大话Hadoop1.0Hadoop2.0与Yarn平台
Posted 安静的技术控
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大话Hadoop1.0Hadoop2.0与Yarn平台相关的知识,希望对你有一定的参考价值。
2016年12月14日21:37:29
Author:张明阳
博文链接:http://blog.csdn.net/a2011480169/article/details/53647012
参考 ppt:http://pan.baidu.com/s/1eSDnmP8
参考网页:http://www.ittenyear.com/tips/mapreduce/
参考网页:http://www.tuicool.com/articles/NRvie2
近来这几天一直在忙于Hbase的实验,也没有太静下心来沉淀自己,今天打算写一篇关于Hadoop1.0、Hadoop2.0与Yarn的博文,从整体上把握三者之间的联系,博客内容如有问题,欢迎留言指正!OK,进入本文正题……
在开始接触Hadoop的时候,也许大家对于Hadoop是下面的一个概念:Hadoop由两部分组成,一是负责存储与管理文件的分布式文件系统HDFS、二是负责处理与计算的MapReduce的计算框架。即Hadoop通过HDFS既能够存储海量的数据,又能够通过MapReduce实现分布式的一个计算,用一句话来概括Hadoop就是:Hadoop是适合大数据的分布式存储与计算的一个平台。
在这里我们先看一下HDFS的体系结构:
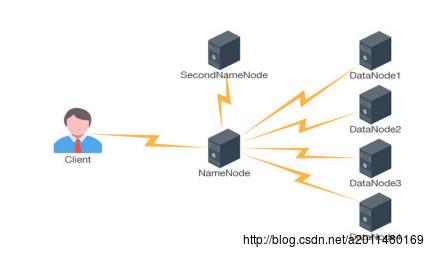
HDFS的体系结构是一个主从式的结构,主节点NameNode只有一个,从节点DataNode有很多个,大家在这里面要注意:主节点NameNode与从节点DataNode实际上指的是不同的物理机器,即有一台机器上面跑的进程是NameNode,很多台机器上面跑的进程是DataNode ,也就是说服务器的角色是由其上面跑的进程的角色决定其是什么类型的服务器,不然大家都是一堆物理机器而已,对于这个概念大家务必要区分清楚。
接下来我们依次讨论HDFS中NameNode、SecondaryNameNode与DataNode在集群中的作用:
NameNode的作用:
1>NameNode管理着整个文件系统,负责接收用户的操作请求
2>NameNode管理着整个文件系统的目录结构,所谓目录结构类似于我们Windows操作系统的体系结构
3>NameNode管理着整个文件系统的元数据信息,所谓元数据信息指定是除了数据本身之外涉及到文件自身的相关信息
4>NameNode保管着文件与block块序列之间的对应关系以及block块与DataNode节点之间的对应关系
用一句话来概括我们的NameNode:NameNode在HDFS中是负责管理工作的。
DataNode的作用:
1>DataNode在HDFS中只做一件事情:存储数据,并且在HDFS中的文件是被切分成block块来进行存储的,这一点不同于我们的Windows,而在HDFS中之所以将文件切分成block块来进行存储,也是为了便于维护与管理。
