MySQL技术探索01实现SQL语法解析器
Posted coe2coe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL技术探索01实现SQL语法解析器相关的知识,希望对你有一定的参考价值。
本文将介绍如何使用开源的语法和词法分析框架bison和flex来实现SQL解析器。出于技术学习的目的,本文做描述的微型SQL解析器仅能实现对微型SQL的语法解析。
1.mysql中的SQL解析器
包括JDBC、ODBC、ADO等等关系数据库客户端应用开发框架在内的各种SDK,核心功能是帮助程序员简化各种客户端的数据库操作,同时将SQL语句通过网络形式发送给MySQL等关系数据库的服务器进程。MySQL服务器进行负责解析并执行这些SQL语句。SQL语句中的语法规则多种多样,MySQL服务器是如何实现SQL解析的功能的呢? MySQL服务器代码中有一个SQL解析器组件。本文将主要介绍跟语法分析和词法分析相关的代码自动生成开源框架,以及如何在这些框架中定义一套微型SQL解析器的词法规则和语法规则,并在自动产生的代码的基础上开发一个微型SQL解析器软件。
2.词法解析器开源框架
词法解析器的功能是接受输入的文字,比如SQL脚本,根据一定的规则,将其转化为一连串的标记(token)。人工编写代码实现这个功能也是可行的,但是随着token的种类的增加和复杂程度的增加,这个编码工作非常的繁琐而且容易出错。
词法解析器框架的功能主要是根据自定义的词法规则,自动产生相应的词法解析器代码。
本文使用的开源框架是flex。flex是apache旗下的开源软件。使用flex,能够极大的降低编写词法解析器代码的工作量。
3.语法解析器开源框架
语法解析器的功能是接受输入的标记(token)序列,根据一定的规则额,匹配预先定义的语句规则,将其识别为这些语句中的一个语句。同样,人工编写代码实现这个功能不仅繁琐而且容易出错。
语法解析器框架的功能主要是根据自定义的语法规则,自动产生相应的语法解析器代码。
本文使用的开源框架是bison。bison也是apache旗下的开源软件。
4.微型SQL的例子
本文定义的微型SQL仅仅是标准SQL的一个很小的子集,仅仅提供建表、删表,以及增删改查操作的简单语句。
支持的SQL语句的例子如下所示:
CREATE TABLE语句和DROP TABLE语句以及注释。
目前暂不支持GROUP关键字,因此group暂时可以用作表名。
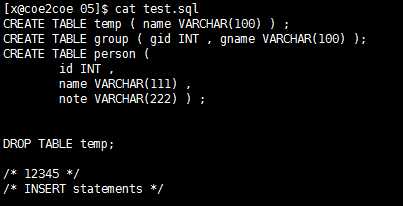
图1
(2)INSERT INTO语句。
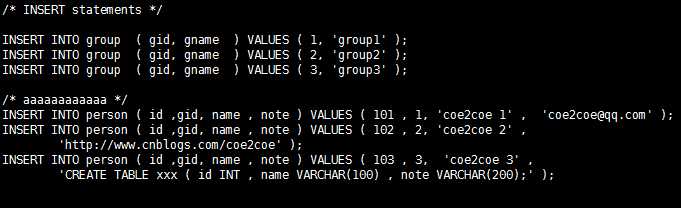
图2
UPDATE语句。

图3
DELETE语句。

图4
SELECT语句。
支持多表JOIN,以及嵌套子查询。
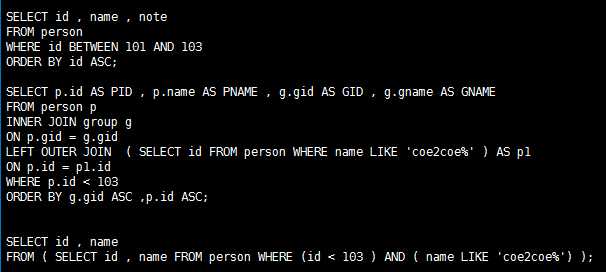
图5
混合使用flex和bison后,可以分析出每一个语句中的每一个关键字和标识符。
5.微型SQL的语法规则
bison要求的语法规则定义文件的总体格式如下:
%option 这里定义flex的一些选项,比如大小写是否忽略等等。
%{
//此处定义需要使用的C++ 的.h文件的#include指令。
%}
//接着定义一些使用到的token。每一个token是一个关键字,或者是一个标识符。
%token
%token
%token
%%
//这里定义语法规则。
%%
首先,为了满足微型SQL的关键字忽略大小写的要求等等,需要定义一些选项:

图6
noyywrap:当flex扫描到文件结束符(EOF)时,不会自动调用yywrap()函数。
yywrap:与noyywrap相反。
case-insensitive:关键字忽略大小写。SELECT和select以及Select都是合法关键字。
case-sensitive:与case-insensitive相反。
为了支持前面描述的微型SQL的解析工作,在my_sql_y.y文件中定义了如下的语法规则:
token列表。
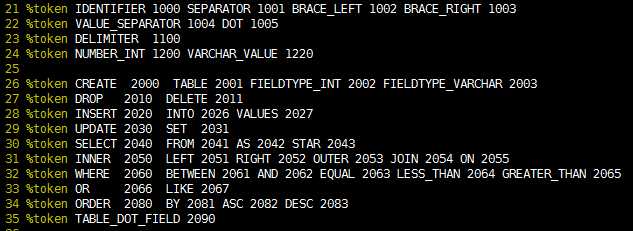
图7
总的SQL语法规则。
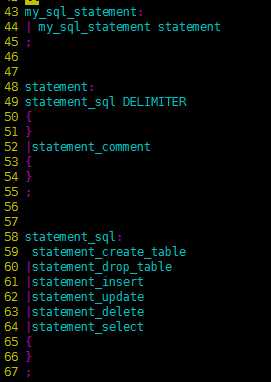
图8
语法规则定义如下所示:
statement_comment:
expr_comment
{
}
;
expr_comment:
COMMENT_BEGIN comment_text COMMENT_END
{
}
;
comment_text:
COMMENT_TEXT
|comment_text COMMENT_TEXT
{
}
;
statement_create_table:
CREATE TABLE table_name BRACE_LEFT field_definition_list BRACE_RIGHT
{
my_string_list::iterator it = get_current_statement()->token_list.begin();
++it; ++it;
get_current_statement()->create_table.table_name = *it;
printf("create table :{%s} ", it->c_str());
}
;
table_name:
IDENTIFIER
