module如何创意写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了module如何创意写相关的知识,希望对你有一定的参考价值。
不知道在什幺时候,Linux 出现了 module 这种东西,的确,它是 Linux 的一大革新。有了 module 之后,写 device driver 不再是一项恶梦,修改 kernel 也不再是一件痛苦的事了。因为你不需要每次要测试 driver 就重新 compile kernel 一次。那简直是会累死人。Module 可以允许我们动态的改变 kernel,加载 device driver,而且它也能缩短我们 driver development 的时间。在这篇文章里,我将要跟各位介绍一下 module 的原理,以及如何写一个 module。module 翻译成中文就是模块,不过,事实上去翻译这个字一点都没意义。在讲模块之前,我先举一个例子。相信很多人都用过 RedHat。在 RedHat 里,我们可以执行 sndconfig,它可以帮我们 config 声卡。config 完之后如果捉得到你的声卡,那你的声卡马上就可以动了,而且还不用重新激活计算机。这是怎幺做的呢 ? 就是靠module。module 其实是一般的程序。但是它可以被动态载到 kernel 里成为 kernel的一部分。载到 kernel 里的 module 它具有跟 kernel 一样的权力。可以 access 任何 kernel 的 data structure。你听过 kdebug 吗 ? 它是用来 debug kernel 的。它就是先将它本身的一个 module 载到 kernel 里,而在 user space 的 gdb 就可以经由跟这个 module 沟通,得知 kernel 里的 data structure 的值,除此之外,还可以经由载到 kernel 的 module 去更改 kernel 里 data structure。
我们知道,在写 C 程序的时候,一个程序只能有一个 main。Kernel 本身其实也是一个程序,它本身也有个 main,叫 start_kernel()。当我们把一个 module 载到 kernel 里的时候,它会跟 kernel 整合在一起,成为 kernel 的一部分。请各位想想,那 module 可以有 main 吗 ? 答案很明显的,是 No。理由很简单。一个程序只能有一个 main。在使用 module 时,有一点要记住的是 module 是处于被动的角色。它是提供某些功能让别人去使用的。
Kernel 里有一个变量叫 module_list,每当 user 将一个 module 载到 kernel 里的时候,这个 module 就会被记录在 module_list 里面。当 kernel 要使用到这个 module 提供的 function 时,它就会去 search 这个 list,找到 module,然后再使用其提供的 function 或 variable。每一个 module 都可以 export 一些 function 或变量来让别人使用。除此之外,module 也可以使用已经载到 kernel 里的 module 提供的 function。这种情形叫做 module stack。比方说,module A 用到 module B 的东西,那在加载 module A 之前必须要先加载 module B。否则 module A 会无法加载。除了 module 会 export 东西之外,kernel 本身也会 export 一些 function 或 variable。同样的,module 也可以使用 kernel 所 export 出来的东西。由于大家平时都是撰写 user space 的程序,所以,当突然去写 module 的时候,会把平时写程序用的 function 拿到 module 里使用。像是 printf 之类的东西。我要告诉各位的是,module 所使用的 function 或 variable,要嘛就是自己写在 module 里,要嘛就是别的 module 提供的,再不就是 kernel 所提供的。你不能使用一般 libc 或 glibc所提供的 function。像 printf 之类的东西。这一点可能是各位要多小心的地方。(也许你可以先 link 好,再载到 kernel,我好象试过,但是忘了)
刚才我们说到 kernel 本身会 export 出一些 function 或 variable 来让 module 使用,但是,我们不是万能的,我们怎幺知道 kernel 有开放那里东西让我们使用呢 ? Linux 提供一个 command,叫 ksyms,你只要执行 ksyms -a 就可以知道 kernel 或目前载到 kernel 里的 module 提供了那些 function 或 variable。底下是我的系统的情形:
c0216ba0 drive_info_R744aa133
c01e4a44 boot_cpu_data_R660bd466
c01e4ac0 EISA_bus_R7413793a
c01e4ac4 MCA_bus_Rf48a2c4c
c010cc34 __verify_write_R203afbeb
. . . . .
