大数据调整集群当中的磁盘占用(HDFS)和存的数据的副本数的调整
Posted gxg123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据调整集群当中的磁盘占用(HDFS)和存的数据的副本数的调整相关的知识,希望对你有一定的参考价值。
最近刚搭建的Hadoop集群(CM),发现在通过sqoop导入数据使整个集群当中的磁盘都快占满了。这个时候考虑到需要对集群当中数据的副本数进行修改(由原来的3个副本修改为现在的1个副本)
dfs.replication 将这个参数的值由3变为1
然后我们在对之前到如到HDFS上面的文件进行重新设置副本数。命令如下:
hadoop fs -setrep -R 1 / 将根目录下的文件的副本数设置为1个。
然后我们使用CM对集群当中的资源进行平衡操作。截图如下:
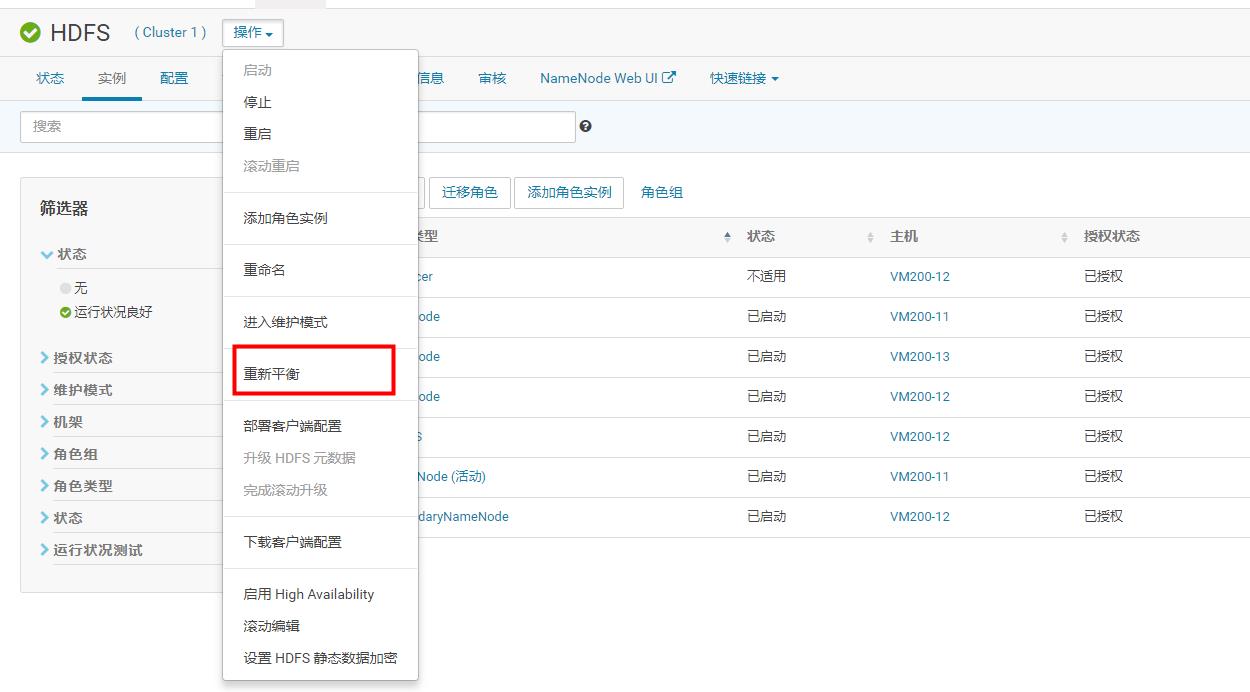
平衡之后,我们就可以看到整个集群当中磁盘的占用情况进行了改善:
具体的截图如下:


至此集群当中的磁盘占用没有那么多得到了有效的改善。
以上是关于大数据调整集群当中的磁盘占用(HDFS)和存的数据的副本数的调整的主要内容,如果未能解决你的问题,请参考以下文章