OpenTSDB 生产应用与思考(转)
Posted AI晓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenTSDB 生产应用与思考(转)相关的知识,希望对你有一定的参考价值。
转自:https://yq.aliyun.com/articles/623275
OpenTSDB 官方介绍
http://opentsdb.net/overview.html
这里就不翻译了。
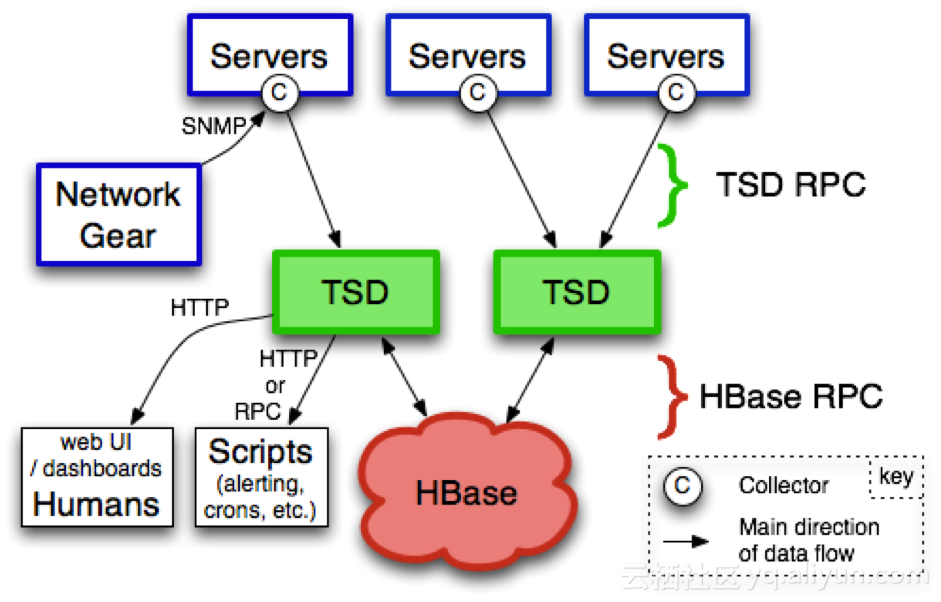
OpenTSDB 应用场景与数据量级
现在的时间序列数据库不仅仅可以提供原始数据的查询,而且要支持对原始数据的聚合能力,支持过滤、过滤之后的聚合计算,这些功能OpenTSDB 都有。架构设计也好,中间件也好,还是数据库,在实际生产场景中,都绕不开数据量级的考虑。OpenTSDB 在数据量小时是可用的,在千万级、亿级中提取几万条数据,比如某个指标半年内的5分钟级别的数据,还是很快响应的。但如果再提取多点数据,几十万,百万这样的量级,又或者提取后再做个聚合运算,OpenTSDB 就勉为其难啦,原因有几点:
【1】OpenTSDB 目前还是单点做聚合运算,我所知道的大的云商如阿里云HiTSDB、数据库在这点做了改造,解决了这个瓶颈。
【2】这样的量级数据从HBase 中提取到单节点内存中进行聚合运算,在资源消耗方面不可忽视。
【3】一个查询一旦提取的量级大,OpenTSDB 向HBase 发起RPC 请求(OpenTSDB 一次请求默认128行)次数也必然增加,十几秒、几十秒的响应时间,这就限制了它的应用场景。
架构中应用OpenTSDB 需要事先考虑
【1】OpenTSDB 只有4 张HBase 表,其中一张是存放数据。所有的数据都存放在一张表,这就意味应用在OpenTSDB 这个层级上是无法更小的粒度来区别对待不同业务(比如想把WebApp 性能指标放在一张表上,OS 性能指标放在一张表上),很难根据业务类别自身特点进行差异化对待后续的运维(比如不同类别设置不同的TTL,数据删除,迁移操作等等)。除非再部署多套OpenTSDB 来对待,这是另外一个话题。
【2】OpenTSDB 不支持二级索引,只有一个基于HBase的RowKey。结合业务场景的查询维度,设计好RowKey 是应用好OpenTSDB 的关键!提前评估好metric + tag 背后扫描的数据量。比如将high-cardinality tag 调整到metric 中,减少扫描的数据量。
【3】OpenTSDB 能实时聚合计算功能,但基于单点运算能力有限,建议这种聚合在入库阶段完成的。比如将1 分钟粒度聚合、5分钟粒度聚合提前通过KafkaStream,Spark 等运算,将聚会结果存入OpenTSDB 供查询。
【4】Tcollector采集数据上报给OpenTSDB,建议在中间加一层Kafka 。一来解偶两者之间的强依赖性,同时保存一段时间采集数据,在OpenTSDB、HBase 不可用(计划性运维、集群故障)时不至于丢失数据,对运维来说也增强了操作上的灵活性。二来可以对采集的原始数据进行二次加工再入OpenTSDB,如粒度聚合运算。
【5】关于salt 启用