在 kernel 里,有一个 symbol table 是用来记录 export 出去的 function 或 variable。除此之外,也会记录着那个 module export 那些 function。上面几行中,表示 kernel 提供了 drive_info 这个 function/variable。所以,我们可以在 kernel 里直接使用它,等载到 kernel 里时,会自动做好 link 的动作。由此,我们可以知道,module 本身其实是还没做 link 的一些 object code。一切都要等到 module 被加载 kernel 之后,link 才会完成。各位应该可以看到 drive_info 后面还接着一些奇怪的字符串。_R744aa133,这个字符串是根据目前 kernel 的版本再做些 encode 得出来的结果。为什幺额外需要这一个字符串呢 ?
Linux 不知道从那个版本以来,就多了一个 config 的选项,叫做 Set version number in symbols of module。这是为了避免对系统造成不稳定。我们知道 Linux 的 kernel 更新的很快。在 kernel 更新的过程,有时为了效率起见,会对某些旧有的 data structure 或 function 做些改变,而且一变可能有的 variable 被拿掉,有的 function 的 prototype 跟原来的都不太一样。如果这种情形发生的时候,那可能以前 2.0.33 版本的 module 拿到 2.2.1 版本的 kernel 使用,假设原来 module 使用了 2.0.33 kernel 提供的变量叫 A,但是到了 2.2.1 由于某些原因必须把 A 都设成 NULL。那当此 module 用在 2.2.1 kernel 上时,如果它没去检查 A 的值就直接使用的话,就会造成系统的错误。也许不会整个系统都死掉,但是这个 module 肯定是很难发挥它的功能。为了这个原因,Linux 就在 compile module 时,把 kernel 版本的号码 encode 到各个 exported function 和 variable 里。
所以,刚才也许我们不应该讲 kernel 提供了 drive_info,而应该说 kernel 提供了 driver_info_R744aa133 来让我们使用。这样也许各位会比较明白。也就是说,kernel 认为它提供的 driver_info_R744aa133 这个东西,而不是 driver_info。所以,我们可以发现有的人在加载 module 时,系统都一直告诉你某个 function 无法 resolved。这就是因为 kernel 里没有你要的 function,要不然就是你的 module 里使用的 function 跟 kernel encode 的结果不一样。所以无法 resolve。解决方式,要嘛就是将 kernel 里的 set version 选项关掉,要嘛就是将 module compile 成 kernel 有办法接受的型式。
那有人就会想说,如果 kernel 认定它提供的 function 名字叫做 driver_info_R744aa133 的话,那我们写程序时,是不是用到这个 funnction 的地方都改成 driver_info_R744aa133 就可以了。答案是 Yes。但是,如果每个 function 都要你这样写,你不会觉得很烦吗 ? 比方说,我们在写 driver 时,很多人都会用到 printk 这个 function。这是 kernel 所提供的 function。它的功能跟 printf 很像。用法也几乎都一样。是 debug 时很好用的东西。如果我们 module 里用了一百次 printk,那是不是我们也要打一百次的 printk_Rdd132261 呢 ? 当然不是,聪明的人马上会想到用 #define printk printk_Rdd132261 就好了嘛。所以啰,Linux 很体贴的帮我们做了这件事。
如果各位的系统有将 set version 的选项打开的话,那大家可以到 /usr/src/linux/include/linux/modules 这个目录底下。这个目录底下有所多的 ..ver档案。这些档案其实就是用来做 #define 用的。我们来看看 ksyms.ver 这个档案里,里面有一行是这样子的 :
#define printk _set_ver(printk)
set_ver 是一个 macro,就是用来在 printk 后面加上 version number 的。有兴趣的朋友可以自行去观看这个 macro 的写法。用了这些 ver 档,我们就可以在 module 里直接使用 printk 这样的名字了。而这些 ver 档会自动帮我们做好 #define 的动作。可是,我们可以发现这个目录有很多很多的 ver 档。有时候,我们怎幺知道我们要呼叫的 function 是在那个 ver 档里有定义呢 ? Linux 又帮我们做了一件事。/usr/src/linux/include/linux/modversions.h 这个档案已经将全部的 ver 档都加进来了。所以在我们的 module 里只要 include 这个档,那名字的问题都解决了。但是,在此,我们奉劝各位一件事,不要将 modversions.h 这个档在 module 里 include 进来,如果真的要,那也要加上以下数行:
#ifdef MODVERSIONS
#include linux/modversions.h>;
#endif
加入这三行的原因是,避免这个 module 在没有设定 kernel version 的系统上,将 modversions.h 这个档案 include 进来。各位可以去试试看,当你把 set version 的选项关掉时,modversions.h 和 modules 这个目录都会不见。如果没有上面三行,那 compile 就不会过关。所以一般来讲,modversions.h 我们会选择在 compile 时传给 gcc 使用。就像下面这个样子。
gcc -c -D__KERNEL__ -DMODULE -DMODVERSIONS main.c
-include usr/src/linux/include/linux/modversions.h
在这个 command line 里,我们看到了 -D__KERNEL__,这是说要定义 __KERNEL__ 这个 constant。很多跟 kernel 有关的 header file,都必须要定义这个 constant 才能 include 的。所以建议你最好将它定义起来。另外还有一个 -DMODVERSIONS。这个 constant 我刚才忘了讲。刚才我们说要解决 fucntion 或 variable 名字 encode 的方式就是要 include modversions.h,其实除此之外,你还必须定义 MODVERSIONS 这个 constant。再来就是 MODULE 这个 constant。其实,只要是你要写 module 就一定要定义这个变量。而且你还要 include module.h 这个档案,因为 _set_ver 就是定义在这里的。
讲到这里,相信各位应该对 module 有一些认识了,以后遇到 module unresolved 应该不会感到困惑了,应该也有办法解决了。
刚才讲的都是使用别人的 function 上遇到的名字 encode 问题。但是,如果我们自己的 module 想要 export 一些东西让别的 module 使用呢。很简单。在 default 上,在你的 module 里所有的 global variable 和 function 都会被认定为你要 export 出去的。所以,如果你的 module 里有 10 个 global variable,经由 ksyms,你可以发现这十个 variable 都会被 export 出去。这当然是个很方便的事啦,但是,你知道,有时候我们根本不想把所有的 variable 都 export 出去,万一有个 module 没事乱改我们的 variable 怎幺办呢 ? 所以,在很多时候,我们都只会限定几个必要的东西 export 出去。在 2.2.1 之前的 kernel (不是很确定) 可以利用 register_symtab 来帮我们。但是,现在更新的版本早就出来了。所以,在此,我会介绍 kernel 2.2.1 里所提供的。kernel 2.2.1 里提供了一个 macro,叫做 EXPORT_SYMBOL,这是用来帮我们选择要 export 的 variable 或 function。比方说,我要 export 一个叫 full 的 variable,那我只要在 module 里写:
EXPORT_SYMBOL(full);
就会自动将 full export 出去,你马上就可以从 ksyms 里发现有 full 这个变量被 export 出去。在使用 EXPORT_SYMBOL 之前,要小心一件事,就是必须在 gcc 里定义 EXPORT_SYMTAB 这个 constant,否则在 compile 时会发生 parser error。所以,要使用 EXPORT_SYMBOL 的话,那 gcc 应该要下:
gcc -c -D__KERNEL__ -DMODULE -DMODVERSIONS -DEXPORT_SYMTAB
main.c -include /usr/src/linux/include/linux/modversions.h
如果我们不想 export 任何的东西,那我们只要在 module 里下
EXPORT_NO_SYMBOLS;
就可以了。使用 EXPORT_NO_SYMBOLS 用不着定义任何的 constant。其实,如果各位使用过旧版的 register_symbol 的话,一定会觉得新版的方式比较好用。至少我是这样觉得啦。因为使用 register_symbol 还要先定义出自己的 symbol_table,感觉有点麻烦。
当我们使用 EXPORT_SYMBOL 把一些 function 或 variable export 出来之后,我们使用 ksyma -a 去看一些结果。我们发现 EXPORT_SYMBOL(full) 的确是把 full export出来了 :
c8822200 full [my_module]
c01b8e08 pci_find_slot_R454463b5
. . .
但是,结果怎幺跟我们想象中的不太一样,照理说,应该是 full_Rxxxxxx 之类的东西才对啊,怎幺才出现 full 而已呢 ? 奇怪,问题在那里呢 ?
