hadoop
Posted 夕阳如火
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop相关的知识,希望对你有一定的参考价值。
1. HADOOP背景介绍
1.1 什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
Hadoop hive hbase flume kafka sqoop spark flink …….
1.2 HADOOP产生背景
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.3 HADOOP在大数据、云计算中的位置和关系
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4 国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
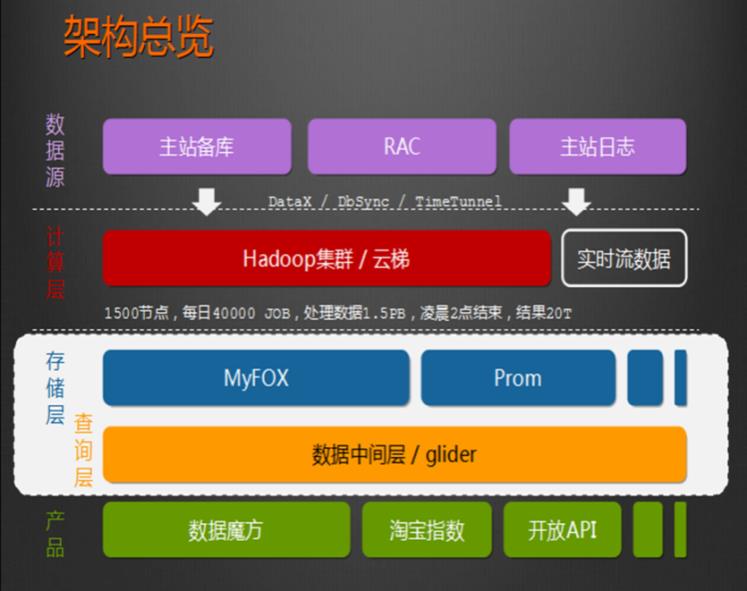
2、HADOOP用于用户画像

3、HADOOP用于网站点击流日志数据挖掘
1.5 国内HADOOP的就业情况分析
1、 HADOOP就业整体情况
- 大数据产业已纳入国家十三五规划
- 各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
- 互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
- 相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
- 随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
- HADOOP分布式集群的平台搭建
- HADOOP分布式文件系统HDFS的原理理解及使用
- HADOOP分布式运算框架MAPREDUCE的原理理解及编程
- Hive数据仓库工具的熟练应用
- Flume、sqoop、oozie等辅助工具的熟练使用
- Shell/python等脚本语言的开发能力
3、 HADOOP相关职位的薪资水平
大数据技术或具体到HADOOP的就业需求目前主要集中在北上广深一线城市,薪资待遇普遍高于传统JAVAEE开发人员
1.6 HADOOP生态圈以及各组成部分的简介
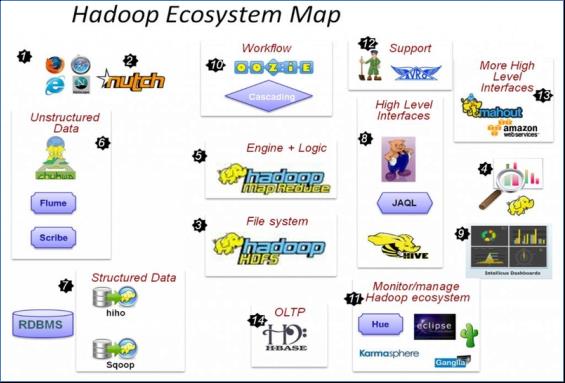
各组件简介
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
2 分布式系统概述
注:由于大数据技术领域的各类技术框架基本上都是分布式系统,因此,理解hadoop、storm、spark等技术框架,都需要具备基本的分布式系统概念
2.1 分布式软件系统(Distributed Software Systems)
² 该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
² 比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
2.2 分布式软件系统举例:solrcloud
- 一个solrcloud集群通常有多台solr服务器
- 每一个solr服务器节点负责存储整个索引库的若干个shard(数据分片)
- 每一个shard又有多台服务器存放若干个副本互为主备用
- 索引的建立和查询会在整个集群的各个节点上并发执行
- solrcloud集群作为整体对外服务,而其内部细节可对客户端透明
总结:利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统。
