Server 2012到底比Server 2008强在哪
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Server 2012到底比Server 2008强在哪相关的知识,希望对你有一定的参考价值。
纯从系统上来讲,那确实是2008那个更加占用资源(6.0内核嘛~),我这里两台工作站其中一个配置低的、用的不多的已经让我因尝鲜原因换12r2了。。。不过当你装程序多了、跑程序多了,内存常驻动不动7、8GB,那情况下也就无所谓了。。。追问
相比 2003 那个更加好些呢
回答
这个我想没什么好比的吧,配置够为何不装08r2、12r2?除非你有确实只能在03下跑的东西。。。
新系统安装、维护、扩展等等全方面都比旧系统好啊。
当然,如果升级系统牵扯东西太多太多,03r2又够用、稳定的情况下,你就先这么用吧。 参考技术A 一、简单地说:
1每一个新版本的 SQL Server 都会有一些新的改进,一般称之为新特性。SQL Server 2012的一些新特性是很酷的,但是,对于普通的用户来说,可能根本用不上。但等你需要用上时,你才知道,那是多么的有用。
SQL Server 2012与2008之间差了一个半版本。他们之间的版本变化:
SQL Server 2008->SQL Server 2008R2->SQL Server 2010-SQL Server 2012。
2、要了解SQL Server 2012比SQL Server 2008强在哪儿,你需要将这几个版本的新特性一版本一版本的分析。
3、我仅给你解说一下SQL Server 2012相比上一版本的新特性吧。因为多数人并不需要了解这些,或者说,了解这些也并不能对一般人有什么帮助。
二、SQL Server 2012新特性:
(我添加上了本俗人粗浅的理解,说错了不能怪我,水平有限。此外估计一般人最多能用上的就前面几条)
1. AlwaysOn Availability Groups
简单理解:可以同时进行多个组的故障转移。以前版本是单一个数据库故障转移。
2. Windows Server Core Support
简单理解:Windows2008之后的Windows server可以只安装核心部分,不安装界面。在这种环境下,SQL Server 2012也能进行安装使用了,以前的版本是不可以的。
3. Columnstore Indexes
新增了一种特殊类型的只读索引专为数据仓库查询设计。在大规模的查询情况下可极大的减少I/O和内存利用率。
4. User-Defined Server Roles
可以创建在服务器上具备所有数据库读写权限以及任何自定义范围角色的能力。用户角色管理加强,可以定义某组用户多个数据库的权限。以前的版本只能一个一个数据库设定。
5. Enhanced Auditing Features
审计功能相关,在SQL Server 2012中提供过滤功能,同时大幅提高灵活性。
6.BI Semantic Model
BI Semantic Model代替了ASUDM(Analysis Services Unified Dimensional Model ),数据挖掘与分析方面的东西,一般人弄不懂它的改进。
7. Sequence Objects
Sequence是数据中一个特殊存放等差数列的表,该表受数据库系统控制,任何时候数据库系统都可以根据当前记录数大小加上步长来获取到该表下一条记录应该是多少,这个表没有实际意义,常常用来做主键用。以前SQL Server只有自增类型。
8. Enhanced PowerShell Support
在SQL Server 2012中增加了更多的cmdlet。通俗说,就是增加了很多在CMD窗中用命令行处理的功能。
9. Distributed Replay
