超详细 Hadoop 2.7.4 Installation Procedure
Posted mrchis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细 Hadoop 2.7.4 Installation Procedure相关的知识,希望对你有一定的参考价值。
∑工作快两年了,一直没有个自己的技术博客啥的,感到很惭愧,每次遇到问题都是百度大神的文章,今天是周日,我也想写点我一直学习成长中遇到的问题和 解决方法,今天我就拿这个hadoop2.7.4开刀吧,至少我再这个配置上卡住了很久。拿出来给大家分享一下
-------------------------------------------------------------------------------------------------------------------------------
这次主要讲的是hadoop2.7.4的安装和一些需要的环境
hadoop2.7.4 vm12 centos 6.5 jdk1.8
下面红色字为修改的文件和命令 蓝色字为修改的内容
*如果没有软件的可以百度一下或者直接问我要
1.在root账户下设置hosts
#>vim /etc/hosts
192.168.1.35 master
192.168.1.36 slave1
文件原有的东西不用动加上,上面的内容 保存退出 [ESC] [:wq!]
2.设置主机名
#>vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
同上保存退出 在slave1机器上也同样设置
然后 重启所有虚拟机
#>shutdown -r now
3.ssh key配置
[[email protected] ~]# ssh-keygen -t rsa 然后一路回车 [[email protected] ~]# cd ~/.ssh/ [[email protected] .ssh]# cat id_rsa.pub >>authorized_keys
[[email protected] .ssh]# scp ./id_rsa.pub [email protected]:$PWD 然后输入slave1的密码就可以了,在slave1上执行下面的命令
[[email protected]~]# cd ~/.ssh/
[[email protected] .ssh]# cat id_rsa.pub >>authorized_keys 到此 ssh就配置好了master无密码访问slave1了 **slave1访问master还是 需要密码的
4.配置hadoop2.7.4【只需要在master配置完了,复制到其他节点就可以了】
主要配置以下几个文件:
下面所修改的文件都在一个目录下面我就不在累述了
[[email protected] hadoop]# pwd
/opt/software/hadoop-2.7.4/etc/hadoop
