Hadoop课程
Posted 少侠gqk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop课程相关的知识,希望对你有一定的参考价值。
作者:gqk
1,Hadoop的前世今生:
2,hadoop是什么:
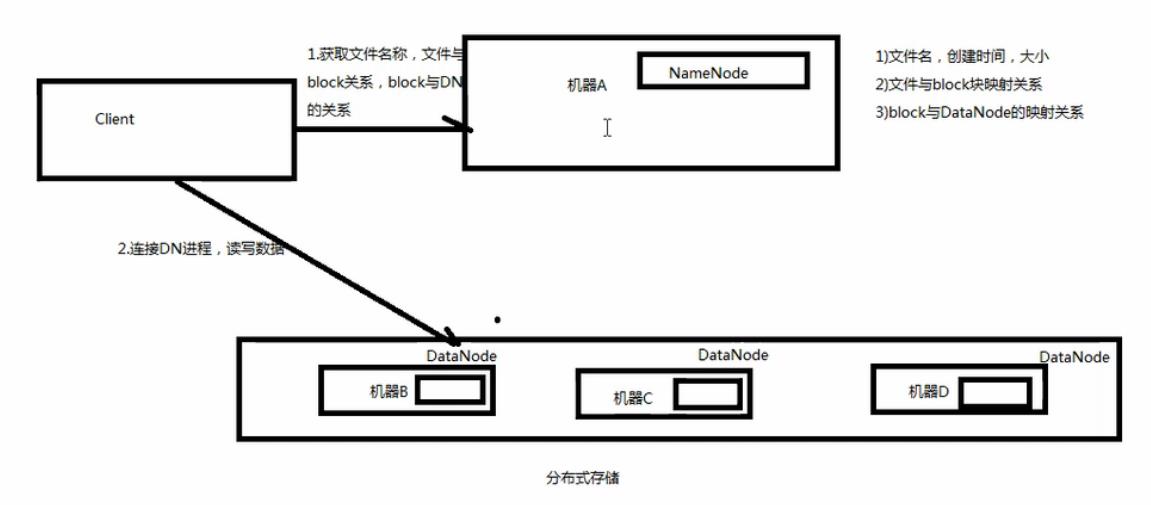
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 [2]
3,什么是分布式文件系统:
指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连
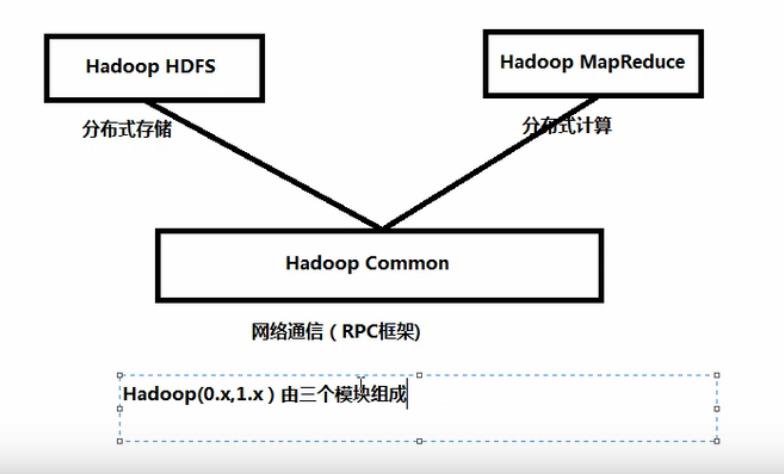
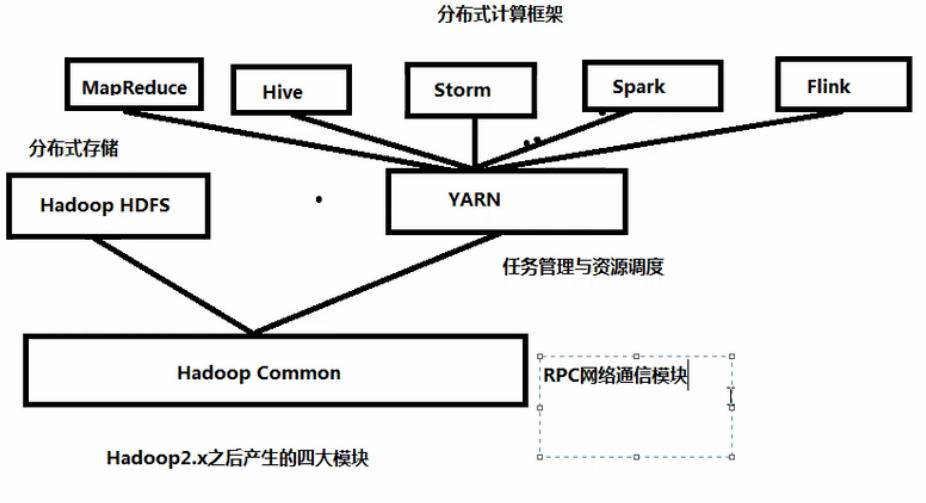
4,hadoop的四大组件:
common、HDFS、MapReduce、YARN
common:Hadoop常用的工具类,