{
}
;
field_definition_list:
IDENTIFIER field_type
|field_definition_list SEPARATOR IDENTIFIER field_type
{
}
;
field_type:
FIELDTYPE_INT
|FIELDTYPE_VARCHAR BRACE_LEFT field_varchar_width BRACE_RIGHT
{
}
;
field_varchar_width:
NUMBER_INT
{
}
;
statement_drop_table:
DROP TABLE table_name
{
my_string_list::iterator it = get_current_statement()->token_list.begin();
++it; ++it;
get_current_statement()->drop_table.table_name = *it;
printf("drop table :{%s} ", it->c_str());
}
;
statement_insert:
INSERT INTO table_name BRACE_LEFT field_name_list BRACE_RIGHT VALUES BRACE_LEFT field_value_list BRACE_RIGHT
{
}
;
field_name_list:
field_name
|field_name SEPARATOR field_name_list
{
}
;
field_value_list:
field_value
|field_value SEPARATOR field_value_list
{
}
;
field_value:
int_value
|varchar_value
{
}
;
int_value:
NUMBER_INT
{
}
;
varchar_value:
VALUE_SEPARATOR varchar_value_list VALUE_SEPARATOR
{
}
;
varchar_value_list:
VARCHAR_VALUE
|VARCHAR_VALUE varchar_value_list
{
}
;
field_name:
IDENTIFIER
{
}
;
statement_update:
UPDATE table_name SET field_assign_value_list where_clause
{
}
;
field_assign_value_list:
field_assign_value
|field_assign_value SEPARATOR field_assign_value_list
{
}
;
field_assign_value:
field_name EQUAL field_value
{
}
;
where_clause:
|WHERE where_condition_list
{
}
;
where_condition_list:
where_condition
|where_condition condition_logic where_condition_list
{
}
;
where_condition:
condition_clause
|condition_between
|BRACE_LEFT where_condition_list BRACE_RIGHT
{
}
;
condition_clause:
condition_value condition_compare condition_value
{
}
;
condition_value:
field_name
|field_value
|table_dot_field_name
{
}
;
condition_compare:
EQUAL
|LESS_THAN
|GREATER_THAN
|LIKE
{
}
;
condition_between:
field_name BETWEEN condition_value AND condition_value
{
}
;
condition_logic:
AND
|OR
{
}
;
statement_select:
statement_select_simple
{
}
;
statement_select_simple:
SELECT select_field_list from_clause join_clause where_clause orderby_clause
{
}
;
select_field_list:
STAR
|select_field_name
|select_field_name SEPARATOR select_field_list
{
}
;
select_field_name:
select_field
|select_field IDENTIFIER
|select_field AS IDENTIFIER
{
}
;
select_field:
field_name
|table_dot_field_name
{
}
;
orderby_clause:
|ORDER BY orderby_field_list
{
}
;
orderby_field_list:
orderby_field
|orderby_field SEPARATOR orderby_field_list