大家要特别注意一下:在HDFS中,我们真实的数据是由DataNode来负责来存储的,但是数据具体被存储到了哪个DataNode节点等元数据信息则是由我们的NameNode来存储的。
SecondaryNameNode的作用:
SecondaryNameNode在HDFS中只做一件事情:合并NameNode节点中的fsimage和edits,具体合并过程如下图所示:
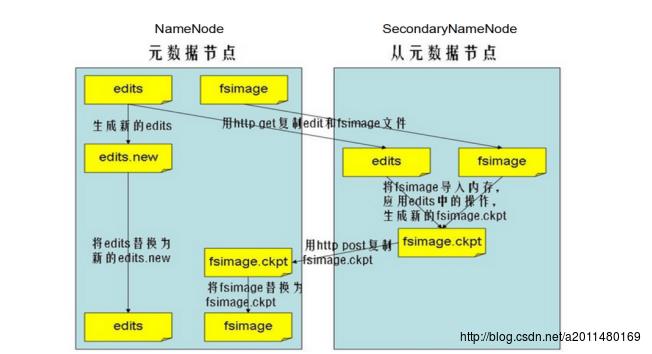
首先,SecondaryNameNode从NameNode中通过网络拷贝一份fsimage与edits到自己进程的那一块,然后将fsimage与edits进行合并,生成新的fsimage,并将新生成的fsimage推送到NameNode节点中一份,并将NameNode中edits的内容进行清空。
大家在这里要注意:NameNode自己之所以不合并fsimage与edits,是为了更快的响应用户的操作请求。
文章写到这里,我们就来思考一下,在Hadoop1.0中的HDFS到底有什么缺陷呢?我们可以总结出一下几点:
1>NameNode中的单点故障问题
2>因为NameNode含有我们用户存储文件的全部的元数据信息,当我们的NameNode无法在内存中加载全部元数据信息的时候,集群的寿命就到头了,我们将这条概括为NameNode的内存容量不足的问题
3>HDFS中的权限设计不够彻底,即HDFS的数据隔离性不是很好
4>如果HDFS大量存储小文件的话,会造成NameNode的内存压力骤增
上面的四点故障在Hadoop2.0中得到了相应的解决,至于如何解决的,我们过一会在谈,在此我们先看一看Hadoop1.0中的MapReduce。
MapReduce是Hadoop1.0中的分布式计算框架,包括两个阶段:Mapper阶段和Reducer阶段,用户只需要实现map函数和reduce函数即可实现分布式计算,非常简单,接下来我们看一看MapReduce的体系结构:
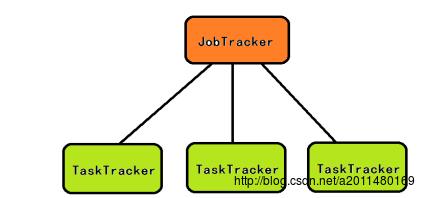
MapReduce的体系结构也是一个主从式的结构,主节点JobTracker只有一个,从节点TaskTracker有很多个,JobTracker与TaskTracker在MapReduce中的角色就像是项目经理与开发人员一样,JobTracker的具体职责如下:
1>JobTracker负责接收用户提交给的计算任务
2>将计算任务分配给我们的TaskTracker进行执行
3>跟踪监控TaskTracker的任务task的执行状况
当然TaskTracker的作用就是执行JobTracker分配给的计算任务task。
现在让我们想一想在Hadoop1.0中MapReduce的缺点:
1>MapReduce中的JobTracker职责过多,既需要分配资源,又需要跟踪监控每一个Job下的tasks的运行情况,这往往造成了内存以及资源的极大浪费
2>对于实时性作业和批处理作业,在Hadoop1.0中需要搭建不同的集群环境,每个集群环境运行不同的作业类型,这往往导致了集群的资源利用率并不高,在实际的业务当中,我们MapReduce处理的主要业务为有些延迟的批处理的作业,也就是说由于1.0中MapReduce的设计导致集群的资源利用率并不高。