[[email protected] hadoop]# vim core-site.xml
core-site.xml
hadoop-env.sh
hdfs-site.xml
mapred-env.sh
mapred-site.xml
slaves
yarn-env.sh
yarn-site.xml
上传hadoop2.7.4 jdk1.8 到linux /opt/software 目录下 不管用啥方法给他整上去就行了,opt目录下是没有software的需要你自己创建一个 mkdir -p /opt/software
然后 解压文件hadoop2.7.4 jdk1.8
[[email protected] software]#tar -zxvf hadoop-2.7.4.tar [[email protected] software]#tar -zxvf jdk***.tar
修改文件
core-site.xml
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>设定namenode的主机名及端口(建议不要更改端口号)</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-2.7.4/tmp</value>
<description> 存放临时文件的目录 </description>
</property>
</configuration>
hadoop-env.sh
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_144 将25行的#去掉填上正确的路径
hdfs-site.xml
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/software/hadoop-2.7.4/hdfs/name</value>
<description> namenode 用来持续存放命名空间和交换日志的本地文件系统路径 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/software/hadoop-2.7.4/hdfs/data</value>
<description> DataNode 在本地存放块文件的目录列表,用逗号分隔 </description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description> 设定 HDFS 存储文件的副本个数,默认为3 </description>
</property>
</configuration>
mapred-env.sh
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/mapred-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_144 将16行的java_home填写正确
mapred-site.xml