其实,问题就在于我们没有对本身的 module 所 export 出来的 function 或 variable 的名字做 encode。想想,如果在 module 的开头。我们加入一行
#define full full_Rxxxxxx
之后,我们再重新 compile module 一次,载到 kernel 之后,就可以发现 ksyms -a 显示的是
c8822200 full_Rxxxxxx [my_module]
c01b8e08 pci_find_slot_R454463b5
. . . . .
了。那是不是说,我们要去对每一个 export 出来的 variable 和 function 做 define 的动作呢 ? 当然不是啰。记得吗,前头我们讲去使用 kernel export 的 function 时,由于 include 了一些 .ver 的档案,以致于我们不用再做 define 的动作。现在,我们也要利用 .ver 的档案来帮我们,使我们 module export 出来的 function 也可以自动加入 kernel version 的 information。也就是变成 full_Rxxxxxx 之类的东西。
Linux 里提供了一个 command,叫 genksyms,就是用来帮我们产生这种 .ver 的档案的。它会从 stdin 里读取 source code,然后检查 source code 里是否有 export 的 variable 或 function。如果有,它就会自动为每个 export 出来的东西产生一些 define。这些 define 就是我们之前说的。等我们有了这些 define 之后,只要在我们的 module 里加入这些 define,那 export 出来的 function 或 variable 就会变成上面那个样子。
假设我们的程序都放在一个叫 main.c 的档案里,我们可以使用下列的方式产生这些 define。
gcc -E -D__GENKSYMS__ main.c | genksyms -k 2.2.1 >; main.ver
gcc 的 -E 参数是指将 preprocessing 的结果 show 出来。也就是说将它 include 的档案,一些 define 的结果都展开。-D__GENKSYMS__ 是一定要的。如果没有定义这个 constant,你将不会看到任何的结果。用一个管线是因为 genksyms 是从 stdin 读资料的,所以,经由管线将 gcc 的结果传给 genksyms。-k 2.2.1 是指目前使用的 kernel 版本是 2.2.1,如果你的 kernel 版本不一样,必须指定你的 kernel 的版本。产生的 define 将会被放到 main.ver 里。产生完 main.ver 档之后,在 main.c 里将它 include 进来,那一切就 OK 了。有件事要告诉各位的是,使用这个方式产生的 module,其 export 出来的东西会经由 main.ver 的 define 改头换面。所以如果你要让别人使用,那你必须将 main.ver 公开,不然,别人就没办法使用你 export 出来的东西了。
