delphi 运行和开发效率高吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了delphi 运行和开发效率高吗?相关的知识,希望对你有一定的参考价值。
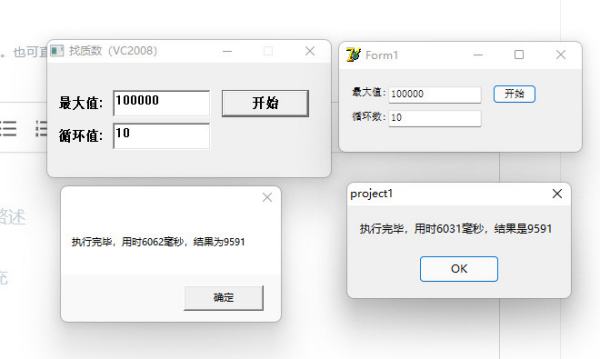
就拿数据说话!看这个查找质数的程序,分辨用VC2008和Delphi7编写的,相对而言Delphi7更古老,早了6年,但运行效率丝毫不比VC差,循环10次VC耗时6062毫秒,Delphi耗时6031毫秒,几乎一致,这点差距完全属于误差范畴。
下面那个什么“极天异云”就是个Delphi黑,毫无常识,什么Delphi速度低10倍,笑死人!
初学疑惑开发者工具可信度高吗?Python爬虫实战场景
本篇博客是一个小小的 Python 爬虫实践,重点为解释在 Python 爬虫实战过程中,浏览器的开发者工具和代码抓取的网页源码,存在数据差异。
翻译一下就是开发者工具和爬虫采集到的源码,不一样。
本次案例来源为 《Python 爬虫 120》 专栏订阅者,5 年保爬虫更新。
⚡⚡ 学习注意事项 ⚡⚡
文章会自动省略http和https协议,学习时请自行在地址中进行补充。
目标站点域名为uisdc.com,在下文统一用橡皮擦代替,学习时请自行拼接。
文章目录
⛳️ 实战场景
如果你的目标是采集前文提及的站点,那你会碰到下述场景。使用开发者工具的【选择元素】操作时,选中目标元素,得到的 element 节点如下所示。
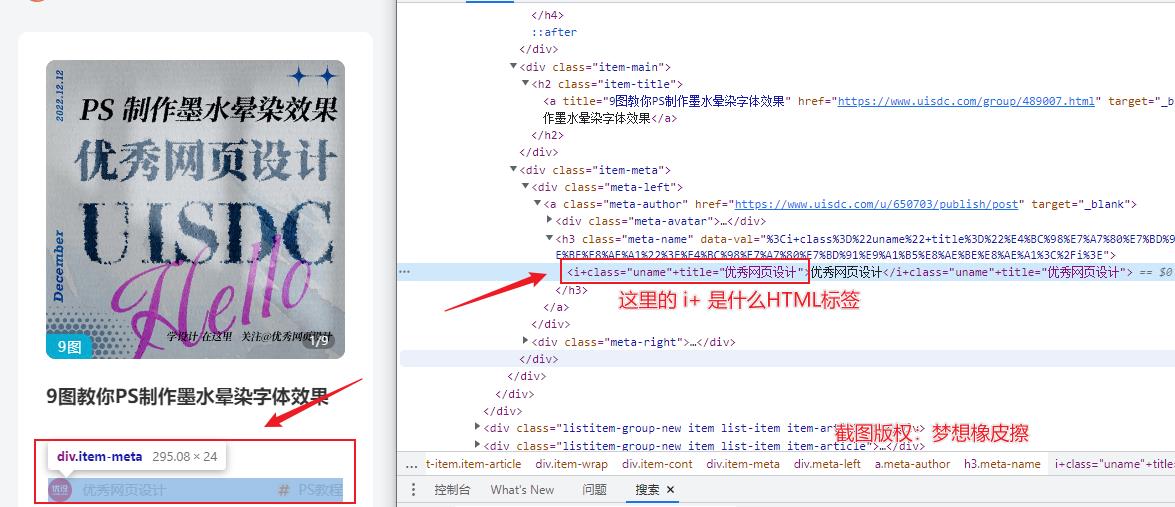
选定目标后,将得到一个名为 i+ 的标签。许多刚刚学习 Python 爬虫的爱好者可能不太了解这个标签的含义,这可能导致无法进行采集。
该标签其实是由前端 JS 脚本渲染而成,HTML 中并没有该标签,但我们要采集的目标文字是 “优秀网页设计”
使用下述代码进行尝试,为了使初学者也可以看懂,这里罗列详细步骤。
首先,我们需要在代码中导入 requests 库。在 Python 中,可以使用 import 关键字来实现这一点。
import requests
接下来,我们可以使用 requests 库中的 get() 方法来发起 HTTP 请求,并获取 橡皮擦.com/archives 网页的内容。
response = requests.get("https://www.uisdc.com/archives")
获取到网页内容后,我们可以使用 response.text 属性来获取网页的内容。
content = response.text
最后,我们可以打印出采集到的内容,以便查看采集到的数据。
print(content)
整个代码如下:
import requests
response = requests.get("https://www.uisdc.com/archives")
content = response.text
print(content)
如果您想要保存上文中采集到的网页源码,可以使用 Python 中的文件操作来实现。
首先,我们需要打开一个文件,并使用 write 方法将内容写入文件中。