HDFS:Hadoop实现了一个分布式的文件系统,HDFS为海量的数据提供了存储
MapReduce:基于YARN的大型数据集并行处理系统。是一种计算模型,用以进行大数据量的计算。
yarn:分布式集群资源管理框架,管理者集群的资源
5,HDFS:分布式文件系统:
a,文件系统:文件管理+block块管理(读写文件存储到磁盘中的块)
单机文件系统:windows(文件系统格式):FAT16,FAT32,NTFS
LINUX(文件系统格式):ext2/3/4,vfs
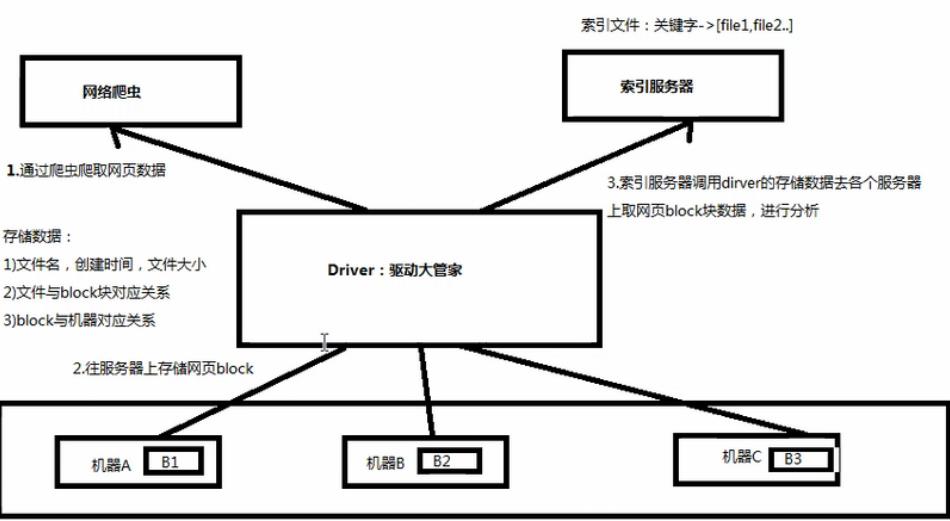
b,分布式文件系统:多个服务器存储文件(画图说明搜索引擎处理流程)
Hadoop环境搭建:
1,三个环境:单机版,伪分布式,分布式
2,三个分支:
apach,cdh(用)http://archive.cloudera.com/cdh5/cdh/5/ .tar.gz可以下载 hdp版本
3,部署环境
服务器:VMWare虚拟机,Centos操作系统