讲了这幺多,相信各位应该都已经比较清楚 module 在 kernel 中是怎幺样一回事,也应该知道为什幺有时候 module 会无法加载了。除此之外,各位应该还知道如何使自己 module export 出来的东西也具有 kernel version 的 information。
接下来,要跟各位讲的就是,如何写一个 module 了。其实,写一个 module 很简单的。如果你了解我上面所说的东西。那我再讲一次,再用个例子,相信大家就都会了。要写一个 module,必须要提供两个 function。这两个 function 是给 insmod 和 rmmod 使用的。它们分别是 init_module(),以及 cleanup_module()。
int init_module();
void cleanup_module();
相信大家都知道在 Linux 里可以使用 insmod 这个 command 来将某个 module 加载。比方说,我有一个 module 叫 hello.o,那使用 insmod hello.o 就可以将 hello 这个 module 载到 kernel 里。观察 /etc/modules 应该就可以看到 hello 这个 module 的名字。如果要将 hello 这个 module 移除,则只要使用 rmmod hello 就可以了。insmod 在加载 module 之后,就会去呼叫 module 所提供的 init_module()。如果传回 0 表示成功,那 module 就会被加载。如果失败,那加载的动作就会失败。一般来讲,我们在 init_module() 做的事都是一些初始化的工作。比方说,你的 module 需要一块内存,那你就可以在 init_module() 做 kmalloc 的动作。想当然尔。cleanup_module() 就是在 module 要移除的时候做的事。做的事一般来讲就是一些善后的工作,比方像把之前 kmalloc 的内存 free 掉。
由于 module 是载到 kernel 使用的,所以,可能别的 module 会使用你的 module,甚至某些 process 也会使用到你的 module,为了避免 module 还有人使用时就被移除,每个 module 都有一个 use count。用来记录目前有多少个 process 或 module 正在使用这个 module。当 module 的 use count 不等于 0 时,module 是不会被移除掉的。也就是说,当 module 的 use count 不等于 0 时,cleanup_module() 是不会被呼叫的。
在此,我要介绍三个 macro,是跟 module 的 use count 有关的。
MOD_INC_USE_COUNT
MOD_DEC_USE_COUNT
MOD_IN_USE
MOD_INC_USE_COUNT 是用来增加 module 的 use count,而 MOD_DEC_USE_COUNT 是用来减少 module 的 use count。至于 MOD_IN_USE 则是用来检查目前这个 module 是不是被使用中。也就是检查 use count 是否为 0。module 的 use count 必须由写 module 的人自己来 maintain。系统并不会自动为你把 use count 加一或减一。一切都得由自己控制。下面有一个例子,但是,并不会介绍这三个 macro 的使用方法。将来如果有机会,我再来介绍这三个 macro 的用法。
