大数据是什么?它和Hadoop又有什么联系?
Posted shujuxiong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据是什么?它和Hadoop又有什么联系?相关的知识,希望对你有一定的参考价值。
随着近几年计算机技术和互联网的发展,“大数据”这个名词越来越多进入我们的视野。大数据的快速发展也在无时无刻影响着我们的生活。
那大数据究竟是什么呢?
首先,看看专家是怎么解释大数据的:
大数据就是多,就是多。原来的设备存不下、算不动。 ——啪菠萝·毕加索
大数据,不是随机样本,而是所有数据;不是精确性,而是混杂性;不是因果关系,而是相关关系。—— Schönberger
顾名思义“大数据”,从字面意思来理解就是“大量的数据”。
从技术的的角度来解释,大数据就是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
IBM提出大数据具有5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
我们所谈论的大数据实际上更多是从应用的层面,比如某公司搜集、整理了大量的用户行为信息,然后通过数据分析手段对这些信息进行分析从而得出对公司有利用价值的结果。
比如:头条的推荐机制,就是建立在对海量用户的阅读信息的搜集、分析之上。这就是大数据在现实中具体体现。
那Hadoop又是什么?它和大数据又有什么联系呢?
Hadoop是一个对海量数据进行处理的分布式系统架构,可以理解为Hadoop就是一个对大量的数据进行分析的工具,和其他组件搭配使用,来完成对大量数据的收集、存储和计算。
Hadoop框架最核心的设计就是:HDFS 和 MapReduce。
HDFS为海量的数据提供了存储;MapReduce为海量的数据提供了计算。
一套完整的Hadoop大数据生态系统基本包含这些组件。
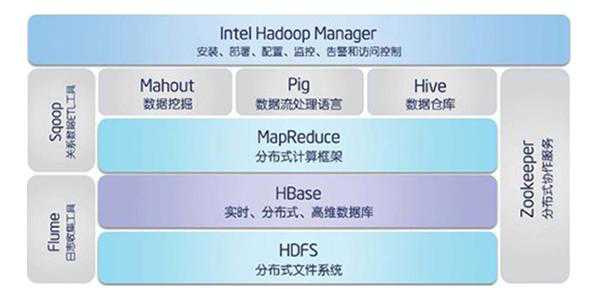
HDFS:Hadoop分布式文件系统,专门存储超大数据文件,为整个Hadoop生态圈提供了基础的存储服务。
MapReduce:分布式离线计算框架,用来处理大量的已经存储在本地的离线数据。
Storm:分布式实时计算,主要特点是实时性,用来处理实时产生的数据。
ZooKeeper:用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
HBase:是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。
Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表。
Sqoop:是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。
Pig:它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
--------------------- 本文来自 扑满心 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/sinat_38648491/article/details/78915306?utm_source=copy
以上是关于大数据是什么?它和Hadoop又有什么联系?的主要内容,如果未能解决你的问题,请参考以下文章