是业务主键的升级版本,通常一个业务字段不能够确定一条数据的唯一性,例如 张三的身份证是34123322, 张三这种大众名称100%会出现重复。我们可以用姓名 + 身份证的方式表示主键,声明一个唯一的记录。
有时候,复合主键是复杂的。 姓名+身份证 不一定能表示不重复,虽然身份证在17年消除了重复的问题,但是之前的数据呢? 可能我们需要新增一个地址作为联合主键,例如 姓名 + 身份证 + 联系地址确认一个人的身份。在其他的业务中,例如访问控制,用户 + 终端 + 终端类型 + 站点 + 页面 + 时间,可能六个字段的联合才能够去确定一个字段的唯一性,这另复杂度陡升。
另外如果其他表要与该表关联则需要引用复合主键的所有字段,这就不单纯是性能问题了,还有存储空间的问题了,当然你也可以认为这是合理的数据冗余,方便查询,但是感觉有点得不偿失。
使用复合主键的原因可能是:对于关系表来说必须关联两个实体表的主键,才能表示它们之间的关系,那么可以把这两个主键联合组成复合主键即可。
如果两个实体存在多个关系,可以再加一个顺序字段联合组成复合主键,但是这样就会引入业务主键的弊端。当然也可以另外对这个关系表添加一个逻辑主键,避免了业务主键的弊端,同时也方便其他表对它的引用。
外键
外键是一种约束,表与表的关联约束,例如a表依赖关联b表的某个字段,你可以设置a表字段外键关联到b表的字段,将两张表强制关联起来,这时候产生两个效果
① 表 b 无法被删除,你必须先删除a表
② 新增的数据必须与表b某行关联
这对某些需要强耦合的业务操作来说很有必要,但、 要强调但是,外键约束我认为,不可滥用,没有合适的理由支撑它的使用的话,将导致业务强制耦合。另外对开发人员不够友好。使用外键一定不能超过3表相互。否则将引出很多的麻烦而不得不取消外键。
索引
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。
如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。其中MySQL中的索引的存储类型有两种BTREE、HASH。 也就是用树或者Hash值来存储该字段,要知道其中详细是如何查找的,就需要会算法的知识了。我们现在只需要知道索引的作用,功能是什么就行。
优点:
1、所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
2、大大加快数据的查询速度
缺点:
1、创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
2、索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
3、当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
使用原则:
索引需要合理的使用。
1、对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
2、数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
3、在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引。
测试主键的影响力
为了说明业务主键、逻辑主键、复合主键对数据表的影响力,博主使用java生成四组测试数据,首先准备表结构为:
`id` int(10) UNSIGNED NOT NULL AUTO_INCREMENT, -- 自增 `dt` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, -- 使用uuid模拟不同的id `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, -- 随机名称 `age` int(10) NULL DEFAULT NULL, -- 随机数生成年龄 `key` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, -- 唯一标识 使用uuid测试 PRIMARY KEY (`id`) USING BTREE -- 设置主键