一般这个文件在2.7版本以上是没有的需要修改一下 在复制我的代码上去就可以了
[[email protected] hadoop]#cp /opt/software/hadoop-2.7.4/etc/hadoop/mapred-site.xml.template /opt/software/hadoop-2.7.4/etc/hadoop/mapred-site.xml
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
slaves 这个文件配置上所有节点的主机名 这里我就开了2个虚拟机 所以就2个都写上了
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/slaves
master
slave1
yarn-env.sh
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_144 在代码23行补全这个java_home的配置
最重要的就是下面这个文件了 我捅咕了好久才知道他出来问题,因为这个hadoop的版本升级以后yarn所需要的资源默认情况下虚拟机是满足不了的,所以你star-all.sh 也好start-yarn.sh也好nodemanager起来就掉了
yarn-site.xml
[[email protected] software]# vim /opt/software/hadoop-2.7.4/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>如果nodemanager没有启动将下面的参数加上</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
到此hadoop的配置文件已经修改好了需要创建文件夹来保存他生产出来的日志、data信息、name信息
在hadoop-2.7.4的根目录下创建 tmp hdfs/name hdfs/data
[[email protected] hadoop-2.7.4]# mkdir -p hdfs/name [[email protected] hadoop-2.7.4]# mkdir -p hdfs/data [[email protected] hadoop-2.7.4]# mkdir tmp
最后剩下的就是配置环境变量啦 在文件内容最下方添加下面的代码
[[email protected] ~]# vim /etc/profile export JAVA_HOME=/opt/software/jdk1.8.0_144 export HADOOP_HOME=/opt/software/hadoop-2.7.4 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
记住记住
[[email protected] ~]# source /etc/profile