这个例子很简单。其实只是示范如何使用 init_module() 以及 cleanup_module() 来写一个 module。当然,这两个 function 只是构成 module 的基本条件罢了。至于 module 里要提供的功能则是看各人的需要。
main.c
#define MODULE
#include linux/module.h>;
#include asm/uaccess.h>;
int full;
EXPORT_SYMBOL(full); /* 将 full export 出去 */
int init_module( void )
printk( 5>; Module is loadedn );
return 0;
void cleanup_module( void )
printk( 5>; Module is unloadedn );
关于 printk 是这样子的,它是 kernel 所提供的一个打印讯息的 function。kernel 有 export 这个 function。所以你可以自由的使用它。它的用法跟 printf 几乎一模一样。唯独讯息的开头是 5>;,其实,不见得这三个字符啦。也可以是 4>;,3>;,7>; 等等的东西。这是代表这个讯息的 prioirty 或 level。5>; 表示的是跟 KERNEL 有关的讯息。
main.ver:
利用 genksyms 产生出来的。
gcc -E -D__GENKSYMS__ main.c | genksyms -k 2.2.1 >; main.ver
接下来,就是要把 main.c compile 成 main.o
gcc -D__KERNEL__ -DMODVERSIONS -DEXPORT_SYMTAB -c
-I/usr/src/linux/include/linux -include
/usr/src/linux/include/linux/modversions.h
-include ./main.ver main.c
好了。main.o 已经成功的 compile 出来了,现在下一个 command,
insmod main.o
检查看 /proc/modules 里是否有 main 这个 module。如果有,表示 main 这个 module 已经载到 kernel 了。再下一个指令,看看 full export 出去的结果。
ksyms
结果显示
Address Symbol Defined by
c40220e0 full_R355b84b2 [main]
c401d04c ne_probe [ne]
c401a04c ei_open [8390]
c401a094 ei_close [8390]
c401a504 ei_interrupt [8390]
c401af1c ethdev_init [8390]
c401af80 NS8390_init [8390]