{
}
;
orderby_field:
orderby_field_name
|orderby_field_name ASC
|orderby_field_name DESC
{
}
;
orderby_field_name:
field_name
|table_dot_field_name
{
}
;
from_clause:
FROM from_clause_simple
|FROM from_clause_subquery_no_alias
|FROM from_clause_subquery_with_alias
{
}
;
from_clause_simple:
select_table_name
{
}
;
from_clause_subquery_no_alias:
BRACE_LEFT statement_select BRACE_RIGHT
{
}
;
from_clause_subquery_with_alias:
clause_subquery AS table_name
clause_subquery table_name
{
}
;
clause_subquery:
BRACE_LEFT statement_select BRACE_RIGHT
{
}
;
select_table_name:
table_name
|table_name AS table_name
|table_name table_name
{
}
;
join_clause:
|inner_join_clause join_condition_clause join_clause
|left_join_clause join_condition_clause join_clause
|right_join_clause join_condition_clause join_clause
{
}
;
join_condition_clause:
ON join_condition
{
}
;
join_condition:
table_dot_field_name condition_compare table_dot_field_name
{
}
;
table_dot_field_name:
TABLE_DOT_FIELD
{
}
;
inner_join_clause:
INNER JOIN join_table_name
{
}
;
left_join_clause:
LEFT JOIN join_table_name
|LEFT OUTER JOIN join_table_name
{
}
;
right_join_clause:
RIGHT JOIN join_table_name
|RIGHT OUTER JOIN join_table_name
{
}
;
join_table_name:
table_name
|table_name AS table_name
|table_name table_name
|BRACE_LEFT statement_select BRACE_RIGHT AS table_name
|BRACE_LEFT statement_select BRACE_RIGHT table_name
{
}
;
statement_delete:
DELETE FROM table_name where_clause
{
}
;
6.微型SQL的词法规则
在my_sql_l.l文件中定义词法规则,主要涉及用到的关键字和标识符。
(1)文件结构和my_sql_y.y文件类似。
(2)下面列出词法规则中的所有关键字和标识符的定义。
%%
("CREATE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("CREATE !");return CREATE;}
("DROP"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("DROP !");return DROP;}
("TABLE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("TABLE !");return TABLE;}
[,]{1}{DO_TOKEN(GET_TOKEN());DEBUG_LOG("SEPARATOR !");return SEPARATOR;}
("INT"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("FIELDTYPE INT!");return FIELDTYPE_INT;}
(VARCHAR){DO_TOKEN(GET_TOKEN());DEBUG_LOG("FIELDTYPE VARCHAR !");return FIELDTYPE_VARCHAR;}
("/*"){is_in_comment++;;DEBUG_LOG("COMMENT_BEGIN!");return COMMENT_BEGIN;}
("*/"){is_in_comment--;DEBUG_LOG("COMMENT_END!");return COMMENT_END;}
[(]{DO_TOKEN(GET_TOKEN());DEBUG_LOG("BRACE_LEFT");return BRACE_LEFT;}