客戶端:SecureCRT (需要秘钥)/ Xshell 通过SecureCRT链接centos中的linux后先关闭防火墙 service iptable status
4,配置网络:
设置静态ip:
图形化界面:
VMnet8查看网段 
设置网段:
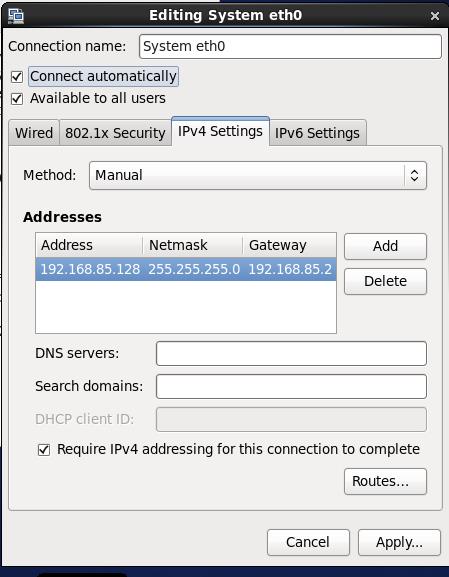
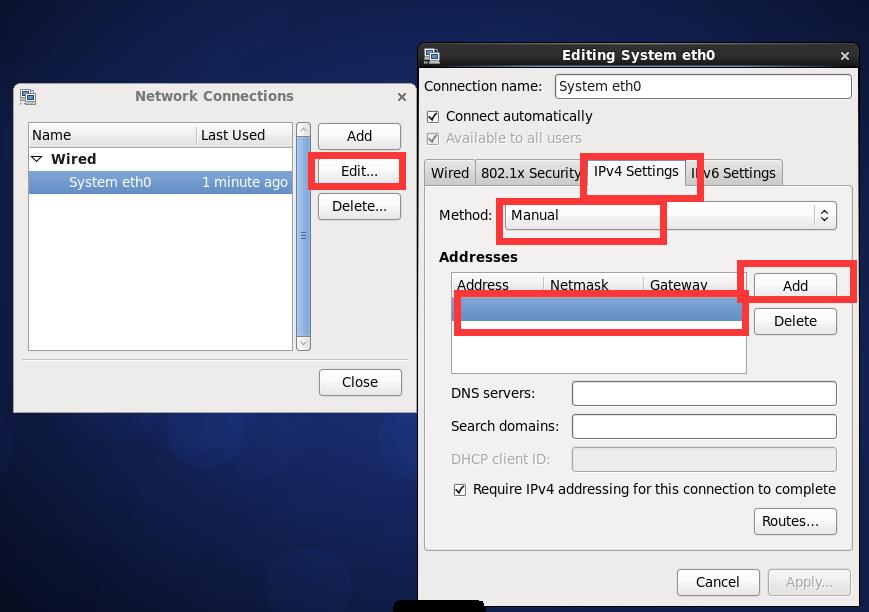
命令行配置:
cd /etc/sysconfig/network-scripts/
vim
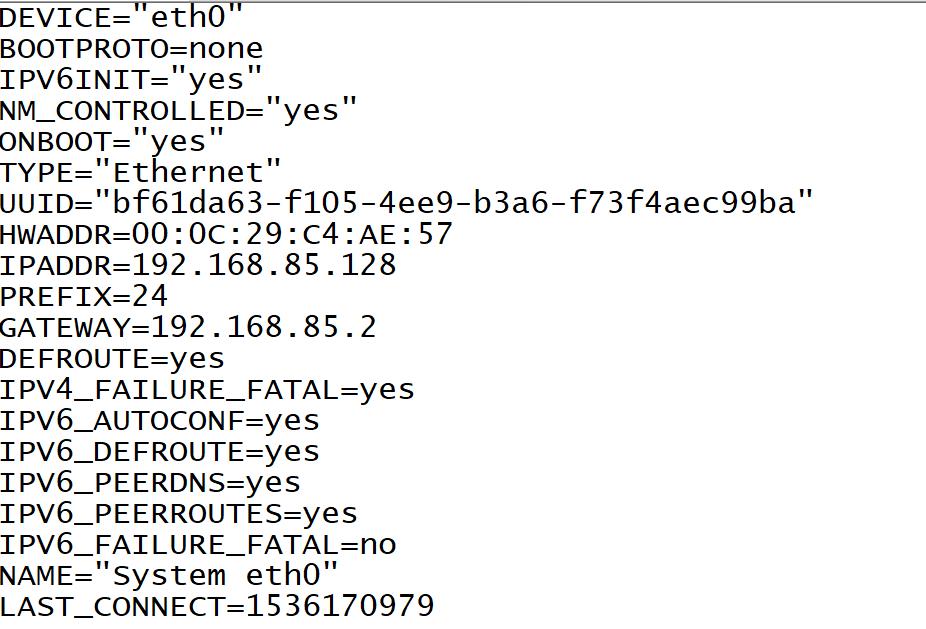 --:wq!保存
--:wq!保存
--重启 service network restart
设置机主名称:
暂时性的:服务器重启动失效:hostname 主机名称
持久性的:
编辑:vim /etc/sysconfig/network
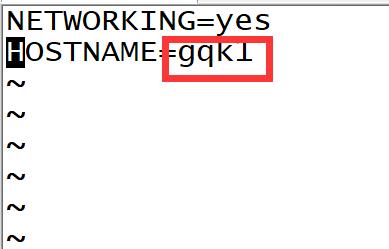
保存::wq!