将生成四组千万条的数据:
1. 自增主键 test_primary_a
2. 自增主键 有索引 test_primary_d
3. 无主键 无索引 test_primary_b
4. 复合主键 无索引 test_primary_c
使用java, spring boot + mybatis每次批量一万条数据,插入一千次,记录每次插入时间,总插入时间:
mybatis代码:
<insert id="insertTestData"> insert into test_primary_${code} ( `dt`, `name`, `age`, `key` ) values <foreach collection="items" item="item" index= "index" separator =","> ( #{item.dt}, #{item.name}, #{item.age}, #{item.key} ) </foreach>
java代码,使用了mybatis插件提供的事务处理:
@Transactional(readOnly = false) public Object testPrimary (String type) { HashMap result = new HashMap(); // 记录总耗时 开始时间 long start = new Date().getTime(); // 记录总耗时 插入条数 int len = 0; try{ String[] names = {"赵一", "钱二", "张三" , "李四", "王五", "宋六", "陈七", "孙八", "欧阳九" , "徐10"}; for (int w = 0; w < 1000; w++) { // 记录万条耗时 long startMil = new Date().getTime(); ArrayList<HashMap> items = new ArrayList<>(); for (int i = 0; i < 10000; i++) { String dt = StringUtils.uuid(); String key = StringUtils.uuid(); int age = (int)((Math.random() * 9 + 1) * 10); // 随机两位 String name = names[(int)(Math.random() * 9 + 1)]; HashMap item = new HashMap<>(); item.put("dt", dt); item.put("key", key); item.put("age", age); item.put("name", name); items.add(item); } len += tspTagbodyMapper.insertTestData(items, type); long endMil = new Date().getTime(); // 万条最终耗时 result.put(w, endMil - startMil); } long end = new Date().getTime(); // 总耗时 result.put("all", end - start); result.put("len", len); return result; } catch (Exception e) { System.out.println(e.toString()); result.put("e", e.toString()); } return result; }
最终生成的数据表情况:
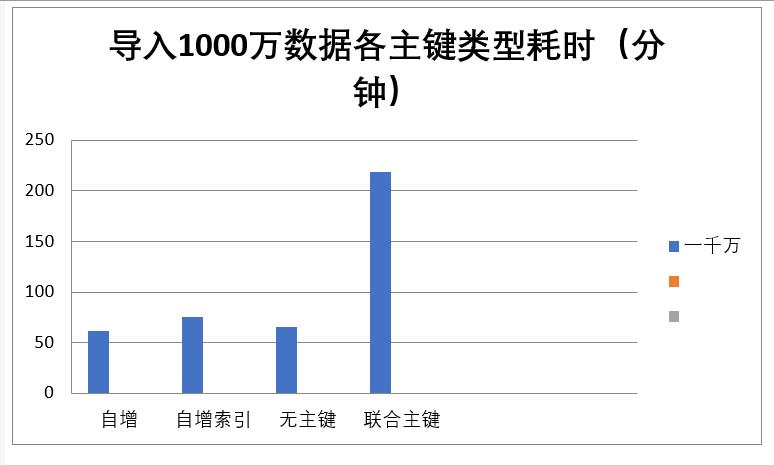
1. 自增主键 test_primary_a ---------- 数据长度 960MB
62分钟插入一千万条数据 平均一万条数据插入 4秒
2. 自增主键 有索引 test_primary_d 数据长度 1GB 索引长度 1.36GB
75分钟插入一千万条数据 平均一万条数据插入 4.5秒
3. 无主键 无索引 test_primary_b ----------- 数据长度 960MB
