如何理解知识图谱中属性和关系的区别?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何理解知识图谱中属性和关系的区别?相关的知识,希望对你有一定的参考价值。
参考技术A如何理解知识图谱中属性和关系的区别?
我借 @SimmerChan 的 回答 评论里的例子延伸一下:
首先, 北京 作为 城市 这个类的实例,接下来考虑:
这两种表示方法到底会有什么区别?本质上二者都没有丢失信息,但是从应用上来讲在支持某些运算时会有性能/逻辑简洁性上的差异。
比如我想要查询:北京有哪些政府机构?那我可能需要同时知道 城市-行政区划 + 行政区划-政府机构 这两个mapping,这时第2种表达要拿到这两个mapping就会比第1种更容易,速度更快。
进一步可以说,属性或关系,或者各位所说的内在和外在关联的划分,并不需要是一个绝对的、本体论上的划分,而是可以(其实是最好) 根据图谱的具体应用需求进行设计 的。
另:事实上表达之所以有多种,是因为面向应用的知识图谱在逻辑上分得还不够细。比如我们考虑:类-实例,类-属性,实例-属性值,属性-属性值之间其实都存在mapping。建模语言RDF中,实体和属性都是节点,而关系则分为实体-实体关系和实体-属性关系,这种设计下也就只有第2种表达了,表达能力更强的语言还有RDFS和OWL(这里有篇简介: 知识图谱技术体系总结 )。
知识图谱——Python操作Neo4j导入CSV文件建立图谱
首先Neo4j是图数据库,最重要的就是结点和边的关系,每两个结点和边都可以看成三元组,主谓宾的关系,当然结点也是可以添加属性的,但是首先要有结点,在添加属性。本片文章就是用简单的方式一次性给大家讲解清楚。
简单起见,我们用西游记师徒四人为例子(手动写的,为了理解),来体现出本章要讲的操作
一、先把人物和关系罗列出来
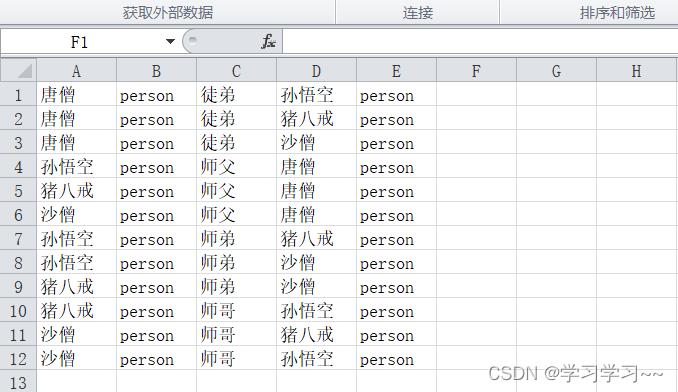
注意,要将文件保存为.csv格式
ps:知识图谱的建立,数据来源主要分为三种,一种是非结构化数据(文本)、半结构化数据(可以爬虫技术在一些网站上获取),结构化数据(关系型数据)。
二、要建立结点,只有有了结点才会有关系,和之后的属性等。代码如下:
from py2neo import Graph, Node, Relationship
import csv
fr= open("G:\\四人关系.csv", mode="r", encoding="gbk") # 如果路径是在工程目录下直接下相对路径,如果不在就写绝对路径
lst = []
node = []
for row in csv.reader(fr):
lst_ = []
lst_.append(row[0])
lst_.append(row[1])
lst_.append(row[2])
lst_.append(row[3])
lst_.append(row[4])
lst.append(lst_)
node.append(row[0]+' '+row[1])
node.append(row[3]+' '+row[4])
# print(lst)
graph = Graph('bolt://localhost:7687',name="neo4j",password="******")
node = set(node) # 消除重复结点
# 建立结点:
for item in node:
shiti,label = item.split()
cypher_ = "CREATE (:" + label + " name:'" + shiti + "') "
graph.run(cypher_)
# 建立关系 :
for item in lst:
cypher_ = "MATCH (a:" + item[1] + "),(b:" + item[4] + ") WHERE a.name = '" + item[0] + "' AND b.name = '" + item[3] + "' CREATE (a)-[r:" + item[2] + "]->(b)"
graph.run(cypher_)建立是先根据第1,2列、4,5列建立结点后,才根据第3列建立的关系,运行后,师徒四人的图谱就建立好了,效果如下图:

三、增加属性
和以上操作一样,现在EXCEL上写好属性,如图(只写了一点),自己做的时候把自己要的属性像这样写清楚:

代码和上面的一样,只是换了cypher语句:
from py2neo import Graph, Node, Relationship
import csv
fr= open("属性.csv", mode="r", encoding="gbk")
lst = []
node = []
for row in csv.reader(fr):
lst_ = []
lst_.append(row[0])
lst_.append(row[1])
lst_.append(row[2])
lst_.append(row[3])
lst.append(lst_)
node.append(row[0]+' '+row[1])
node.append(row[2]+' '+row[3])
graph = Graph('bolt://localhost:7687',name="neo4j",password="******")
for item in lst:
cypher_ = "MATCH (a:" + item[1] + "name:'" + item[0] + "') SET a." + item[2] + " = '" + item[3] +"'"
graph.run(cypher_)运行之后,点击结点就可以看到属性的信息啦。
以上是关于如何理解知识图谱中属性和关系的区别?的主要内容,如果未能解决你的问题,请参考以下文章