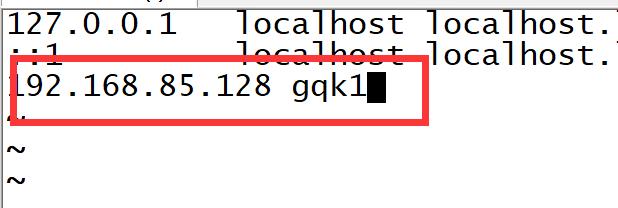
主机名和ip映射关系
--vim /etc/hosts
hadoop单机环境的搭建:(仅仅用于单机运行分布式作业计算的运行)
1,下载hadoop的安装包
2,创建目录存放hadoop的安装包
--cd opt
--mkdir software
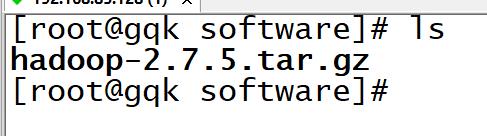
3,将hadoop安装包存放在software中
进入sftp=========alt+p
进入cd/opt/software中 拖动hadoop安装包(英文目录)
文件传递成功:
4,安装hadoop包,(在opt目录下创建module)--mkdir module
tar zxf hadoop-2.7.5.tar.gz -C /opt/module/
5,创建目录:[root@gqk hadoop-2.7.5]# mkdir input
6,将hadoop的全部配置信息存放在input里面
[root@gqk hadoop-2.7.5]# cp etc/hadoop/*.xml input
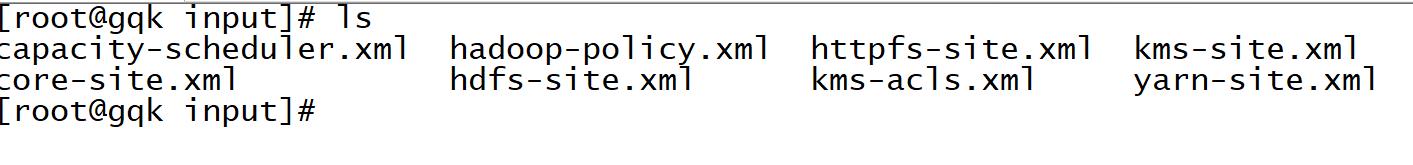
7,需要配置下jdk的环境变量:vim /etc/profile
