Redis源码解析——字符串map
Posted breaksoftware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码解析——字符串map相关的知识,希望对你有一定的参考价值。
本文介绍的是Redis中Zipmap的原理和实现。(转载请指明出于breaksoftware的csdn博客)
基础结构
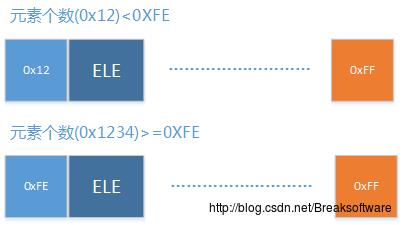
Zipmap是为了实现保存Pair(String,String)数据的结构,该结构包含一个头信息、一系列字符串对(之后把一个“字符串对”称为一个“元素”(ELE))和一个尾标记。用图形表示该结构就是:

Redis源码中并没有使用结构体来表达该结构。因为这个结构在内存中是连续的,而除了HEAD和红色背景的尾标记END(恒定是0xFF)是固定的8位,其他部分都是不定长的。
虽然HEAD信息是定长的,但是其内容表达却是两层意思。HEAD信息是用于保存元素个数信息的。比如该Zipmap只有0x12个元素,则HEAD的内容是0x12。而如果元素个数是0x1234,则内容是0xFE。那这种变化的分界岭是多少?是0xFE。如果元素个数小于0xFE,HEAD内容就是个数值。如果元素个数大于等于0xFE,HEAD内容是0xFE,表示该8位已经不表示元素个数,这个是否如果需要计算元素个数就需要遍历整个结构了。
元素的长度也是不确定的。这点比较好理解,因为元素保存的是一个字符串对,而字符串长度是无法确定的。那么我们再看看元素的结构

元素内容中一开始时记录的Key的长度信息——KeyLen Struct。如果长度小于0xFE,则该结构只有8位长,内容是长度值;如果大于等于0xFE,则该结构是40位长。其中前8位是0xFE,表示本位已经不能表示长度了。后32位则保存长度值
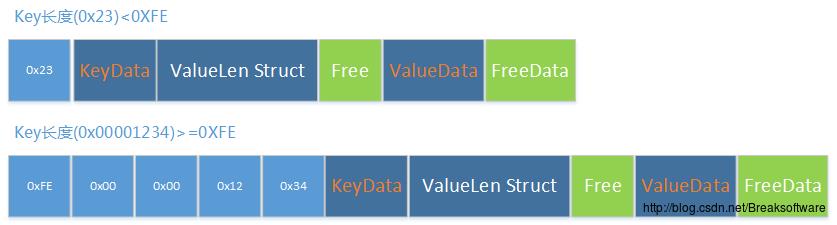
KeyData包含字符串的内容,其内容可以包含NULL,但是不会自动在末尾追加NULL。该规则也符合ValueData。
Key内容之后跟着的是Value的长度信息。其组织方式和Key长度信息的组织方式是一样的。

最后再来说说比较神奇的Free字段。因为Zipmap会提供一个接口,让用户可以通过Key去修改Value的值,如果Value的值被改短了,则会有一定的空余空间,这个空余空间的长度就是Free的值。但是Zipmap就给Free字段留了8位的空间,然而Value修改后空余的长度可能比0xFF还长。其实不用担心,因为如果Zipmap发现如果空余长度超过一定的值就会将之后的空间向前平移以节约空间,而这个阈值比0xFF小
#define ZIPMAP_VALUE_MAX_FREE 4明白上述结构后,阅读后面的代码就变得很简单了。
创建Zipmap
Redis提供了下面方法创建一个空的Zipmap结构。
unsigned char *zipmapNew(void) {
unsigned char *zm = zmalloc(2);
zm[0] = 0; /* Length */
zm[1] = ZIPMAP_END;
return zm;
}因为没有元素,所以长度信息为0。而紧跟其后的便是结尾标记

长度信息编码
Zipmap中元素的Key长度信息和Value长度信息都是需要根据值的大小而动态改变。如果值小于0xFE,则只有8位表示长度,且内容就是长度值。而如果长度大于0xFE,则有40位表示长度信息,其前8位内容是0xFE,后32位是值内容。
static unsigned int zipmapEncodeLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return ZIPMAP_LEN_BYTES(len);
} else {
if (len < ZIPMAP_BIGLEN) {
p[0] = len;
return 1;
} else {
p[0] = ZIPMAP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
return 1+sizeof(len);
}
}
}如果第一个参数传NULL,则该函数是用于根据第二个参数决定需要多长的空间去存储长度信息。如果第一个参数有值,则根据第二个参数决定在该地址的不同偏移位置设置相应的值。
#define ZIPMAP_BIGLEN 254
#define ZIPMAP_END 255
#define ZIPMAP_LEN_BYTES(_l) (((_l) < ZIPMAP_BIGLEN) ? 1 : sizeof(unsigned int)+1)长度信息解码
长度信息解码是对编码做的逆向操作。它判断传入的长度信息起始地址的内容是否小于0xFE。如果是则该8位就是长度值;否则后移8位,之后的32位才是长度值。
static unsigned int zipmapDecodeLength(unsigned char *p) {
unsigned int len = *p;
if (len < ZIPMAP_BIGLEN) return len;
memcpy(&len,p+1,sizeof(unsigned int));
memrev32ifbe(&len);
return len;
}计算Key长度信息和Key内容的整体长度
对应于上图就是计算KeyLen Struct和KeyData的长度和
计算方法就是通过获取的KeyData长度计算出KeyLen Struct的长度,然后将两个长度相加
static unsigned int zipmapRawKeyLength(unsigned char *p) {