[[email protected] ~]# scp -r /opt/software/hadoop-2.7.4 [email protected]:/opt/software/ 在slave1上也要建立software文件夹 也需要将环境变量配置好同上也好source
[[email protected] ~]# scp -r /opt/software/jdk1.8.0_144 [email protected]:/opt/software/ 在slave1上也要建立software文件夹 也需要将环境变量配置好同上也好source
5.格式化集群
[[email protected] ~]# hdfs namenode -format
如果报错了,看日志,就在创建的文件夹下,新手最好不要手打配置文件,但是手打配置文件是好习惯 往往会提示 你的标签没有关闭 或者是标签错误
6.启动集群
[[email protected] ~]# start-all.sh
这是一个组合命令,start-dfs.sh and start-yarn.sh
单独启动hdfs =>> start-dfs.sh
单独启动yarn =>> start-yarn.sh
7.1 查看进程并验证
[[email protected]master software]# jps
17315 Jps
12854 SecondaryNameNode
12535 NameNode
13592 RunJar
13161 NodeManager
13037 ResourceManager
12671 DataNode
[[email protected]slave1 ~]# jps 6336 DataNode 6452 NodeManager 6716 Jps
7.2 hdfs的web界面验证 地址栏里输入:master:50070
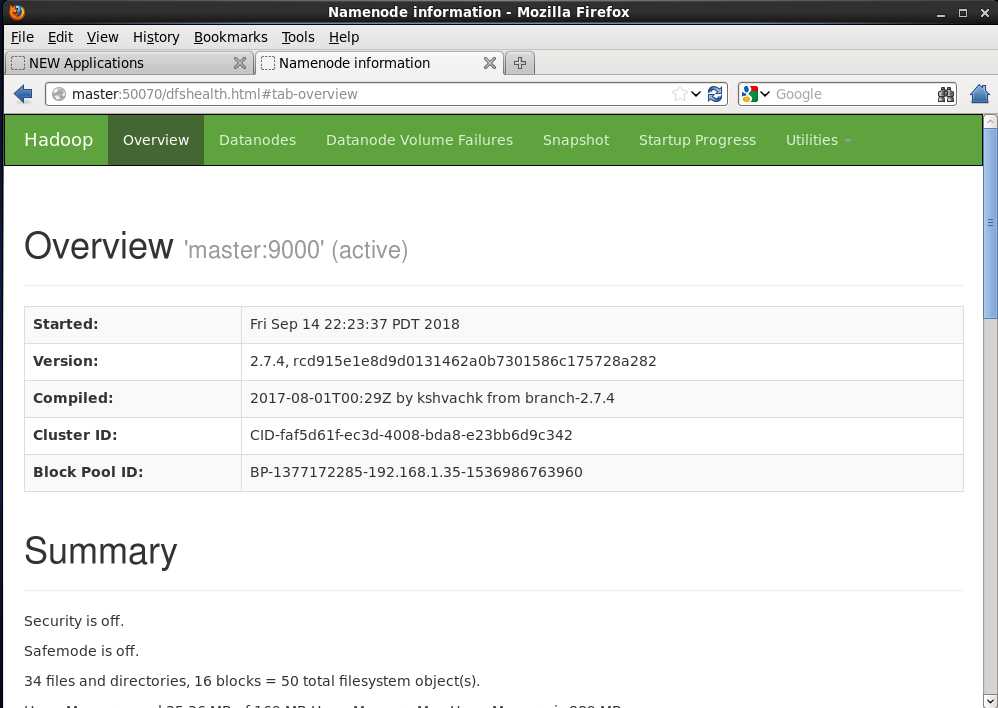
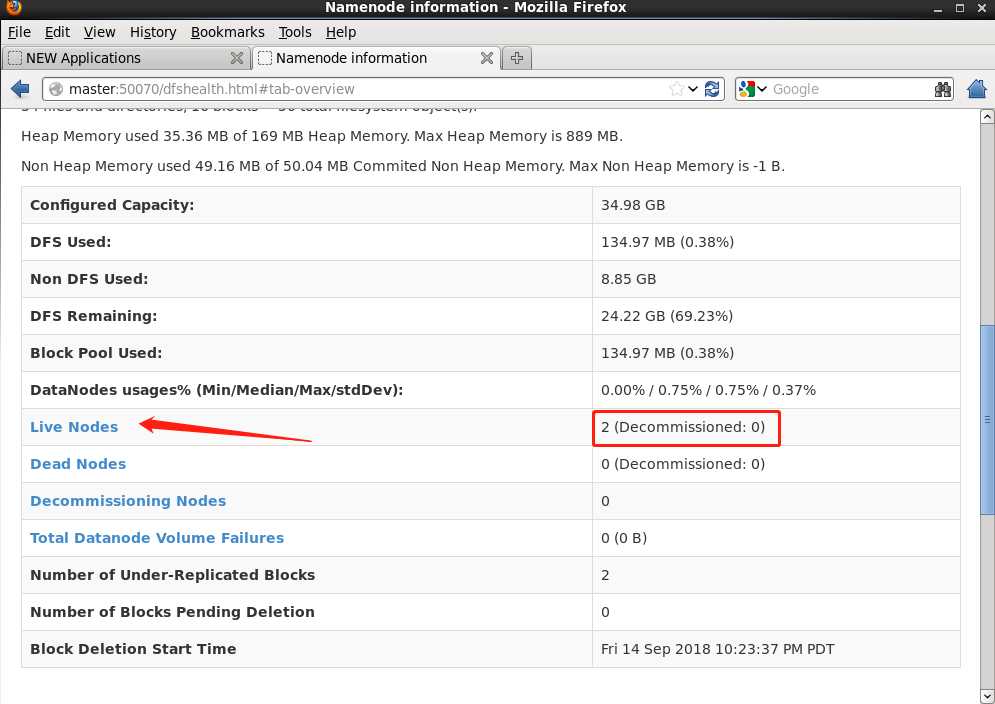
继续往下找会看到活跃的节点和dead的节点数
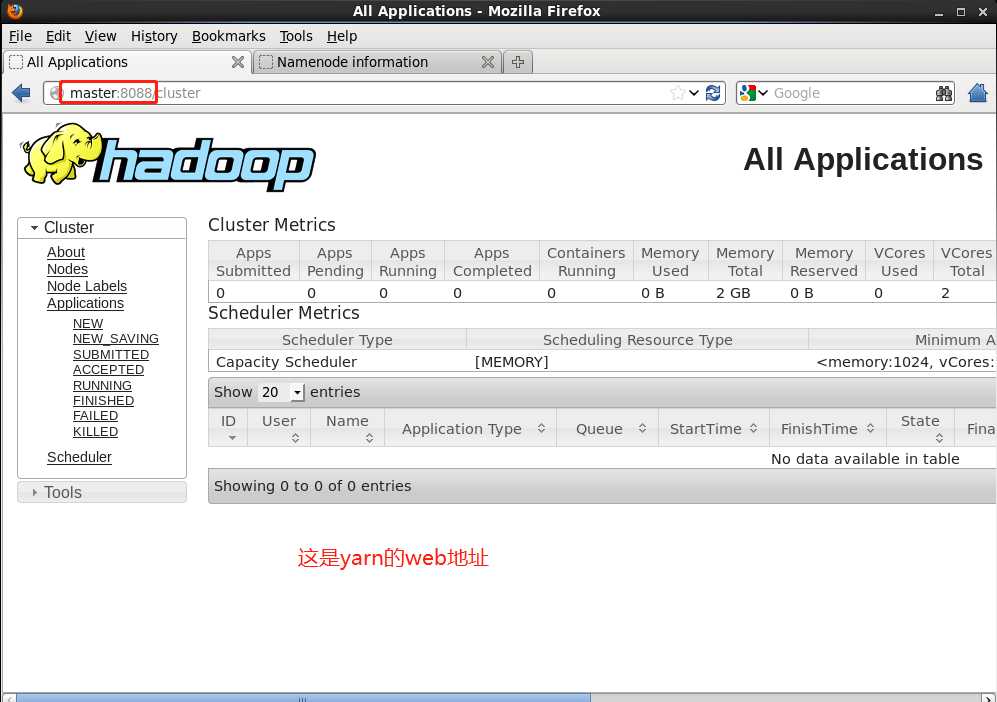
下面的是yarn的web地址 master:8088
这里还没算完事 只是看到了jps进程和web界面都是正常的 还需要运行一下hadoop自带是一个事例jar
[[email protected] software]# cd /opt/software/hadoop-2.7.4/share/hadoop/mapreduce/
[email protected] mapreduce]# hadoop jar ./hadoop-mapreduce-examples-2.7.4.jar pi 10 10
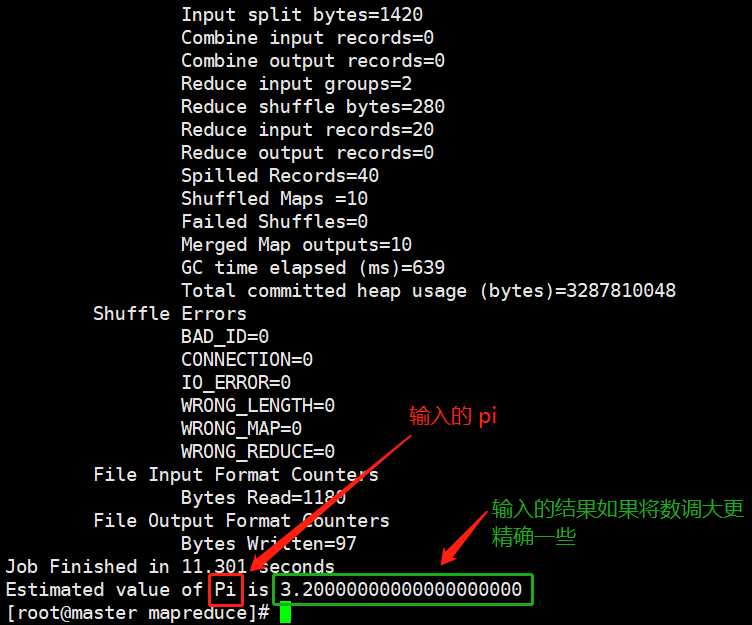
如果说正确的走到了这里那么才算彻底的完成了hadoop2.7.4的安装,恭喜您啦
以上是关于超详细 Hadoop 2.7.4 Installation Procedure的主要内容,如果未能解决你的问题,请参考以下文章