2.3 分布式应用系统模拟开发
需求:可以实现由主节点将运算任务发往从节点,并将各从节点上的任务启动;
程序清单:
AppMaster
AppSlave/APPSlaveThread
Task
程序运行逻辑流程:
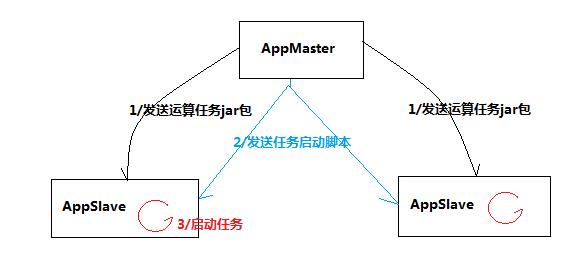
3.集群搭建
3.1 HADOOP集群搭建
3.1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
最好将SecondaryNameNode配置在另一台机器上 SecondaryNameNode严格意义上并不算是NameNode的备份 只是保存了大量的NameNode上的元数据
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
hdp-node-01 NameNode SecondaryNameNode hdp-node-02 ResourceManager hdp-node-03 DataNode NodeManager hdp-node-04 DataNode NodeManager hdp-node-05 DataNode NodeManager
部署图如下:
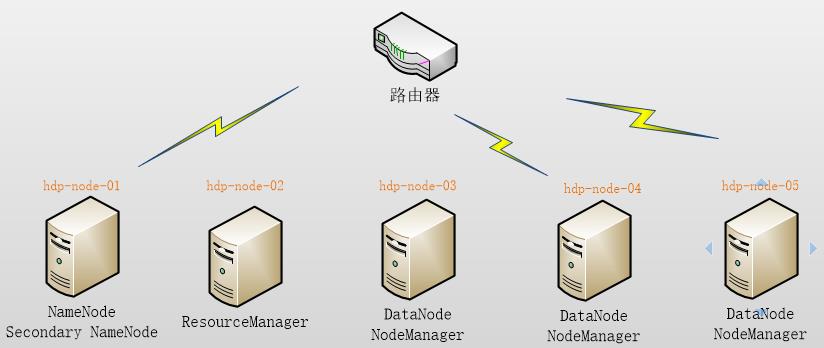
3.1.2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
1、 Vmware 14.0
2、Centos 6.7 64bit
创建虚拟机:
1.点击文件,新建一个虚拟机
2.安装时选则自定义,下一步,兼容性直接点下一步
3.点稍后安装操作系统,下一步
4.客户机操作系统选择Linux,版本Centos 64位 ,下一步
5.修改虚拟机名称 指定虚拟机存放位置 下一步
6.处理器数量1 核心数量2 下一步
7.设置虚拟机大小2GB 下一步
8.网络连接类型选NAT 下一步
9.SCSI控制器选择推荐的 下一步
10.虚拟磁盘类型选择推荐的 下一步
11.创建新虚拟磁盘 下一步
12.磁盘大小20G(一般为20G-50G) 拆分为多个文件 下一步
13.下一步
14.完成
15.之后在VMware窗口 选择刚刚装好的虚拟机 点击 cd/dvd 然后选择 使用ISO映象文件 浏览选择
16.点击 VMware上方的 编辑 选择虚拟网络编辑器
17.进去后(win10需要点击右下方的 更改设置) 选择VMnet8(NAT模式) 设置子网IP:192.168.59.0 子网掩码:255.255.255.0
18.启动虚拟机 点击skip 之后选择下一步 然后选择中文 下一步 选择简体中文 下一步
19.选择存储类型 Basic 下一步
20.Yes 格式化硬盘 下一步
21.设置主机名 (主机名可更改) 下一步
22.设置时间 上海 点击上海的位置 下一步
23.设置root用户密码 123456 记住密码 密码简单 选择use anyway 下一步
24.磁盘划分使用默认划分方式 next
25.write change to disk , next 等待安装 Reboot
26.重启之后 输入用户名: root 密码 :123456
之后 在3.1.4
3.1.3网络环境准备
1. 采用NAT方式联网
2. 3个服务器节点IP地址:192.168.59.130、192.168.59.131、192.168.59.132
3. 子网掩码:255.255.255.0
3.1.4服务器系统设置
添加映射(添加主机名和ip地址映射 即其他虚拟机所在位置)
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.59.130 hadoop