[)]{DO_TOKEN(GET_TOKEN());DEBUG_LOG("BRACE_RIGHT");return BRACE_RIGHT;}
[0-9]+{DO_TOKEN(GET_TOKEN());DEBUG_LOG("NUMBER_INT");return NUMBER_INT;}
";"{DO_TOKEN(GET_TOKEN());DEBUG_LOG("DELIMITER"); return DELIMITER;}
("INSERT"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("INSERT");return INSERT;}
("DELETE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("DELETE");return DELETE;}
("UPDATE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("UPDATE");return UPDATE;}
("SELECT"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("SELECT");return SELECT;}
("FROM"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("FROM");return FROM;}
("INTO"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("INTO");return INTO;}
("AS"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("AS");return AS;}
("WHERE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("WHERE");return WHERE;}
("SET"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("SET");return SET;}
("VALUES"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("VALUES");return VALUES;}
("*"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("STAR");return STAR;}
("."){DO_TOKEN(GET_TOKEN());DEBUG_LOG("DOT");return DOT;}
("‘"){if( 0 ==is_in_comment ){is_in_value = ((++is_in_value)%2);} DO_TOKEN(GET_TOKEN());DEBUG_LOG("VALUE_SEPARATOR");return VALUE_SEPARATOR;}
("AND"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("AND");return AND;}
("OR"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("OR");return OR;}
("INNER"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("INNER");return INNER;}
("LEFT"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("LEFT");return LEFT;}
("RIGHT"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("RIGHT");return RIGHT;}
("JOIN"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("JOIN");return JOIN;}
("OUTER"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("OUTER");return OUTER;}
("ON"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("ON");return ON;}
("ORDER"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("ORDER");return ORDER;}
("BY"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("BY");return BY;}
("ASC"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("ASC");return ASC;}
("DESC"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("DESC");return DESC;}