unsigned int l = zipmapDecodeLength(p);
return zipmapEncodeLength(NULL,l) + l;
}计算Value长度信息,Free和Value内容的整体长度
对应于上图就是计算ValueLen Struct、Free、FreeData和ValueData的长度和

static unsigned int zipmapRawValueLength(unsigned char *p) {
unsigned int l = zipmapDecodeLength(p);
unsigned int used;
used = zipmapEncodeLength(NULL,l);
used += p[used] + 1 + l;
return used;
}used参数第一次赋值时,它代表ValueLen Struct的长度。于是p[used]取出的就是Free的内容,即FreeData的长度。计算和的操作中再加上1,是Free字段的长度——sizeof(char)。
计算元素长度
只要把上面两个方法一叠加便是元素长度。唯一要做变通的是计算Value相关长度时要让指针指向Value信息的首地址

static unsigned int zipmapRawEntryLength(unsigned char *p) {
unsigned int l = zipmapRawKeyLength(p);
return l + zipmapRawValueLength(p+l);
}
通过Key和Value长度计算保存该元素时需要的最短长度
因为KeyLen Struct和ValueLen Struct的最低长度是一个字节,Free字段占一个字节。于是至少需要如下算法的长度
static unsigned long zipmapRequiredLength(unsigned int klen, unsigned int vlen) {
unsigned int l;
l = klen+vlen+3;但是如果Key或Value的长度大于等于0xFE,则还需要4字节表示真实长度
if (klen >= ZIPMAP_BIGLEN) l += 4;
if (vlen >= ZIPMAP_BIGLEN) l += 4;
return l;
}查找元素、计算Zipmap总长
Zipmap提供了一个方法来完成两个功能。因为这两种方法都需要进行遍历操作,所以索性放在一块。
static unsigned char *zipmapLookupRaw(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned int *totlen) {
unsigned char *p = zm+1, *k = NULL;
unsigned int l,llen;如果Key字段指向一个待对比的字符串,则之后会通过对比查找Key对应的元素首地址。如果totlen不为NULL,则会顺带计算出Zipmap结构的总长。一开始时,p在Zipmap首地址上前进8位是为了过掉HEAD结构,直接指向元素首地址。相似的方法还有
unsigned char *zipmapRewind(unsigned char *zm) {
return zm+1;
}之后要获取Key长度。如果Key长度和传入的klen不一样,则可以肯定的是Key不同,则不需要进行之后的字符串对比。着算是一种优化
while(*p != ZIPMAP_END) {
unsigned char free;
/* Match or skip the key */
l = zipmapDecodeLength(p);
llen = zipmapEncodeLength(NULL,l);对比操作要看Key长度和内容是否都一致。如果一致,则视totlen是否为NULL,决定是否继续遍历。因为totlen为NULL,则说明不需要计算Zipmap总长,这个时候直接返回元素首地址即可。如果不为NULL,则要记录下当前找到的元素首地址到k变量中,这样在之后遍历中,就可以通过变量k知道元素已经找到,不需要进行对比操作了。
if (key != NULL && k == NULL && l == klen && !memcmp(p+llen,key,l)) {
/* Only return when the user doesn't care
* for the total length of the zipmap. */
if (totlen != NULL) {
k = p;
} else {
return p;
}
}如果没有匹配上,则计算Value相关信息的长度。然后跳到下个元素的首地址。
p += llen+l;
/* Skip the value as well */
l = zipmapDecodeLength(p);
p += zipmapEncodeLength(NULL,l);
free = p[0];
p += l+1+free; /* +1 to skip the free byte */
}最后根据totlen是否为NULL,计算Zipmap总长。计算时加1是为了把之前过掉HEAD结构的长度给补上。
if (totlen != NULL) *totlen = (unsigned int)(p-zm)+1;
return k;
}Zipmap还提供了下面的方法计算结构总长,当然它只是对zipmapLookupRaw的封装
size_t zipmapBlobLen(unsigned char *zm) {
unsigned int totlen;
zipmapLookupRaw(zm,NULL,0,&totlen);
