大数据框架-HDFS
Posted xiongchang95
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据框架-HDFS相关的知识,希望对你有一定的参考价值。
HDFS:分布式文件系统,运行文件通过网络在多台主机分享的文件系统,分块写入(128M),适用于一次写入多次查询,不支持并发写(只能一块一块写),小文件不合适。
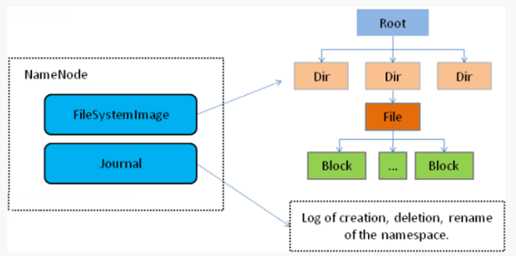
nameNode(主节点,单个): 保存HDFS的元数据信息(命名空间信息、文件系统的目录树、文件和block关系即文件对应block列表、dayaNode和block关系);接受用户读写请求。当它运行的时候,这些信息是存在内存中的,但是这些信息也可以序列化到磁盘上。负责将文件分block存储在磁盘上,多备份存储(由dataNode进行互相之间的水平复制)。
读:在内存中始终保存元数据metedata,用于处理读请求
写:首先向edit文件写日志,写入成功后才会修改内存metedata,但fsimage没改变
Checkpoint的过程:
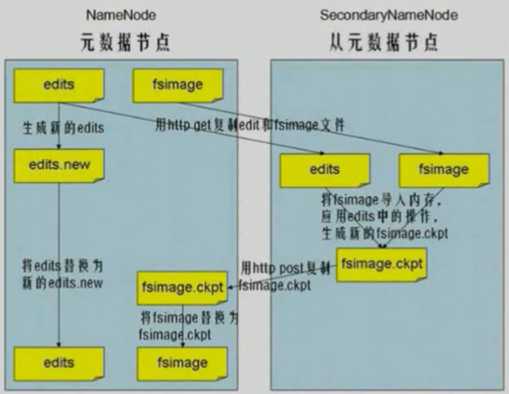
dataNode(从节点,多个) : Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。块默认大小128M,若文件小于128,则不会全占满该块。
Ps:Hadoop2.0,使用zookeeper来提供nameservice(active、standby),active节点通过journalNode将edits文件时刻写入到介质中,standby节点通过failoverController 进程将数据实时同步所在机器,时刻监控namenode状态,并和zk保持心跳。
以上是关于大数据框架-HDFS的主要内容,如果未能解决你的问题,请参考以下文章