好的,带着1.0中的HDFS的缺陷和MapReduce的缺陷我们进入到Hadoop2.0中,我们先谈2.0中的HDFS。
在Hadoop2.0中,针对HDFS1.0中NameNode的内存容量不足以及NameNode的单点故障问题,在2.0中分别作了以下的改进:
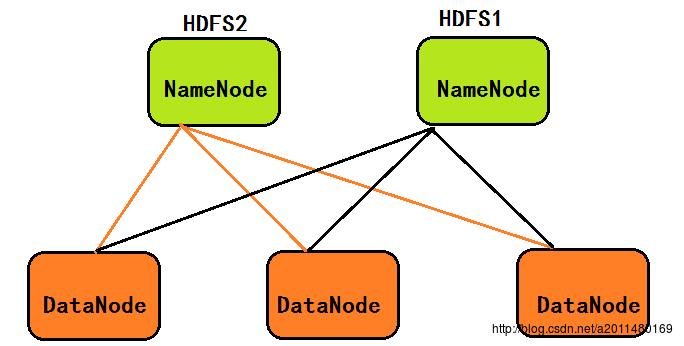
1>在1.0中,既然一个NameNode会导致内存容量不足,我们引入两个NameNode,组成HDFS联邦,这样NameNode存储的元数据信息就可以翻倍了,所谓HDFS联邦就是有多个HDFS集群同时工作,数据节点DataNode存储的数据是服务于两个HDFS文件系统的,体系结构如下图所示:
2>在2.0中,针对1.0中NameNode的单点故障问题,在2.0中引入了新的HA机制:即如果Active的NameNode节点挂掉,处于Standby的NameNode节点将替换掉它继续工作,下面的图示方便大家的理解:
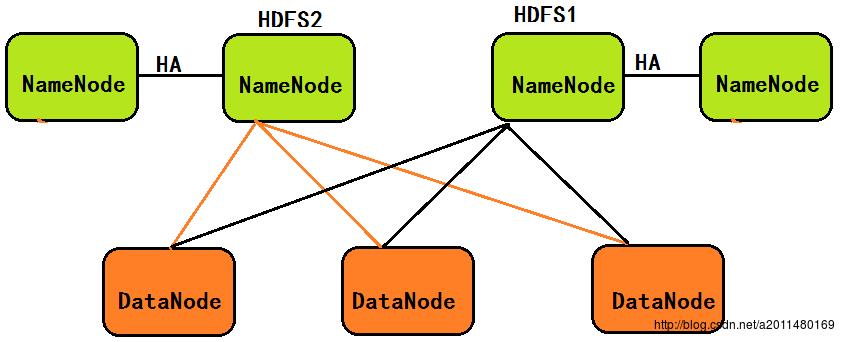
在这里大家一定要注意:2.0中处于HDFS联邦的也是两个NameNode节点,处于HA的也是两个NameNode节点,但是联邦中的两个NameNode节点由于使用的是不同的命名空间(Name Space),因此两个NameNode节点存储的元数据信息并不相同,但是处于HA中的两个NameNode节点由于使用的相同的命名空间,因此两个NameNode节点存储的元数据信息是相同的。
好的,介绍完2.0中的联邦和HA后,我们进入2.0中的MapReduce即2.0中的YARN,在Hadoop2.0中,Yarn平台是2.0的资源管理系统,体系结构如下图所示:
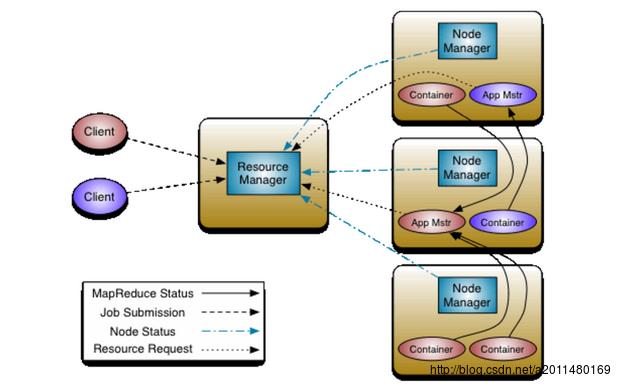
Yarn是Hadoop2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成两个独立的服务:一个是全局的资源管理器ResouceManager和每个应用程序特有的AppMaster。
在Yarn平台中,各个组件的详细功能如下:
1>ResouceManager是一个全局的资源管理器,负责整个系统的资源管理和分配,ResouceManager相当于Hadoop1.0中的JobTracker的部分职能:资源分配。
2>AppMaster负责管理单个应用程序,即负责一个Job生命周期内的所有工作,并在任务task运行失败时重新为任务申请资源进而重新启动相应的任务,AppMaster类似老的框架中的JobTracker的部分职能:任务分配与任务监控。
特别注意:每一个Job(而不是每一种)都有一个相应的APPMaster,APPMaster可以运行在除主节点ResouceManager节点以外的其它机器上,但是在Hadoop1.0中,JobTracker的位置是固定的。
3>NodeManager是每个节点上的资源和任务管理器,一方面:它会定时的向ResouceManager汇报本节点上的资源使用情况和各个Container的运行状态,另一方面:它会接受并处理来自AppMaster的container的启动、停止等各种请求。