return totlen;
}检测元素是否存在
检测的方法也是封装了zipmapLookupRaw,然后判断其是否找到元素的首地址
int zipmapExists(unsigned char *zm, unsigned char *key, unsigned int klen) {
return zipmapLookupRaw(zm,key,klen,NULL) != NULL;
}通过Key获取Value值
首先通过zipmapLookupRaw方法确定该Key在Zipmap中。如果不存在则返回NULL,如果存在则让指针指向Value信息处
int zipmapGet(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned char **value, unsigned int *vlen) {
unsigned char *p;
if ((p = zipmapLookupRaw(zm,key,klen,NULL)) == NULL) return 0;
p += zipmapRawKeyLength(p);
*vlen = zipmapDecodeLength(p);
*value = p + ZIPMAP_LEN_BYTES(*vlen) + 1;
return 1;
}注意这个函数也返回了Value的长度,所以说Value可以存储包含NULL的数据。
遍历Zipmap
遍历前需要调用zipmapRewind让指针指向元素首地址,然后调用下面方法
unsigned char *zipmapNext(unsigned char *zm, unsigned char **key, unsigned int *klen, unsigned char **value, unsigned int *vlen) {
if (zm[0] == ZIPMAP_END) return NULL;
if (key) {
*key = zm;
*klen = zipmapDecodeLength(zm);
*key += ZIPMAP_LEN_BYTES(*klen);
}
zm += zipmapRawKeyLength(zm);
if (value) {
*value = zm+1;
*vlen = zipmapDecodeLength(zm);
*value += ZIPMAP_LEN_BYTES(*vlen);
}
zm += zipmapRawValueLength(zm);
return zm;
}上述方法通过用于接收Key和Value的指针是否为NULL决定是否需要把它们的信息返回出去。其中第10行加1操作实则是过掉Free占用的一个字节。
调用上面函数遍历的方法是:
unsigned char *i = zipmapRewind(my_zipmap);
while((i = zipmapNext(i,&key,&klen,&value,&vlen)) != NULL) {
printf("%d bytes key at $p\\n", klen, key);
printf("%d bytes value at $p\\n", vlen, value);
}获取元素个数
之前我们介绍基础结构时说过。如果元素个数少于0xFE,则结构首地址保存的数值就是元素个数值。如果大于等于0xFE,则要遍历整个结构
unsigned int zipmapLen(unsigned char *zm) {
unsigned int len = 0;
if (zm[0] < ZIPMAP_BIGLEN) {
len = zm[0];
} else {
unsigned char *p = zipmapRewind(zm);
while((p = zipmapNext(p,NULL,NULL,NULL,NULL)) != NULL) len++;
/* Re-store length if small enough */
if (len < ZIPMAP_BIGLEN) zm[0] = len;
}
return len;
}重分配Zipmap空间
重分配操作除了重新分配空间外,还要将结尾符设置。
static inline unsigned char *zipmapResize(unsigned char *zm, unsigned int len) {
zm = zrealloc(zm, len);
zm[len-1] = ZIPMAP_END;
return zm;
}删除元素
删除元素前先需要找到该元素的起始地址
unsigned char *zipmapDel(unsigned char *zm, unsigned char *key, unsigned int klen, int *deleted) {
unsigned int zmlen, freelen;
unsigned char *p = zipmapLookupRaw(zm,key,klen,&zmlen);
if (p) {如果找到,则计算这个元素的长度
freelen = zipmapRawEntryLength(p);然后将该元素之后的内容,除了结尾符0xFE,向前移动到该元素的起始地址
memmove(p, p+freelen, zmlen-((p-zm)+freelen+1));接着重分配Zipmap结构的空间,以节约空间。zipmapResize方法还辅助性的把结尾符给设置上了。
zm = zipmapResize(zm, zmlen-freelen);接着判断元素个数是否在0xFE之内。如果在,则让Zipmap结构首地址对应的数值减少1
/* Decrease zipmap length */