with open("ca_demo.html", "w") as file:
file.write(content)
在这里,我们使用了 Python 中的 with 关键字,以便在打开文件后自动关闭文件。我们指定了文件名为 "ca_demo.html",并使用了 "w" 模式来打开文件,这意味着我们将向文件中写入内容。
接下来,我们调用 file.write 方法将网页源码写入文件中。
最后,在 with 块结束后,文件会自动关闭。
整个代码如下:
import requests
response = requests.get("https://www.uisdc.com/archives")
content = response.text
with open("ca_demo.html", "w") as file:
file.write(content)
这样,就可以在当前目录下找到名为 "ca_demo.html" 的文件,里面包含了采集到的网页源码。
这时就会碰到刚刚的问题,在 "ca_demo.html" 中检索 优秀网页设计 这几个字,根本找不到,而且 i+ 元素节点也找不到。
再回到开发者工具,在 i+ 节点前面的位置找到 data-val 内容,如下所示。
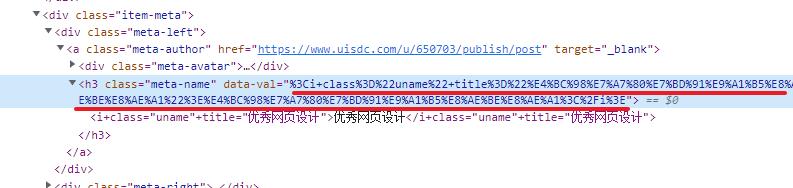
上图划线位置的开头可以看到这样的文字 %3Ci+class,了解过文字编码的同学,可以知道 %3C = <,这里的 % 关键字标识此处应用的是 URL 编码。
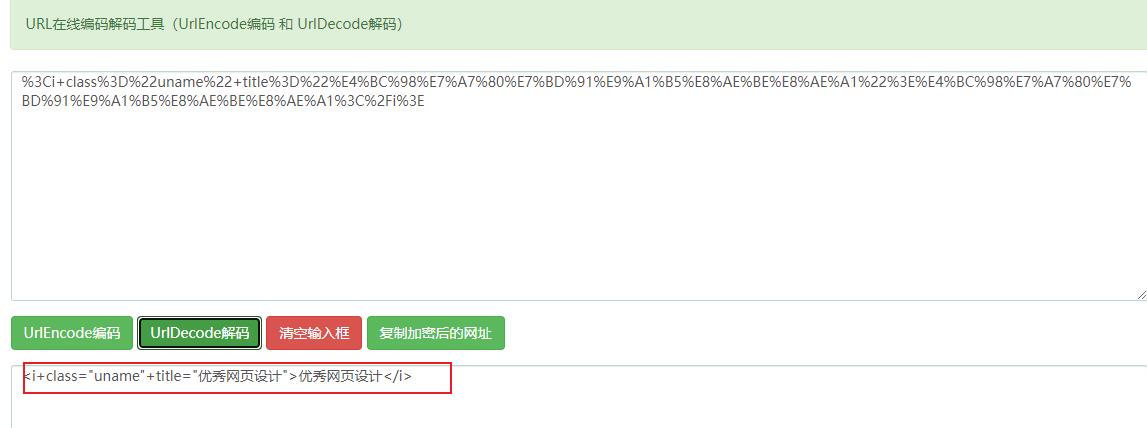
所以将 data-val 内容进行解码之后,得到下述信息。
<i+class="uname"+title="优秀网页设计">优秀网页设计</i>
到这里本 Python 爬虫案例已经可以继续实施了,在网站返回的源码中,搜索前文被 URL 编码过的数据,就可以进行数据的抓取了,当然,需要对得到的内容进行 URL 解码,示例代码如下。
import urllib.parse
decoded = urllib.parse.unquote("%3Ci+class%3D%22uname%22+title%3D%22%E4%BC%98%E7%A7%80%E7%BD%91%E9%A1%B5%E8%AE%BE%E8%AE%A1%22%3E%E4%BC%98%E7%A7%80%E7%BD%91%E9%A1%B5%E8%AE%BE%E8%AE%A1%3C%2Fi%3E")
print(decoded)
这里用到的是 urllib.parse 模块,提前导入模块,然后使用 urllib.parse.unquote() 方法来解码 URL 中的特殊字符。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 791 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于delphi 运行和开发效率高吗?的主要内容,如果未能解决你的问题,请参考以下文章