讲到这里,和大家谈一谈用户的应用程序(以MapReduce程序为例)在Yarn平台上面的运行机制:
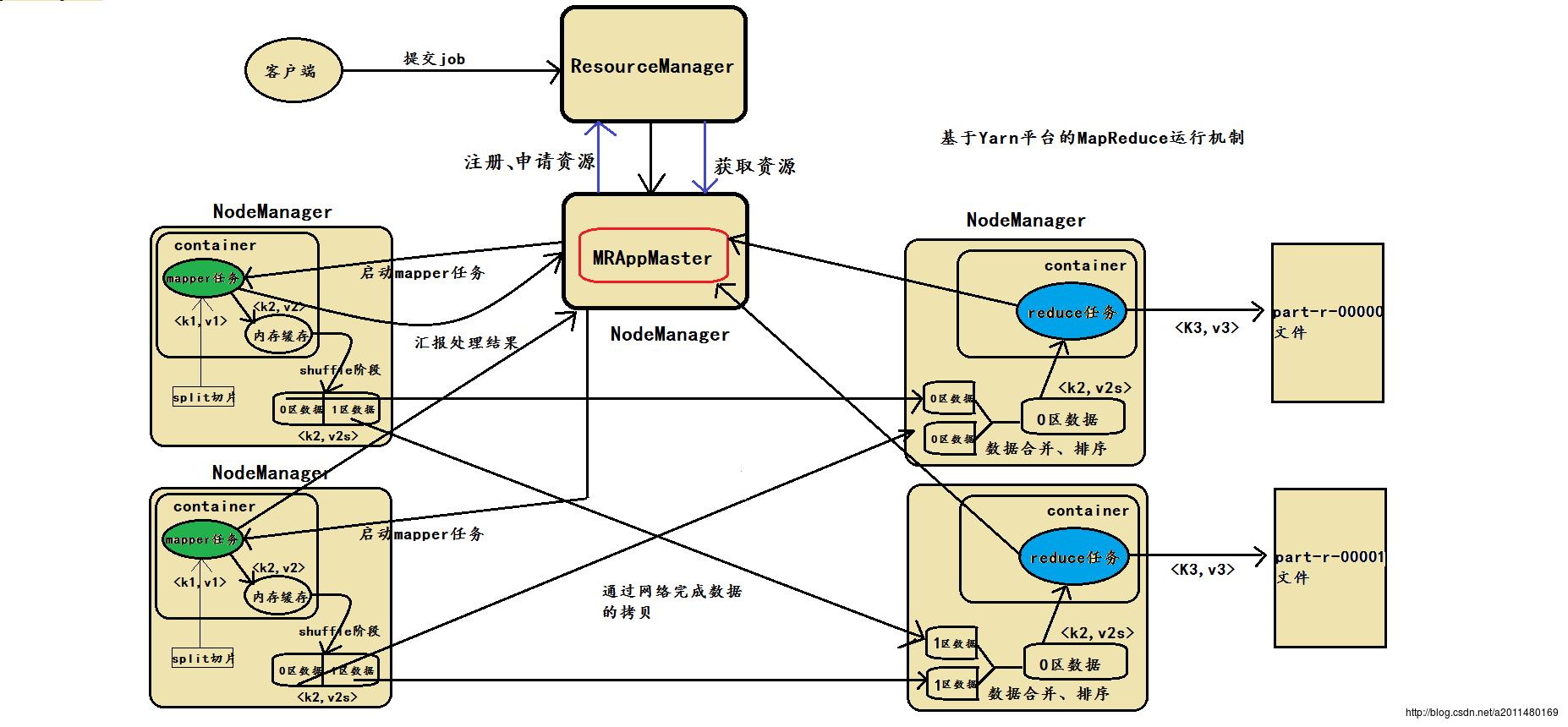
1>首先,用户的应用程序通过Yarn平台的客户端程序将我们的应用程序提交给我们的YARN平台
2>YARN平台的ResouceManager接受到我们客户端提交给的应用程序后,将应用程序交给某个NodeManager,并在其上面启动一个新的进程AppMaster
3>AppMaster首先为应用程序在ResouceManager中进行注册,这样用户可以通过ResouceManager查看应用程序的执行进度
4>注册完之后,APPMaster将通过Rpc协议向ResouceManager申请资源并领取相应的资源
5>获取到资源后,APPMaster便于对应的NodeManager节点进行通信,要求其启动相应的任务
6>各个任务在执行的过程中将通过RPC协议向APPMaster汇报自己的执行进度和执行状况,以便让APPMaster可以随时掌握各个任务的执行状况,进而在任务运行失败时可以重新启动相应的任务。
7>mapper任务和reducer任务执行完之后,AppMaster向ResouceManager节点注销并关闭自己,此时资源得到回收,应用程序执行完毕。
到最后,和大家总结一下YARN框架相比于老的MapReduce框架的4个优势:
1>在Hadoop1.0中,JobTracker的职责过多,既需要分配资源,又需要跟踪监控每一个job下的tasks的执行状况,这往往造成了内存以及资源的极大浪费,在Hadoop2.0中,YARN框架的设计大大减小了JobTracker(也就是现在的ResouceManager)的资源消耗,并且让跟踪监控每一个job下的tasks的执行状况由相应的APPMaster来负责,而在ResouceManager中有一个模块叫做ApplicationsMasters(注意不是ApplicationMaster),它只需要负责跟踪监控每一个ApplicationMaster的运行状况,如果AppMaster运行出现问题,它会在其它机器上重新启动这个进程。
2>在新的YARN平台中,APPMaster是一个可变更的部分,用户可以编写不同类型的应用程序,新的Yarn框架可以让更多类型的编程模型跑在Hadoop集群当中,YARN平台解决了各种不同类型的应用程序可以在同一个平台上面运行的问题。YARN平台的ResouceManager接收到我们客户端提交给的各种类型的应用程序后,各种类型的应用程序将会被YARN平台当做一个普通的应用程序来运行,即在一个YARN平台上面可以运行不同的作业类型。
3>在新的YARN平台中,对于资源的表示以内存为单位,比之前以剩余slot数目更加合理。
4>Container是Yarn为了将来做资源隔离而提出的一个新的框架。
OK,博文就写到这里了,如有问题,欢迎大家留言指正!
以上是关于大话Hadoop1.0Hadoop2.0与Yarn平台的主要内容,如果未能解决你的问题,请参考以下文章