可以看到 full_R355b84b2,表示,我们已经成功的将 full 的名字加上 kernel version 的 information 了。当我们不需要这个 module 时,我们就可以下一个 command,
rmmod main
这样 main 就会被移除掉了。再检查看看 /proc/modules 就可以发现 main 那一行不见了。各位现在可以看一下 /var/log/message 这个档案,应该可以发现以两行
Apr 12 14:19:05 host kernel: Module is loaded
Apr 12 14:39:29 host kernel: Module is unloaded
这两行就是 printk 印出来的。
关于 module 的介绍已经到此告一段落了。其实,使用 module 实在是很简单的一件事。对于要发展 driver 或是增加 kernel 某些新功能的人来讲,用 module 不啻为一个方便的方式。 参考技术A 您好,写一篇module的创意文章,首先,应该明确文章的主题,然后,根据主题,结合实际情况,给出一些有创意的观点,并且要有足够的例子来说明这些观点,以便读者能够更好地理解。此外,文章中应该尽量避免重复,以免让读者感到厌烦。最后,文章应该有一个结论,以便读者能够得出一个结论,从而更好地理解文章的内容。 参考技术B module是一种把代码组织成可重用的单元的方式,它可以帮助我们更好地管理代码,提高代码的可读性和可维护性。
在创建module时,可以考虑以下几点:
1. 将相关的代码放在一起,以便更好地管理。
2. 将不同功能的代码分别放在不同的module中,以便更好地维护。
3. 将可重用的代码放在module中,以便更好地复用。
4. 将可能发 参考技术C module,一般理解来讲是一段
module是一种更好地编写、组织代码的方法,它通过将项目的功能划分为可复用的模块,更容易了集成,创建和测试。它的组成方式也简单易懂,模块间的依赖可随时更改,并可单独测试,有助于快速开发高质量的软件项目。
由于模块可从各处重复利用,因此它们是可维护的。它们的简洁易懂的结构可帮助程序员更快得地理解代码,快速掌握项目结构。此外,多人协作开发时,模块可有效防止混乱,易于拆分工作,并实现最大的协作效率。
模块在整体设计阶段就应考虑,它可以让代码更加可读,高效,可复用,从而节省开发时间和代码维护成本,有助于更好地解决系统架构设计问题,从而更快地完成开发任务。 参考技术D 您好,创意写作是一种艺术,它需要你有创造力,有想象力,有良好的语言表达能力。在写作之前,你需要先收集有关你要写的主题的信息,以便你有足够的素材可以发挥你的创造力。接下来,你需要制定一个计划,确定你要写的内容,以及你要使用的语言和文字。最后,你需要把你的想法和计划转化为文字,把你的思想表达出来,并且尽可能的把你的文章写得更加完整,更加精彩。
如何利用涂鸦免开发产品方案实现创意速搭
如何利用涂鸦免开发产品方案实现创意速搭
如何利用涂鸦智能免开发方案搭建生活中的创意。在生活中,我们在不经意间就可能会有一些创意,它或许是一个开关,或许是一个检测装置,又或许是一个远程数据采集的装置。但是又有很多同学可能因为项目紧迫、专业限制等原因,卡在硬件设计、程序设计、结构设计、APP设计等其中的任意一个环节。