Distributed replay功能可让管理员记录服务器上的工作负载,并在其他的服务器上重现。这种在底层架构上的变化支持包以及在生产测试环境下对硬件更改。具体怎么用,估计一般人很难搞懂。
10. PowerView
允许用户创建企业级的商务智能报告。
11. SQL Azure Enhancements
这个,云服务。让SQL数据库直接到微软的云上面去。
12. Big Data Support
大数据支持。到底怎么个支持法,不知道,也许只是概念炒作。
数据结构初探
理解程序的本质
- 程序是为了实际的问题而存在
- 从本质上而言,程序是解决问题的步骤描述
首先理解实际问题
- 确认问题类型
- 确认求解的步骤
程序评鉴初探
- 用尽量少的内存空间解决问题
- 用尽量少的步骤解决问题
小结
- 程序是为了具体问题而存在的
- 程序需要围绕问题的解决进行设计
- 同一个问题可以有多种解决方案
数据结构起源
??数据结构主要研究非数值计算程序问题中的操作对象以及它们之间的关系。
- 计算机从解决数值计算问题到解决生活中的问题
- 现实生活中的问题涉及不同个体间的复杂联系
- 需要在计算机程序中描述生活中个体间的联系
关键概念
- 数据 – 程序的操作对象,用于描述客观事物 ,用于描述客观事物
- 数据的特点:
- 可以输入到计算机
- 可以被计算机程序处理
- 数据元素 – 组成数据的基本单位
- 数据项:一个数据元素由若干数据项组成 :一个数据元素由若干数据项组成
- 数据对象 – 性质相同的数据元素的集合
struct Student ===> 一种数据类型
{
char* name;
int age;
};
struct Student s; ===> 数据元素
struct Student stu[100]; ===> 数据对象
s.name = "delphi Tang"; ===> 数据项
s.age = 30;- 数据元素之间不是独立的,存在特定的关系,这些关系即结构
- 数据结构指数据对象中数据元素之间的关系
- 如:数组中各个元素之间存在固定的线性关系
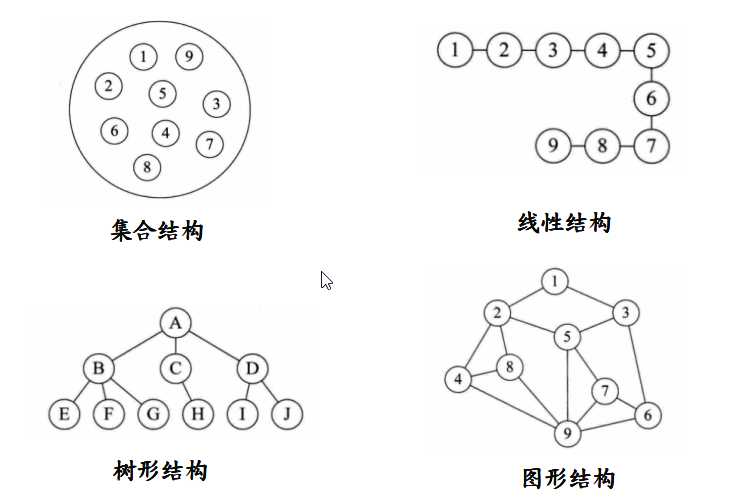
逻辑结构
- 集合结构
- 数据元素之间没有特别的关系,仅同属相同集合
- 线性结构
- 数据元素之间是一对一的关系
- 树形结构
- 数据元素之间存在一对多的层次关系
- 图形结构
- 数据元素之间是多对多的关系
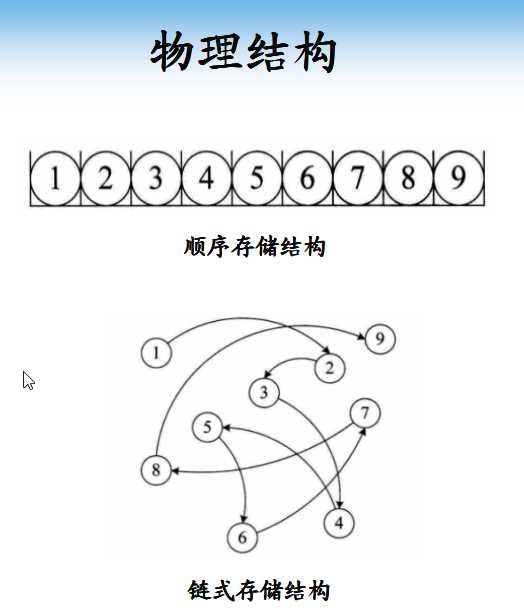
物理结构
??物理结构,逻辑结构在计算机中的存储形式
- 顺序存储结构
- 将数据存储在地址连续的存储单元里
- 链式存储结构
- 将数据存储在任意的存储单元里,通过保存地址的方式找到 ,通过保存地址的方式找到相关联的数据元素
小结
- 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
- 按照视点的不同,数据结构可以分为逻辑结构和物理 ,数据结构可以分为逻辑结构和物理结构。
| 逻辑结构 | 物理结构 |
|---|---|
| 集合结构 | 顺序结构 |
| 线性结构 | 链接结构 |
| 树形结构 | |
| 图形结构 |
算法
数据结构与算法
- 数据结构只是静态的描述了数据元素之间的关系
- 高效的程序需要在数据结构的基础上设计和选择算法
高效的程序 = 恰当的数据结构 + 合适的算法
算法的定义
- 算法是特定问题求解步骤的描述
- 在计算机中表现为指令的有限序列
- 算法是独立存在的一种解决问题的方法和思想
- 对于算法而言,语言并不重要,重要的是思想
算法的特性
- 输入
- 算法具有0个或多个输入
- 输出
- 算法至少有1个或多个输出
- 有穷性
- 算法在有限的步骤之后会自动结束而不会无限循环