时间序列数据的写入,写热点是一个不可规避的问题,当某一个metric 下数据点很多时,则该metric 很容易造成写入热点。从2.2 开始,OpenTSDB 采取了允许将metric 预分桶,预分桶后的变化就是在rowkey 前会拼上一个桶编号(bucket index)。预分桶后,可将某个热点metric 的写压力分散到多个桶中,避免了写热点的产生。而客户端查询OpenTSDB 一条数据,OpenTSDB 将这个请求拆成分桶数个查询到HBase,然后返回桶数个结果集到OpenTSDB 层做合并。对HBase 并发请求相应的也会桶数倍的扩大。
设计时需要结合查询场景,在查询性能和后期热点运维方面,做一个权衡考虑。比如说有个场景,在前端页面上要查询一个业务相关的性能指标(以业务为查询单元),查询的结果以多个图形方式展现出来,要求响应时间快。如果这是一个用户点击查询比较频繁的场景(并发量大),启动了salt,无形加大OpenTSDB和HBase的压力。如果完全关闭salt 的话,写热点问题就加大HBase 的运维难度,极端的话造成整个集群整体性能下降。如果写入吞吐量大的话,建议开启salt,但桶的个数不易太多,2-4个即可,默认是20 个桶。
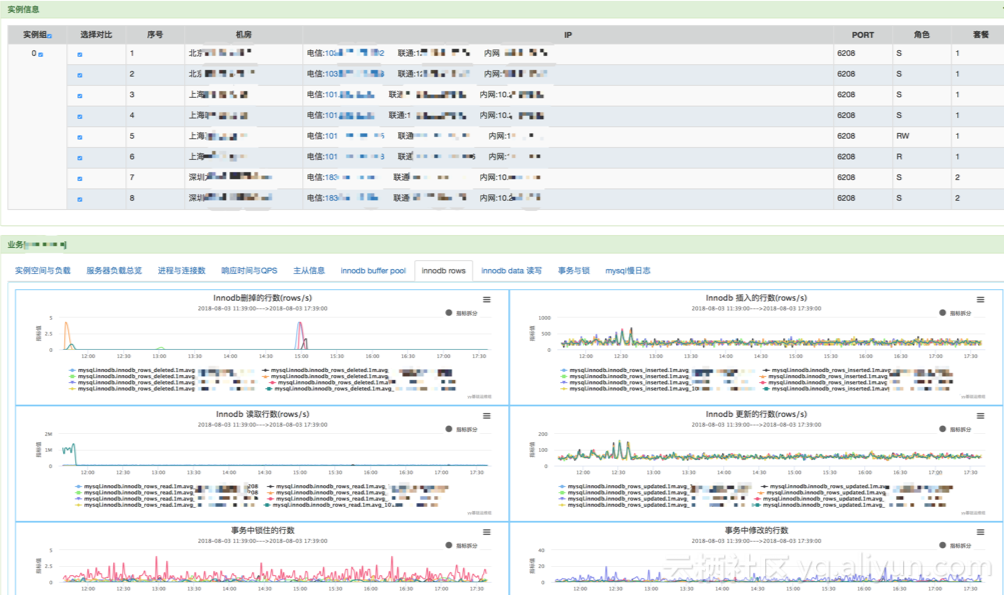
比如查询一个业务AAA的数据库性能指标,如下图:
【6】OpenTSDB 提供三种途径写数据,分别是Telnet API, HTTP API, 批量导入。Telnet 读写是异步操作,但是返回的响应混乱的。HTTP API 是同步读写操作,成功与否能及时反馈,同时多个数据点能在单个端口发送,节省带宽。理论上Telnet 速度好于HTTP,但牺牲了数据是否成功写入的可靠性。在实际生产使用中,建议使用HTTP API,而Telnet API 用于运维。
【7】关于Cache
OpenTSDB 并没有内建的Cache 来存放数据,截止到2.3 还是只能依赖HBase 的Cache。
OpenTSDB 部署与运维方面
【1】OpenTSDB 是Java 实现的,JVM 方面的参数设置、GC、运维管理同样是OpenTSDB 需要考虑的。
【2】生产部署时,往往是多台机器部署,每台机器部署多个实例,读写分离。比如查询实例端口一律使用4242,写数据实例端口一律使用4243,然后读写请求通过nginx + Consul 均衡到各个实例端口上。
【3】设置tsd.storage.hbase.prefetch_meta = true(默认是false),否则极端情况下会打爆hbase:meta 表请求。
【4】2.2 版本开始,tsd 写数据到HBase有两种方式,一种是每来一条数据append 到hbase。另一种是先缓存大量数据到TSD 的内存里,然后进行compaction,一次性写入。官方推荐Append 方式。相关参数tsd.storage.enable_appends = true 。
【5】TSDB 在每小时整点的时候将上个小时的数据读出来(get),然后compact 成一个row,写入(put)到HBase,然后删除(delete)原始数据,目的是减少存储消耗,增大了HBase 压力,性能平稳上出现一定的波动。
【6】若metric, tag含有中文,编译时指定字符集为UTF8。
【7】其他一些注意的参数:
tsd.storage.hbase.scanner.maxNumRow
tsd.query.timeout
以上是关于OpenTSDB 生产应用与思考(转)的主要内容,如果未能解决你的问题,请参考以下文章