if (zm[0] < ZIPMAP_BIGLEN) zm[0]--;
if (deleted) *deleted = 1;
} else {
if (deleted) *deleted = 0;
}
return zm;
}增加、修改元素
如果通过zipmapSet方法传入的Key在Zipmap中,则是要求修改该Key对应的Value值;如果不在Zipmap中,则是新增元素。
首先通过Key和Value的长度计算出存储该字符串对最少需要多少空间
unsigned char *zipmapSet(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned char *val, unsigned int vlen, int *update) {
unsigned int zmlen, offset;
unsigned int freelen, reqlen = zipmapRequiredLength(klen,vlen);
unsigned int empty, vempty;
unsigned char *p;然后判断Key是否在Zipmap中,并计算出Zipmap的结构总长
freelen = reqlen;
if (update) *update = 0;
p = zipmapLookupRaw(zm,key,klen,&zmlen);如果Key不存在,则需要新增元素。这个时候需要重新给Zipmap分配更大的空间,并将需要新增元素的位置指针指向结尾符——即在尾部追加元素。还要让元素个数自增
if (p == NULL) {
/* Key not found: enlarge */
zm = zipmapResize(zm, zmlen+reqlen);
p = zm+zmlen-1;
zmlen = zmlen+reqlen;
/* Increase zipmap length (this is an insert) */
if (zm[0] < ZIPMAP_BIGLEN) zm[0]++;
}如果Key存在,则是更新Value。这个时候需要计算找到的元素的总长,如果总长比修改后需要的最短长度要短,则需要重新分配Zipmap空间。并把原来元素之后的内容向后平移。
else {
/* Key found. Is there enough space for the new value? */
/* Compute the total length: */
if (update) *update = 1;
freelen = zipmapRawEntryLength(p);
if (freelen < reqlen) {
/* Store the offset of this key within the current zipmap, so
* it can be resized. Then, move the tail backwards so this
* pair fits at the current position. */
offset = p-zm;
zm = zipmapResize(zm, zmlen-freelen+reqlen);
p = zm+offset;
/* The +1 in the number of bytes to be moved is caused by the
* end-of-zipmap byte. Note: the *original* zmlen is used. */
memmove(p+reqlen, p+freelen, zmlen-(offset+freelen+1));
zmlen = zmlen-freelen+reqlen;
freelen = reqlen;
}
}如果当前元素的总长度比修改后需要的最短长度要长,则说明是Value字符串长度要变短。这个时候要计算空余出来的空间是否大于ZIPMAP_VALUE_MAX_FREE,如果大于则要缩减Zipmap结构空间。
empty = freelen-reqlen;
if (empty >= ZIPMAP_VALUE_MAX_FREE) {
/* First, move the tail <empty> bytes to the front, then resize
* the zipmap to be <empty> bytes smaller. */
offset = p-zm;
memmove(p+reqlen, p+freelen, zmlen-(offset+freelen+1));
zmlen -= empty;
zm = zipmapResize(zm, zmlen);
p = zm+offset;
vempty = 0;
} else {
vempty = empty;
}如果空余出来的空间很短,就不要做内存重分配的工作了。这样就是之前结构中Free和FreeData的由来。这也说明FreeData中的数据是不确定的——即它是之前内容的一部分。
最后将Key,Value和Free字段放入相应的空间中
/* Just write the key + value and we are done. */
/* Key: */
p += zipmapEncodeLength(p,klen);
memcpy(p,key,klen);
p += klen;
/* Value: */
p += zipmapEncodeLength(p,vlen);
*p++ = vempty;
memcpy(p,val,vlen);
return zm;
}以上是关于Redis源码解析——字符串map的主要内容,如果未能解决你的问题,请参考以下文章