但是我们又有极大的兴趣将这些创意制作出来,去帮助我们远程自动完成某个动作,或者获得一项专利,或者开发一款新型产品帮助更多的人。今天我们就探讨一下如何利用涂鸦智能的免开发产品方案快速转化制作自己的创意。
为什么选择涂鸦智能
-
涂鸦的免开发方案可以在线配置硬件固件,可省去程序开发步骤,配合必要的硬件电路就可以接入网络,实现APP控制及状态查看。
-
免开发产品方案品类多,并且在不断更新,找到一个产品方案当作平台的可能性大,可快速在其基础上进行改装。

-
APP面板成熟,可编辑,可选设计元素多,可根据自己的产品特性快速搭建自己的面板。即使是DIY的创意,仍然可以搭建出一个成熟的产品级别面板,使用体验完美,展示效果更出色。
-
云模组丰富,可选择通信方式多,用户可根据自己的需求选择模组,目前涂鸦免开发方案支持的模组也在不断地开放,不断地丰富。
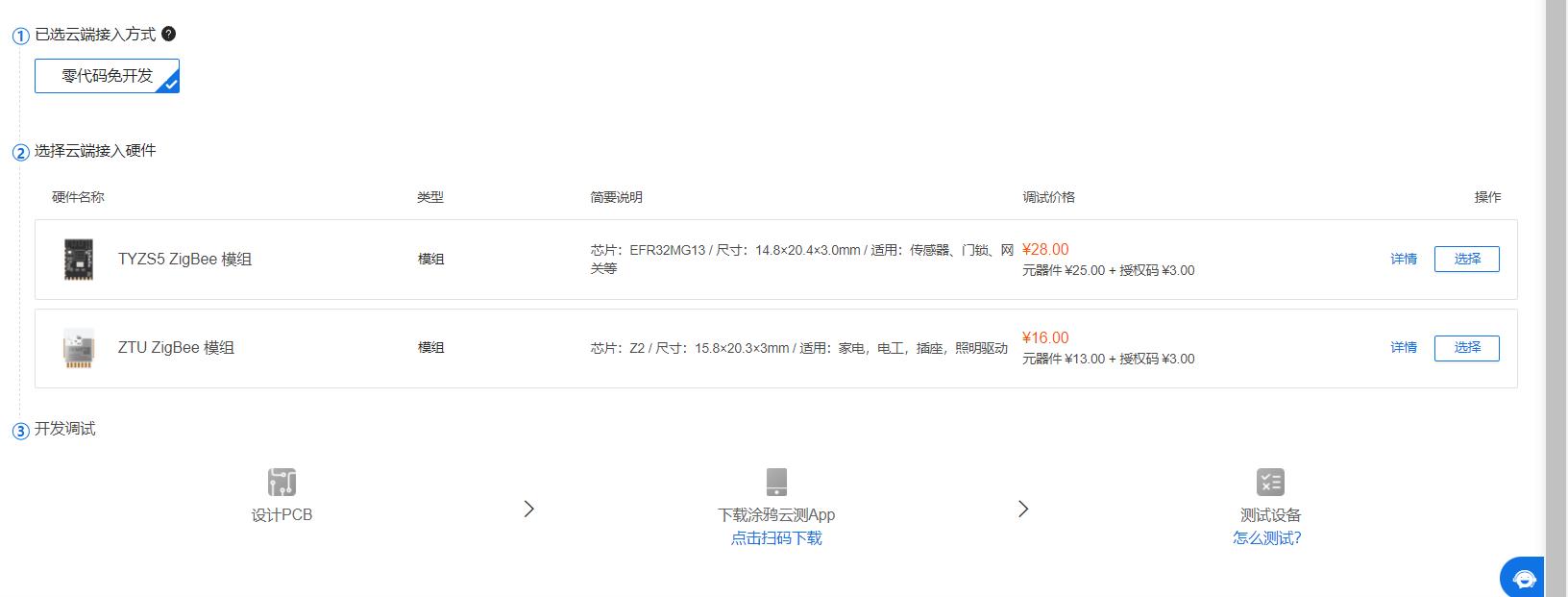
-
价格实惠,服务周到。相比于其他品牌的联网模组,涂鸦云模组相对来说比较便宜,在平台上配置好固件以后,涂鸦会将固件烧录好再发货。而且多数模组支持在线升级固件,方便大家调试。
快速创意搭建步骤
第一步:明确功能类型,原理上可行
在我们想好自己的创意以后,如何通过涂鸦智能的免开发产品方案,快速改造出自己的创意制作。首先就要明确我们的创意的功能类型,然后再涂鸦智能平台上寻找对应的零代码实现方案。
举一个例子,在本社区里面有一个Zigbee智慧厕所门方案,就是通过涂鸦Zigbee门磁免开发案改造而来。有了智慧厕所门创意以后,其根本就是我们需要一个检测开关,可在APP查看厕所门的状态,实现在一坑难求的情况下,精准定位,找到空闲坑位。

而Zigbee门磁方案核心检测装置是干簧管就是一个由磁铁触发的开关,这样的话在程序上二者是相通的,其他凡是采用Zigbee通信方式的开关检测的创意,都可以用这个方案来改造。实现我们的创意。
第二步:在涂鸦智能平台上创建产品,配置好面板和固件。
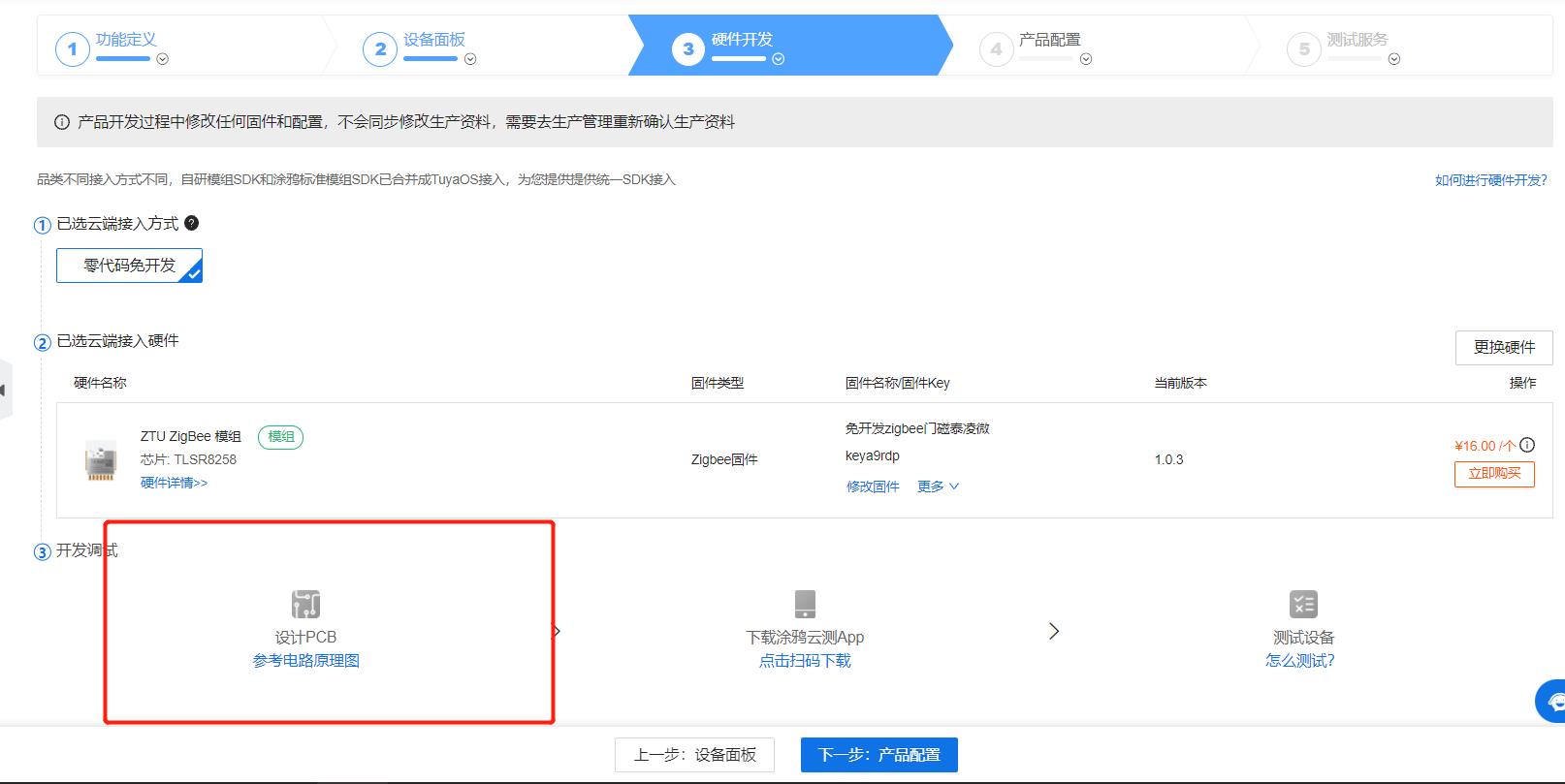
选择好要改装的零代码开发方案以后,就可以选用可选面板,或者自行搭建面板。随后进入硬件配置选择合适的模组,配置好硬件连接管脚,生成固件。

第三步:硬件设计
不需吃透整本数电模电,只需弄懂方案的原理即可。配置好固件以后,我们可以根据参考原理图,设计PCB。在PCB设计上,如果我们是小白,难以使用AD、Candence等主流设计软件。我们可以用国产的立创EDA。
第四步:结构设计
完成产品创建,配置好面板和固件,然后硬件设计就要考虑是否要配合结构来设计了。结构外壳设计,结构设计在功能实现上有时有着十分必要的作用。结构也关系到一个创意的完整性。结构我们可以物尽其用,利用身边的一切器物。也可以花上一周时间学一种三维建模软件。例如CAD、SW、PRO\\E、UG等等。

总结
涂鸦零代码实现方案,其实不仅仅局限于对应的一种产品,对于一些创意来讲,只要原理上行得通,不管是开关、传感、数据读取、动作执行的一些创意。都可以根据涂鸦零代码实现方案来“魔改”。你是否也有许多的创意想要实现呢?那就一起来留言分享一下吧!
以上是关于module如何创意写的主要内容,如果未能解决你的问题,请参考以下文章