Mongodb cassandra 和 Mysql对比
Posted 保军Baojun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mongodb cassandra 和 Mysql对比相关的知识,希望对你有一定的参考价值。
MongoDBDB、Cassandra和 mysql对比
1.为什么是Nosql?
1.1 Nosql在大数据处理相对于关系型数据库具有优势
1.1.1
2. 海量的数据和流量:可以支持高效的查询,应对高并发请求。
3. 大规模集群的管理:分布式应用能更简单的部署和管理;
4. 关系型数据库由于存在类似Join这样多表查询机制,使得数据库在扩展方面很艰难;
5. 关系型数据库读写慢:这种情况主要发生在数据量达到一定规模时由于关系型数据库的系统逻辑非常复杂,使得其非常容易发生死锁等的并发问题,所以导致其读写速度下滑非常严重;
2.原理及区别
2.1. Mysql
在不同的引擎上有不同 的存储方式。
查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
mysql采用table和结构化的sql语句来处理数据,在mysql中需要预先定义数据结构schema,并定义table中数据字段的关系。
在mysql中,相关信息可以保存在不同的表中,通过join的形式来保持彼此关联
通用数据库应用广泛,不必多说。缺点就是在海量数据处理的时候效率会显著变慢
2.2 MongoDB
存储方式:虚拟内存+持久化。
查询语句:是独特的MongoDB的查询方式,相关信息由于可以采用灵活的数据结构存储在一块,所以查询速率非常快。
适合场景:事件的记录,内容管理或者博客平台等等。
架构特点:可以通过副本集,以及分片来实现高可用。
数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
优势:
易用性!对开发人员友好。易上手。国内用的较多,文档较全。
快速!在适量级的内存的MongoDB的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快,高扩展!自身的Failover机制!且MongoDB具备高扩展性和延展性和自动分片机制(auto-sharding)。
2.3 Cassandra
(1) 列表数据结构
在混合模式可以将超级列添加到5维的分布式Key-Value存储系统。
(2) 模式灵活
使用Cassandra,不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。
(3) 真正的可扩展性
Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以增加动态添加节点即可。不必重启任何进程,改变应用查询,或手动迁移任何数据。
(4) 多数据中心识别
可以调整节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
(5) 范围查询
如果不喜欢全部的键值查询,则可以设置键的范围来查询。
(6) 分布式写操作
可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
Cassandra写数据时,首先会将请求写入Commit Log以确保数据不会丢失,然后再写入内存中的Memtable,超过内存容量后再将内存中的数据刷到磁盘的SSTable,并定期异步对SSTable做数据合并(Compaction)以减少数据读取时的查询时间。因为写入操作只涉及到顺序写入和内存操作,因此有非常高的写入性能。而进行读操作时,Cassandra支持像LevelDB一样的实现机制,数据分层存储,将热点数据放在Memtable和相对小的SSTable中,所以能实现较高的读性能。
3. 性能对比
[{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5923\', \'name\': u\'Power Init\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'Unassigned\', \'integration_status\': u\'Not Started\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5931\', \'name\': u\'FTPM or TPM Support\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'Unassigned\', \'integration_status\': u\'BugFix Required\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5935\', \'name\': u\'Bios basic ME support\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'Unassigned\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5936\', \'name\': u\'BIOS Device Enablement\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 