python 使用jieba分词出错
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 使用jieba分词出错相关的知识,希望对你有一定的参考价值。
代码如下:
# -- coding: utf-8 --
import jieba
test="小明硕士毕业于中国科学院计算所,后在日本京都大学深造。"
test_g=jieba.cut(test)
print ", ".join(test_g)
错误为:Building prefix dict from the default dictionary ...
Traceback (most recent call last):
File "D:/����������/��Դ��/vs����/PythonApplication4/PythonApplication4/test.py", line 5, in <module>
print ", ".join(test_g)
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 301, in cut
for word in cut_block(blk):
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 233, in __cut_DAG
DAG = self.get_DAG(sentence)
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 179, in get_DAG
self.check_initialized()
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 168, in check_initialized
self.initialize()
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 143, in initialize
self.FREQ, self.total = self.gen_pfdict(self.get_dict_file())
File "D:\���\python2\lib\site-packages\jieba\__init__.py", line 352, in get_dict_file
return get_module_res(DEFAULT_DICT_NAME)
File "D:\���\python2\lib\site-packages\jieba\_compat.py", line 8, in <lambda>
os.path.join(*res))
File "D:\���\python2\lib\site-packages\pkg_resources\__init__.py", line 1208, in resource_stream
self, resource_name
File "D:\���\python2\lib\site-packages\pkg_resources\__init__.py", line 1573, in get_resource_stream
return open(self._fn(self.module_path, resource_name), 'rb')
File "D:\���\python2\lib\site-packages\pkg_resources\__init__.py", line 1524, in _fn
return os.path.join(base, *resource_name.split('/'))
File "D:\���\python2\lib\ntpath.py", line 85, in join
result_path = result_path + p_path
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc8 in position 1: ordinal not in range(128)
我用的pycharm 但是感觉不是代码的问题,因为同样的代码在别的机子上是没问题的
猜测你使用的 Python 版本为 Python2 但是使用 coding: utf-8 设置中文编码只在 Python 3 有效
所以 设置默认编码 应在代码开始部分应该加上
import sysreload(sys)
sys.setdefaultencoding(\'UTF-8\') 参考技术A 在你的第一行,用#coding=utf-8 试试
SEVEN python环境jieba分词的安装 以即热词索引
由于项目需要,使用jieba分词库
点击项目,默认设置,选择项目翻译点击右侧 + ,
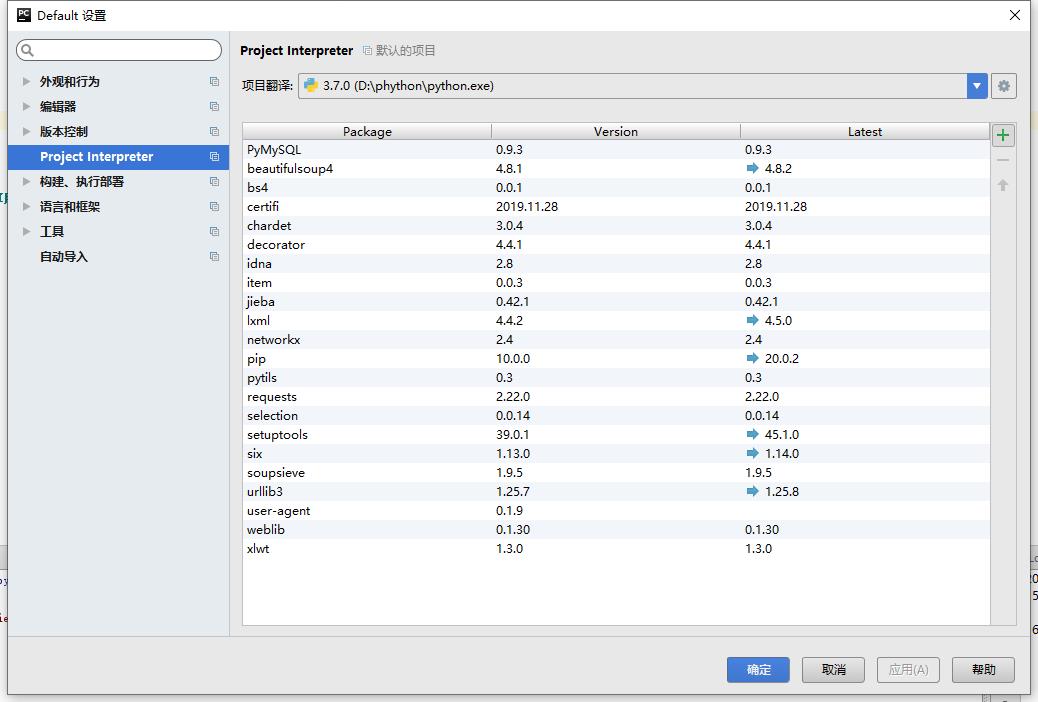
查询jieba ,点击左下角安装

还有一个放法(此方法未使用)
首先上githup下载jieba分词库
然后加压到任意目录
打开cmd命令行窗口并切换到jieba目录下
运行python setup.py install完成安装
在项目中使用import jieba使用jieba分词库
热刺索引
import jieba
txt=open("D:/hotword.txt","r",encoding="utf-8").read()
words =jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items =list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
word, count = items[i]
print(word, count)
# print(\'{0:<10}{1:>5}\'.format(word,count))
检索资源来自飘的百度百科部分介绍:

以上是关于python 使用jieba分词出错的主要内容,如果未能解决你的问题,请参考以下文章