65分钟插入一千万条数据 平均一万条数据插入 4.2秒
4. 复合主键 无索引 test_primary_c ----------- 数据长度 1.54GB
219分钟插入一千万条数据 平均一万条数据插入 8秒, 这里有一个问题, 复合主键的数据插入耗时是线性增长的,当数据小于100万 插入时常在五秒左右, 当数据变大,插入时长无限变大,在1000万条数据时,平均插入一万数据秒数已经达到15秒了。
查询速度
注意索引的建立时以name字段为开头,索引的生效第一个条件必须是name
简单查询:
select name,age from test_primary_a where age=20 -- 自增主键 无索引 结果条数11万 平均3.5秒
select name,age from test_primary_a where name=\'张三\' and age=20 -- 自增主键 有索引 结果条数11万 平均650豪秒
select name,age from test_primary_b where age=20 -- 无主键 无索引 结果条数11万 平均7秒
select name,age from test_primary_c where age=20 -- 联合主键 无索引 结果条数11万 平均4.5秒
稍复杂条件:
select name,age,`key`,dt from test_primary_a where age=20 and (name=\'王五\' or name = \'张三\') and dt like \'%abc%\' -- 自增主键 无索引 结果条数198 平均4.2秒
select dt,name,age,`key` from test_primary_d where (name=\'王五\' or name = \'张三\') and age=20 and dt like \'%abc%\' -- 自增主键 有索引 结果条数204 平均650豪秒
select name,age,`key`,dt from test_primary_d where age=20 and (name=\'王五\' or name = \'张三\') and dt like \'%abc%\' -- 无主键 无索引 结果条数194 平均5.9秒
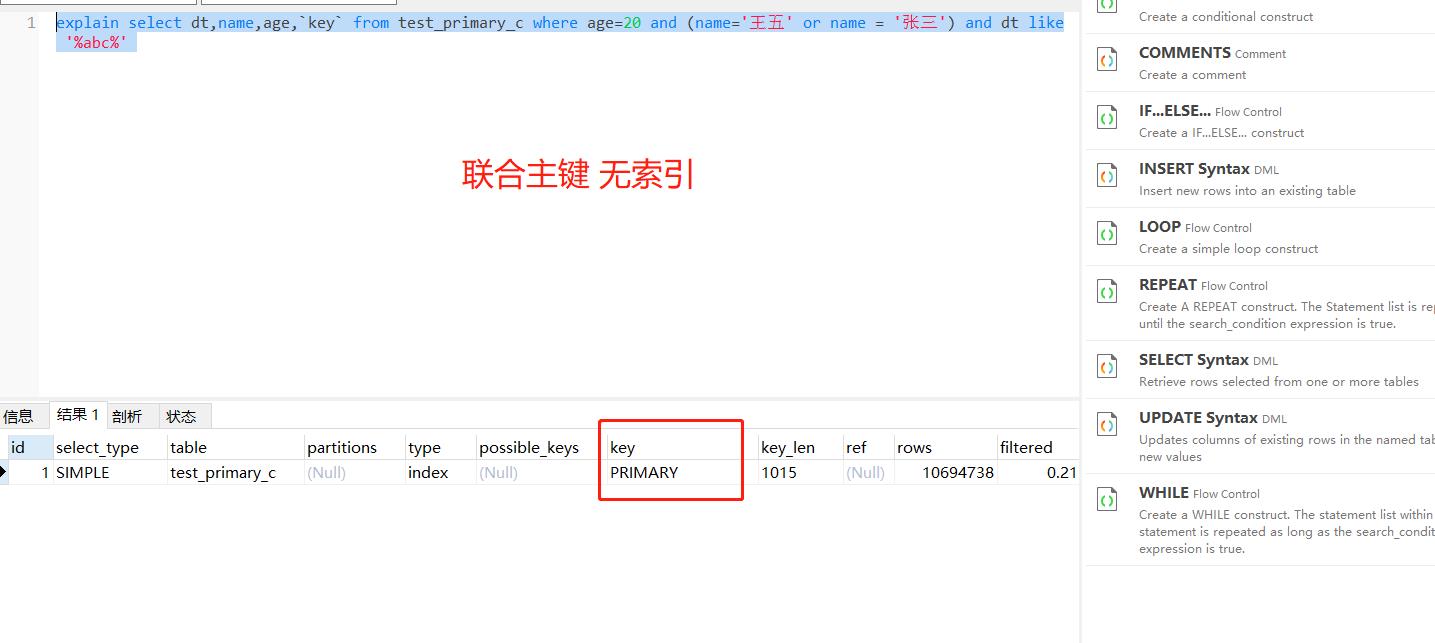
select name,age,`key`,dt from test_primary_c where age=20 and (name=\'王五\' or name = \'张三\') and dt like \'%abc%\' -- 联合主键 无索引 结果条数11万 平均5秒
这样的语句更夸张一点:
select name,age,dt from test_primary_c where dt like \'%0000%\' and name=\'张三\' -- 联合主键 无索引 结果条数359 平均8秒
select name,age,dt from test_primary_c where dt like \'%0000%\' and name=\'张三\' -- 自增主键 有索引 结果条数400 平均1秒

初步结论
从实际应用中可以看出:用各主键的对比,在导入速度上,在前期百万数据时,各表表现一致,在百万数据以后,复合主键的新增时长将线性增长,应该是因为每一条新增都需要判断是否重复,而数据量一旦增大,每次新增都需要全表筛查。
另外一点,逻辑主键 + 索引的方式占用空间一共2.4G, 复合主键占用1.54G 相差大约1个G , 但是实际查询效果看起来索引更胜一筹,只要查询方法得当,索引应该是当前的首选。
最后,关于复合主键的作用? 我想应该是在业务主键字段不超过2-3个的情况下,需要确保数据维度的唯一性,采取复合主键加上限制。
写在最后
前后耗时一整天,完成了这次实验过程,目的就是检验几种表设计组合的实际应用效果,关于其他的问题,博主将在后续持续跟进。
实践出真知。
以上是关于数据库Mysql中主键的几种表设计组合的实际应用效果的主要内容,如果未能解决你的问题,请参考以下文章