0.8\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5938\', \'name\': u\'BOOT to UEFI with FW/IFWI\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'Unassigned\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5940\', \'name\': u\'Basic BOOT on Linux\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 0.8\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5949\', \'name\': u\'Intermediate boot\', \'planned_release\': u\'PSS 1.0\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 1.0\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5953\', \'name\': u\'SMBIOS FW Data\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'Unassigned\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5954\', \'name\': u\'Win Basic IO\', \'planned_release\': u\'PSS 1.0\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 1.0\', \'integration_status\': u\'Completed\'},{\'domain\': u\'Boot\', \'jama_id\': u\'IVL-UCIS-5955\', \'name\': u\'Linux BASIC IO\', \'planned_release\': u\'PSS 1.0\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 1.0\', \'integration_status\': u\'Completed\'},{\'domain\': u\'PM\', \'jama_id\': u\'IVL-UCIS-5961\', \'name\': u\'BASIC-Sx-Full_Sleep\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 0.8\', \'integration_status\': u\'Completed\'},{\'domain\': u\'PM\', \'jama_id\': u\'IVL-UCIS-5987\', \'name\': u\'Global-Warm Reset\', \'planned_release\': u\'PSS 0.8\', \'execution_team\': u\'{Select One}\', \'actual_release\': u\'PSS 0.8\', \'integration_status\': u\'Completed\'}]字段:7 数据条数:12 数据集大小:2.6KB 单条数据平均大小:0.08KB操作:1.向3个数据库都插入数据集5W次 合计数据12*5W = 60W条 合计数据大小 130M2. 从60W条数据中查找指定条件的数据(符合的数据5W条,每个数据集中一条符合)3. 修改数据,符合修改要求的数据共5W条结果:
insert find update Mysql 106 s 0.9 s 1.3 MongoDB 37s 0.2 s 1.4 Cassandra 2000+ s 5 s 18s
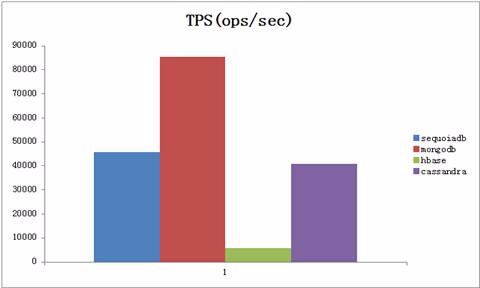

该场景主要模拟50%的插入和50%的查询业务 其中插入业务使用单条记录插入。
最终的结果显示,SequoiaDB的整体表现最优,平均达到每秒钟超过14000TPS,而MongoDB/HBase/Cassandra则比较接近,各自不到10000TPS。
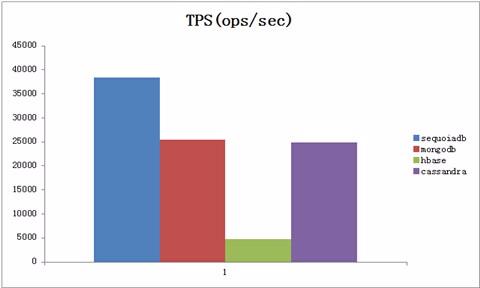
查询最新
查询最新场景为95%读+5%插入,并且读取的数据尽可能是刚刚写入的数据。
从图8中可以看出,SequoiaDB对于刚刚写入至内存中便读取的场景性能最佳,达到近4万每秒。
而MongoDB和Cassandra则相比场景6有明显下降,HBase依然性能较低。
更新为主
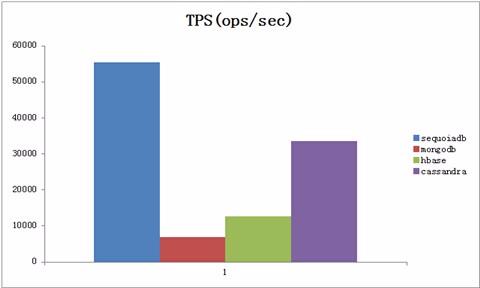
如图6所示,更新为主场景模拟95%更新与5%查询的场景。该场景中,SequoiaDB表现最优,结果介于5万到6万之间每秒。
而MongoDB表现相对较弱,大约在5千每秒左右的数量级。(然而我们实测MongoDB 修改5W条数据用时1.3s)
4. 分析
以上是关于Mongodb cassandra 和 Mysql对比的主要内容,如果未能解决你的问题,请参考以下文章