· 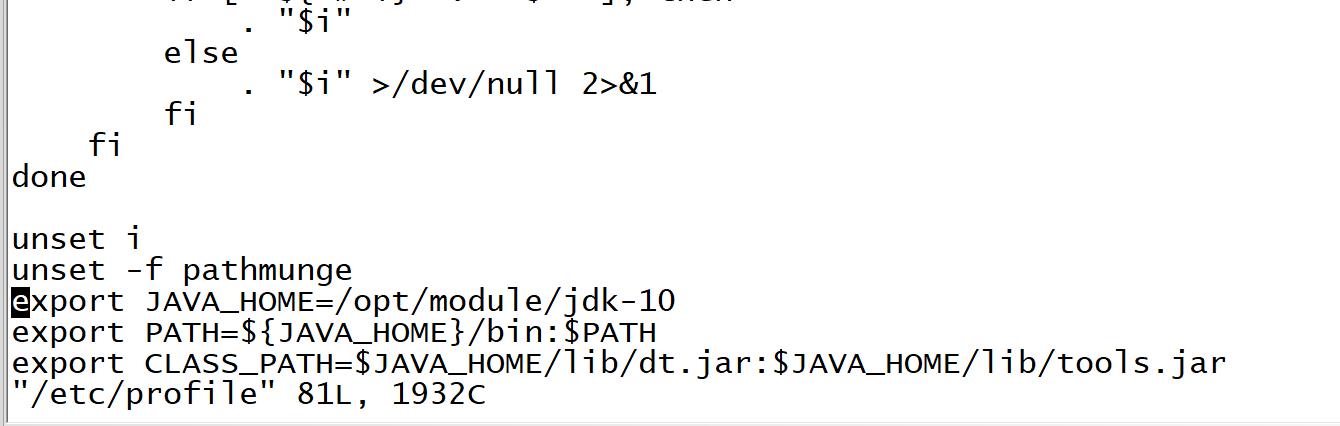
source /etc/profile
8,在hadoop的etc/hadoop目录下的hadoop-env.sh文件配置下JAVA_HOME (/opt/module/hadoop-2.7.5/etc/hadoop下面的文件)
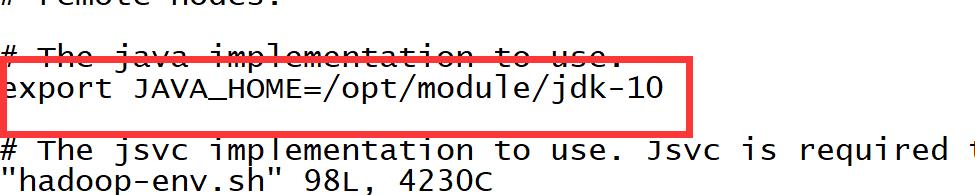
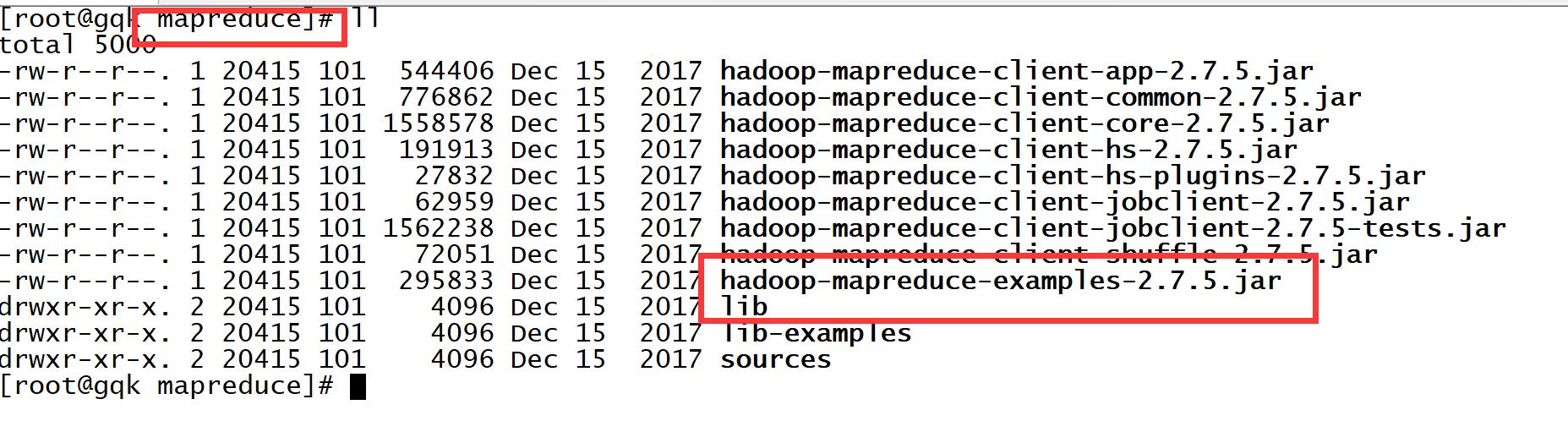
7,运行一下jar目录在/opt/module/hadoop-2.7.5/share/hadoop/mapreduce
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar grep input output \'dfs[a-z.]+\' (查找input下面包含 dfs的文件名称)
运行结果:
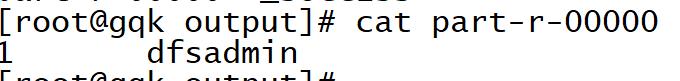
统计单词数量:(注意文件不能存在output)
[root@gqk output1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount input output1
以上是关于Hadoop课程的主要内容,如果未能解决你的问题,请参考以下文章