("="){DO_TOKEN(GET_TOKEN());DEBUG_LOG("EQUAL");return EQUAL;}
("<"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("LESS_THAN");return LESS_THAN;}
(">"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("GREATER_THAN");return GREATER_THAN;}
("LIKE"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("LIKE");return LIKE;}
("BETWEEN"){DO_TOKEN(GET_TOKEN());DEBUG_LOG("BETWEEN");return BETWEEN;}
[A-Za-z0-9_]+{DO_TOKEN(GET_TOKEN());DEBUG_LOG("IDENTIFIER !");return IDENTIFIER;}
[A-Za-z0-9_]+.[A-Za-z0-9]+{DO_TOKEN(GET_TOKEN());DEBUG_LOG("TABLE_DOT_FIELD !");return TABLE_DOT_FIELD;}
[[email protected]#/\\:&%!.*?+]+{DO_TOKEN(GET_TOKEN());DEBUG_LOG("VARCHAR_VALUE!");return VARCHAR_VALUE;}
[[email protected]#/\\:&^%$~!.*?+]+{DEBUG_LOG("COMMENT_TEXT!");return COMMENT_TEXT;}
%%
7.主程序说明
在主程序中调用yyparse()函数。
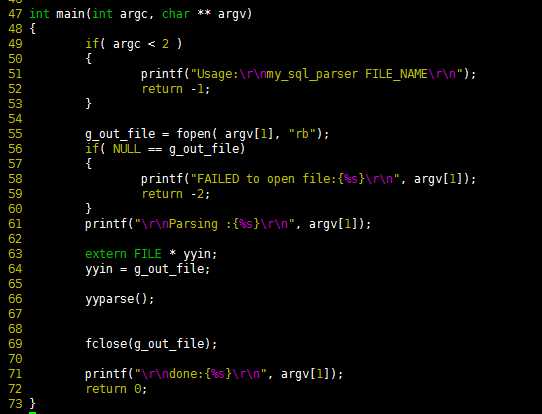
图9
yyparse()函数启动bison的语法分析过程,最终会调用yylex()函数识别出一个个的token,即关键字和标识符。由于这里使用了flex,flex根据my_sql_l.l文件自动产生了yylex()函数的实现代码,因此这个函数不需要人工编写。
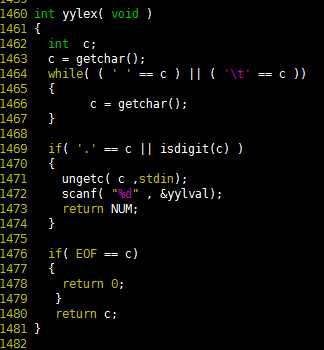
图10
最后列出所使用的Makefile文件。
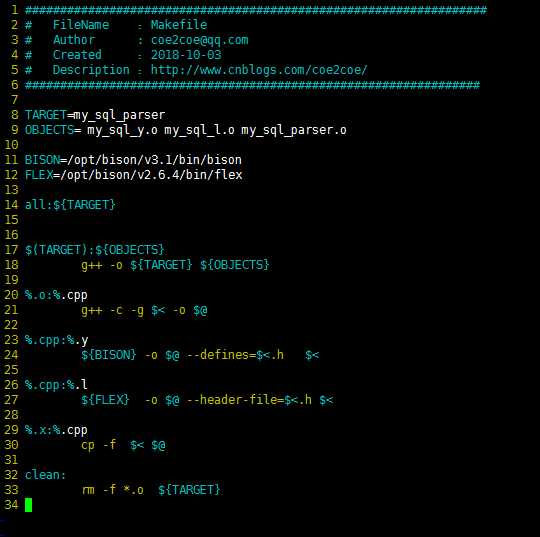
图11
总结:
混合使用bison和flex的情况下,制作SQL解析器,需要以下几个步骤:
(1)编写my_sql_y.y文件。
这个文件定义语法规则,用于bison程序自动产生语法分析代码的my_sql_y.cpp文件。
(2)编写my_sql_l.l文件。
这个文件定义词法规则,用于flex程序自动产生词法分析代码的my_sql_l.cpp文件,最主要是产生yylex()函数。
(3)使用bison和flex程序产生相应的cpp文件。
(4)编写主程序代码。
主要是启动yyparse()函数开始语法分析工作。
8.运行测试结果
本文描述的方法用于准确的分析给出的SQL语句是否符合语法规则,对于不符合的给出语法错误的提示,对于符合规则的,给出符合哪一条规则,并准确解析出该SQL语句中的每一个关键字和标识符的值。
SELECT语句的分析:
原始SQL语句如下:
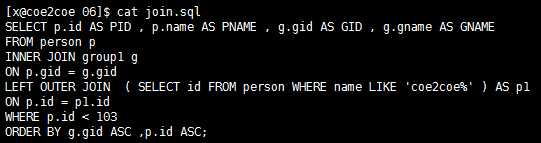
图12
分析的结果中的几个条目如下:
{SELECT}@c={0} @v={0}{SELECT}
说明:
第一个SELECT是识别出来的字符串。后面那个SELECT说明这个字符串是SELECT语句中的SELECT关键字。@c:是否为注释,0表示不是注释。@v:是否为字符串值,0表示不是字符串值。字符串值指的是INSERT/UPDATE/WHERE等中的VARCHAR(100)类型的字段的值,即单引号之类的字符串。
{p.id}@c={0} @v={0}{TABLE_DOT_FIELD !}
说明:
这个p.id是识别出来的字符串,TABLE_DOT_FIELD说明这是一个“表名.列名”标识符。
完整分析结果如下:
SELECT ... FROM部分的分析结果:
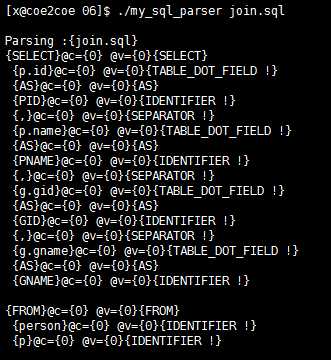
图13
INNER JOIN和LEFT OUTER JOIN部分的分析结果,实现了三表JOIN的解析。

图14
这是WHERE子句部分,以及语句结束后输出的完整解析结果(即SQL的复原)。
语句以分号(;)作为语句结束符。
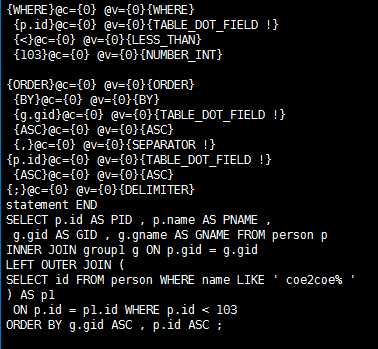
图15
UPDATE语句的分析。
UPDATE语句如下:
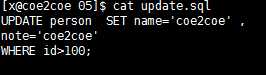
图16
分析结果如下:
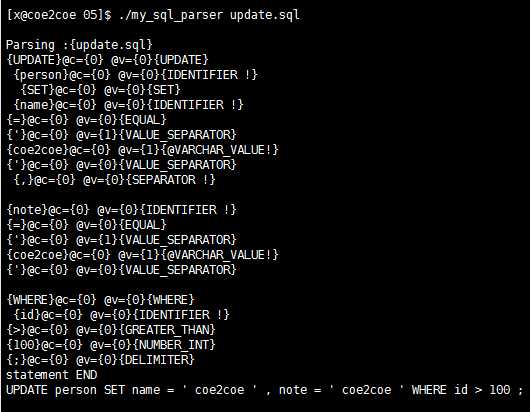
图17
目前的微型SQL语法解析器还是非常的简陋。不管怎样,这个微型SQL的语法解析器的原型已经完成了。
MySQL服务器中的SQL解析器除了SQL的语法解析工作之外,还做了其它一些更为复杂的工作。这些工作有待以后有机会再去继续探索。
以上是关于MySQL技术探索01实现SQL语法解析器的主要内容,如果未能解决你的问题,请参考以下文章