- 确定性
- 算法中的每一步都有确定的含义,不会出现二义性 ,不会出现二义性
- 可行性
- 算法的每一步都是可行的
算法设计的准则
- 正确性
- 算法对于合法数据能够得到满足要求的结果
- 算法能够处理非法输入,并得到合理的结果 ,并得到合理的结果
- 算法对于边界数据和压力数据都能得到满足要求的结果
- 注意:
- 正确性是算法最需要满足的基本的准则,但是作为计算机程序,不可能无限制的满足这条准则 ,不可能无限制的满足这条准则。
算法设计的准则
- 可读性
- 算法要方便阅读,理解和交流
- 健壮性
- 算法不应该产生莫名其妙的结果
- 高性价比
- 利用最少的时间和资源得到满足要求的结果
- 注意:
- 算法可读性是最容易被忽视的,然而,程序是写给人看的,而不是计算机 ,而不是计算机。
小结
- 算法是为了解决实际问题而设计的
- 数据结构是算法需要处理的问题载体
- 数据结构与算法相辅相成
程序 = 数据结构 + 算法
审判程序的灵魂
算法效率的度量
事后统计法
- 比较不同算法对同一组输入数据的运行处理时间
- 缺陷
- 为了获得不同算法的运行时间必须编写相应程序
- 运行时间严重依赖硬件以及运行时的环境因素
- 算法的测试数据的选取相当困难
事后统计法虽然直观,但是实施困难且缺陷多 ,但是实施困难且缺陷多,一般不予考虑。
事前分析估算
- 依据统计的方法对算法效率进行估算
- 影响算法效率的主要因素
- 算法采用的策略和方法
- 问题的输入规模
- 编译器所产生的代码
- 计算机执行速度
算法效率的简单估算



- 启示
- 练习中的程序关键部分的操作数量为n*n
- 三种求和算法中求和的关键部分的操作数量分别为2n, n和1
??随着问题规模n的增大,它们操作数量的差异 ,它们操作数量的差异会越来越大,因此实际算法在时间效率上的 ,因此实际算法在时间效率上的差异也会变得非常明显!
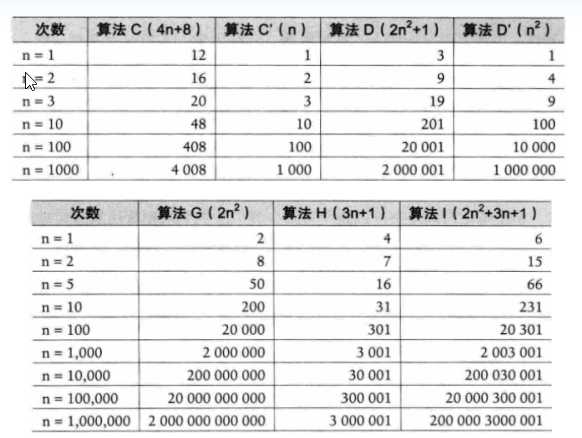
??判断一个算法的效率时,往往只需要关注操作数量的 ,往往只需要关注操作数量的
最高次项,其它次要项和常数项可以忽略 ,其它次要项和常数项可以忽略。
大O表示法
- 算法效率严重依赖于操作(Operation)数量
- 在判断时首先关注操作数量的最高次项
- 操作数量的估算可以作为时间复杂度的估算
O(5) = O(1)
O(2n + 1) = O(2n) = O(n)
O(n2 + n + 1) = O(n2)
O(3n3+1) = O(3n3) = O(n3)常见时间复杂度类型
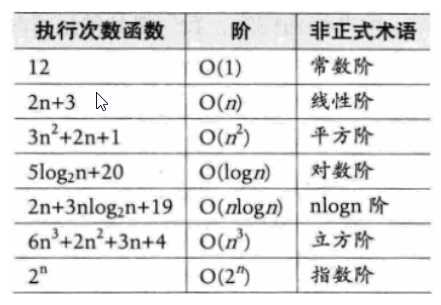
- 关系
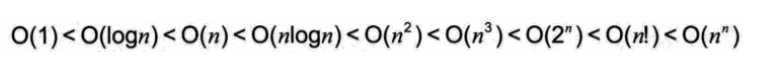
??在没有特殊说明时,我们所分析的算法的时 ,我们所分析的算法的时间复杂度都是指最坏时间复杂度。
算法的空间复杂度
??算法的空间复杂度通过计算算法的存储空间实现
S(n) = O(f(n))
其中,n为问题规模,f(n)为在问题规模为 为在问题规模为n时所占用存储空间的函数大O表示法同样适用于算法的空间复杂度 表示法同样适用于算法的空间复杂度
当算法执行时所需要的空间是常数时,空间复杂度为 ,空间复杂度为O(1)
空间与时间的策略
- 多数情况下,算法执行时所用的时间更令人关注 ,算法执行时所用的时间更令人关注
- 如果有必要,可以通过增加空间复杂度来降低时间复杂度 ,可以通过增加空间复杂度来降低时间复杂度
- 同理,也可以通过增加时间复杂度来降低空间复杂度
??在实现算法时,需要分析具体问题对执行时间和空间的要求。
空间换时间 ? 时间换空间?
以上是关于Server 2012到底比Server 2008强在哪的主要内容,如果未能解决你的问题,请参考以下文章