建数据库表时给一个字段加可为空和默认值为0的约束该怎么加
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了建数据库表时给一个字段加可为空和默认值为0的约束该怎么加相关的知识,希望对你有一定的参考价值。
如题
1、首先打开数据库右键要设置表字段唯一约束的表,显示列表,如图。
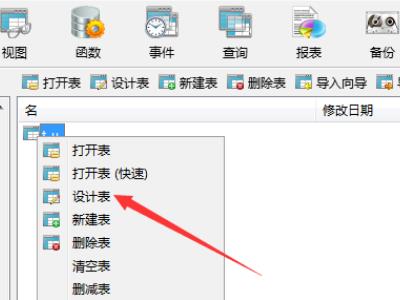
2、然后点击设计表,弹出表窗口,如图,点击索引。

3、进入索引界面,设置名称,选择栏位,也就是选择表的字段,如图。
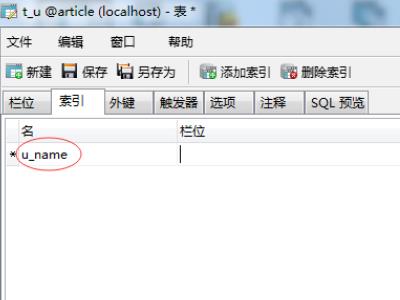
4、然后点击索引列表下拉按钮,选择唯一类型,如图所示。

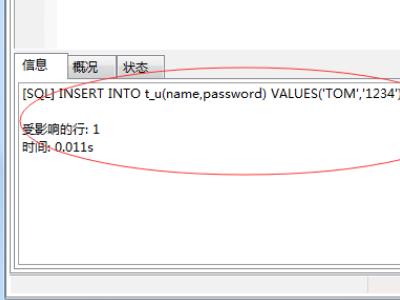
5、最后保存设置,写个插入语句执行,第一次成功,第二次表唯一约束异常说明表字段唯一约束设置成功。
--完整的示例
--sqlserver建表表时设置字段的默认值
create table 表(id int,name
varchar(10) default '张三',age int)
--添加字段时设置字段的默认值
alter table 表 add
sex char(2) default '男'
--为表中现有的字段设置默认值
alter table 表 add constraint
DF_age_表 default(20) for age
go
--插入一条记录验证
insert 表(id)
values(1)
select * from 表
go
约束主要有一下几种:
NOT NULL : 用于控制字段的内容一定不能为空(NULL)。
UNIQUE : 控件字段内容不能重复,一个表允许有多个 Unique 约束。
PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
FOREIGN KEY: FOREIGN KEY 约束用于预防破坏表之间连接的动作,FOREIGN KEY 约束 2. 也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
CHECK: 用于控制字段的值范围。
DEFAULT: 用于设置新记录的默认值。
not null : 用于控制字段的内容一定不能为空(NULL)。
用法 :Create table MyTable
(
id varchar(32) not null,
name varchar (32)
)
Primary Key :也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
在Sql Server、Orcale、MS Access 支持的添加Primary Key语法:
Create table myTB1
(
id nvarchar(32) not null primary key,
name nvarchar(32)
)
create table k ( name varchar2(20) default '张三' );
这样 默认值就为0了 也可以为空了本回答被提问者采纳 参考技术C create table k ( name varchar2(20) default '0'); 参考技术D null default 0
mysql基础2
一、列属性
所谓的列属性,就是在定义一个列(字段)的时候对该列设置的额外的信息或约束!
null和not null
默认情况下,字段都允许为空(缺省值为null),如果加上not null,意思就是这个字段不能为空,所以,not null也叫作非空约束!
当我们没有给一个not null属性的字段插入值的时候,系统会首先判断该字段有没有一个默认值,如果没有,就报错!
default
自定义默认值属性,也叫作自定义默认值约束,通常就是配合not null一起使用!
也就是说,在给一个字段加上not null属性的时候,也往往给它设置一个default属性,这样一来,如果给这个字段插入值的时候,就以插入的值为标准,如果没有给该字段插入值,就以默认值为标准!

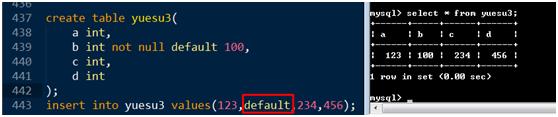
在插入数据的时候,也可以直接插入default关键字,注意这里的关键字不能用引号括起来!
primary key
简称PK,也叫作主键属性或者主键约束!主要的键,主要的字段!
主键的概念:
可以唯一标识某条记录的字段或字段的组合(组合主键)!
设置主键有两种方式:
第一种:在定义一个字段的时候直接在后面进行设置primary key

第二种:定义完字段后再定义主键

效果是一样的,但是如果定义组合主键的话,只能用第二种方式:

注意:
组合主键的含义是两个或多个字段组合在一起形成一个主键!而不是所有的字段都是主键,因为主键只能有一个!
unique key
也叫作唯一键属性或唯一键约束!增加该属性后,该字段的值就不能重复!
定义的方式和主键是类似的。
也就是说,唯一键可以有很多个!
另外,唯一键和主键的一个区别是:唯一键允许为空,但是主键不能为空!
unique key 可以简写成unique
auto_increment
自增长属性,或者自增长约束!
作用是每次插入记录的时候,自动的为某个字段的值加1(基于上一个记录)
注意:
使用这个属性有两个条件:
1, 该字段类型必须为整型
2, 该字段上必须存在索引(后面讲,主键也叫作主键索引,唯一键也叫作唯一键索引)
每次插入主键字段的时候,就可以直接插入null!这里的插入null不是真正的将null这个值插入到主键(主键不允许为null),而是告诉系统这里开启自动加载机制!默认从1开始!
如果想从100开始自动增长,需要增加表选项:auto_increment 自动增长初始值

如果想重置自动增长,可以使用truncate 表名语法!
comment
是专门为列做注释的(描述的),与其他的注释符不同之处在于,这里的注释内容属于列定义的一部分:
二、外键
foreign key 也叫作外键属性或外键约束
外键约束主要体现在以下的两个方面:
1, 增加子表记录的时候,是否有与之对应的父表记录!
2, 当删除或更改父表记录的时候,从表应该如何处理相关的记录!
外键在子表上定义!
语法格式如下:
foreign key(子表字段) references 父表名(父表主键),应该先创建父表,再创建子表,当插入子表记录的时候,需要在父表中有与之对应的记录!
设置级联操作
所谓的级联操作,就是在操作父表的时候,会以什么样的形式影响到子表,也叫作关联操作或者关联动作!
主表操作主要体现在以下两个方面:
主表更新
语法形式为:on update[级联操作]
主表删除
语法形式为:on delete[级联操作]
级联操作常见的有三种形式:
cascade:同步操作,或者串联操作!也就是当主表记录删除或更新的时候,从表也进行相应的删除或更新!
set null:设置为null,也就是当主表记录删除或更新的时候,从表中的外键字段设置为空
restrict:拒绝主表的更新或删除
删除外键的语法:
alter table 表名drop foreign key 外键名;
注意:这里的外键名并不是字段名,一般如果在创建外键的时候没有给该外键起一个名字,系统会自动分配一个外键名字!可以通过show create table语句来查看外键名
增加外键的语法:
alter table 表名 add foreign key 外键定义

注意:
1), 外键约束只有InnoDB存储引擎才支持!
2), 在实际项目中,往往会用到外键的设计思想,但往往不会真正的从语法上进行外键约束,因为外键约束的级联操作可能会带来一些现实的逻辑问题!另外,使用外键会较低mysql的效率!
三、存储引擎
用户在创建表的时候,要根据实际需要合理的选择存储引擎,在windows下,默认的存储引擎为InnoDB,当然,可以在数据库的配置文件my.ini中进行修改:
修改后需要重启MySQL服务器!
一张数据表,是由三部分构成的:结构 数据 索引
Myisam存储引擎是把这三个部分分开存储!而InnoDB存储引擎的表在数据库目录下只存储表结构!而表的数据和索引其实都在同一个数据空间内
选择存储引擎的依据:
1, 功能:外键、事务支持,高并发量等
2, 性能
总体来说,就是在满足功能的基础上追求性能!在我们的项目中,如果一张表90%都是查询操作,就用Myisam,一般用默认的InnoDB
四、其他数据操作
蠕虫复制
就是在已有的数据的基础之上,将原来的数据进行复制,插入到相对应的表中!
语法规则:
insert into 表名 select *|字段列表from 表名
注意:当一个表中的数据复制到另一个表中的时候,需要注意数据的来源要与被插入的表的字段数量和类型要保持一致!
总结蠕虫复制的优点:
1, 可以以最快的速度复制另外一张表的数据
2, 在短期内产生大量的数据,以测试服务器的压力
主键重复
如果在进行数据更新的时候,某条记录的主键已经存在,但是又需要将最新的数据更新到该记录中
策略一:
可以使用以下的语法:
insert into 表名[字段列表] values(值列表) on duplicate key update 字段1=值1,字段2=值2……
也就是说,当主键不冲突的时候,相当于一条插入语句,当主键有冲突的时候,相当于一条更新语句!
策略二:
如果主键重复,直接删除原纪录再插入
replace into 表名[字段列表] values(值列表);
在插入之前进行一次判断,判断有没有主键重复,如果没有,跟普通的插入语句没有区别,如果有主键冲突,先删除以前的记录,再插入新记录!
修改数据
标准语法:
update 表名 set 字段1=值1,字段2=值2……where条件;
还可以加上orderby子句和limit子句:
update 表名 set 字段1=值1,字段2=值2……[where条件][order by 字段名 asc|desc][limit 数据量]
删除数据
标准语法:
delete from 表名 [where条件] [order by 字段名 asc|desc][limit 数据量]
还有一个类似删除功能的语法:
truncate table 表名; 或 truncate 表名;
注意:该语句不属于DML,属于DDL
相当于做了两件事情:
1, 先把原表drop掉!
2, 再按以前的原表的结构重新创建一次!
五、数据查询
select [select选项] *|字段列表 [as 字段别名] from 数据源 [where子句][group by子句][having子句][order by子句][limit子句];
以上的语法一般只是单表查询,另外还有多表查询,多表查询又有联合查询、子查询、连接查询(左连接,右连接,内连接,外连接,自然连接)
注意:
1), from后面的子句往往称之为:五子句,也叫五子查询!
2), 五子查询都可以没有,但是,如果要有,就必须按顺序写!
1、select选项和别名
select选项 含义:就是系统在查询到相关数据之后,如何显示!
这里的select选项有两个值:
all:也是缺省值(默认值),保留所有的查询结果!
distinct:去重,去掉重复的查询结果!
别名:所谓的别名,就是给字段或其他表达式等标识符另起一个名字,基本语法如下:
字段|表达式|表|子查询 [as] 别名
这里的as可以省略,但是为了增加可读性,一般还是写上!
2、虚拟表
查询语句的比较完整的语法:
select [select选项] *|字段列表 [as 字段别名] from 数据源 [where子句][group by子句][having子句][order by子句][limit子句];
但是,一条真实的sql语句,有可能连字段没有!
典型的,select语句可以当计算器使用:

但是,理论上认为一条sql语句必须从一个数据源中去获取数据!
所以,为了保证sql语句语法的结构完整性,在Mysql中执行select语句的时候在适当的时候会自动创建一个虚拟表!这个虚拟表就是当数据源来使用!
虚拟表的名称:dual
3、where子句
语法:where 表达式
功能:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果
流程:逐一取出每一条记录,先通过当前记录来计算where后面表达式的值,如果计算的结果为真(非0),就返回来记录,如果计算的结构为假(0),则不返回记录!相当于对所有的记录做了一次遍历!
where子句后面往往配合MySQL运算符一起使用(做条件判断)
MySQL运算符 MySQL支持以下的运算符:
关系运算符
< >
<= >=
= !=(<>)
注意:这里的等于是一个等号
between and
做数值范围限定,相当于数学上的闭区间!
比如:
between A and B相当于 [A,B] 另外,between and 的前面还可以加上not,代表相反!
in和not in
语法形式:in|not in(集合)
表示某个值出现或没出现在一个集合之中!
逻辑运算符
&& and
|| or
! not
where子句的其他形式
空值查询
select *|字段列表 from 表名 where 字段名 is [not] null
模糊查询
也就是带有like关键字的查询,常见的语法形式是:
select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个:
_ :代表任意的单个字符
% :代表任意的字符
4、group by子句 也叫作分组统计查询语句!
语法:group by 字段1[,字段2]……
分组统计查询的主要作用不是分组,而是统计!或者说分组的目的就是针对每一个分组进行相关的统计!
此时,就需要使用系统中的一些统计函数!
统计函数(聚合函数)
sum():求和,就是将某个分组内的某个字段的值全部相加
max():求某个组内某个字段的最大值
min():求某个组内某个字段的最小值
avg():求某个组内某个字段的平均值
count():统计某个组内非null记录的个数(行数),通常就是用count(*)来表示!
注意:
统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!
多字段分组
group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段2进行分组!
多字段分组的结果就是分组变多了!
回溯(su)统计
回溯统计就是向上统计!在进行分组统计的时候,往往需要做上级统计!
比如,先统计各个班的总人数,然后各个班的总人数再相加,就可以得到一个年级的总人数!
在MySQL中,其实就是在语句的后面加上with rollup即可!
5、having子句
having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!
having子句和where子句有什么区别?
二者的比较:
1), 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
2), 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3), where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!
6、order by子句
根据某个字段进行排序,有升序和降序!
语法形式为:
order by 字段1[asc|desc]
默认的是asc,也就是升序!如果要降序排序,需要加上desc!
多字段排序
order by 字段1[asc|desc],字段2[asc|desc]……
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年级进行降序排序!
7、limit子句
limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法
limit offset,length
其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
例:现在想显示记录的第4条到第8条 limit 3,5;
分页原理
假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10
第2页:limit 10,10
第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度
limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage
以上是关于建数据库表时给一个字段加可为空和默认值为0的约束该怎么加的主要内容,如果未能解决你的问题,请参考以下文章