192.168.59.131 hadoop001
192.168.59.132 hadoop002
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop
网卡配置
vi /etc/sysconfig/network-scripts/ifcfg-eth0
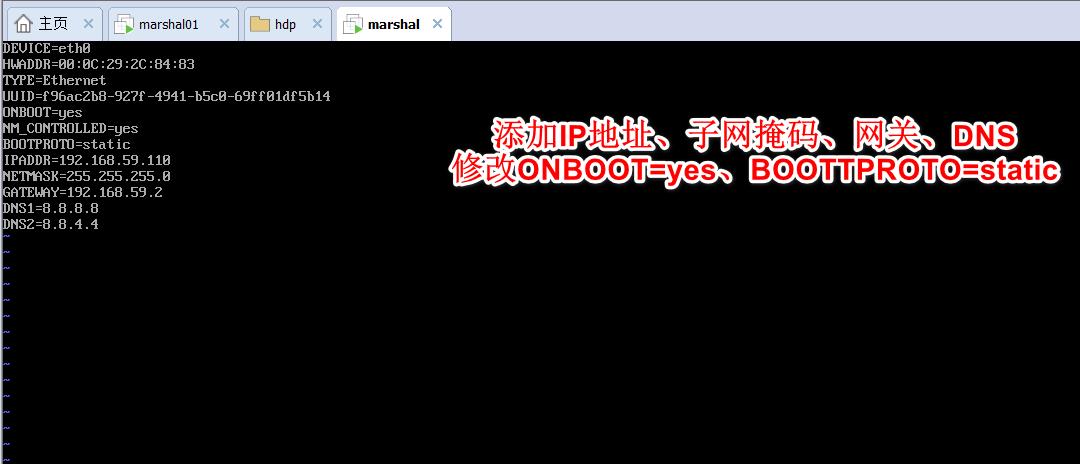
本机进入 C:\\Windows\\System32\\drivers\\etc 修改hosts 添加
192.168.59.130 hadoop
192.168.59.131 hadoop001
192.168.59.132 hadoop002
# ip地址 主机名
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
开机禁止防火墙启动
chkconfig iptables off
安装ssh
yum install -y openssh-clients
3.1.5 XShell
使用xshell连接虚拟机
主机那里输入192.168.59.130 或者 hadoop都可以(输入hadoop必须把本机hosts配置好)
此时就可以用xshell连接虚拟机
3.1.6 克隆虚拟机
制作模板之前需要删除/etc/udev/rules.d/70-persistent-net.rules目录下的网卡和mac地址的映射文件,删除之后关机
然后克隆虚拟机
vi /etc/udev/rules.d/70-persistent-net.rules
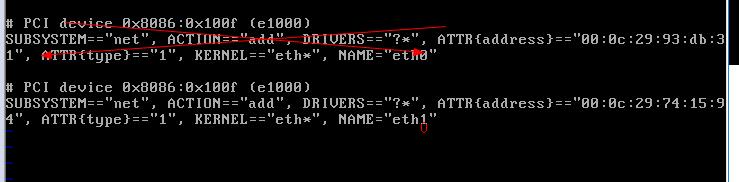
克隆虚拟机后
把IPADDRGA改成对应虚拟机的ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
之后修改虚拟机的主机名
vi /etc/sysconfig/network
3.1.7 Jdk环境安装
1.上传jdk安装包
使用rz上传安装包,如果显示-bash: rz: command not found没有rz命令,先安装rz和sz命令
安装命令为
yum install -y lrzsz
输入rz后,找到安装包位置 点击打开
2.解压安装包
java.tar.gz是java的名字 根据自己的java名字写上去
/是想要安装到的路径 自己定义
tar -zxvf java.tar.gz -C /
配置环境变量 /etc/profile
vi /etc/profile
添加 JAVA_HOME 是java的安装路径
export JAVA_HOME=/root/app/jdk1.8.0_171/ export PATH=$PATH:$JAVA_HOME/bin
添加后重新加载配置文件
source /etc/profile
3.1.8 HADOOP安装部署
一般参数列表
fs.defaultFS HDFS的名称空间地址
dfs.blocksize 块大小,默认是64M或128M,文件存储的时候,如果大于指定块大小,则切分,如果小于,则按照文件大小存储,并不会占用指定块大小
dfs.replication 备份数,默认为3
dfs.reservedsize 磁盘保留空间,默认未开启
dfs.namenode.edit.dir NameNode的edit日志存放路径,edit日志文件编号前后连接,如果中间有断链,那么说明文件缺失
dfs.namenode.name.dir NameNode的image文件(元数据)存放路径
dfs.datanode.data.dir DataNode的数据存储目录,可以选择存储在多个目录下,多个目录用逗号隔开
dfs.namenode.rpc-address NameNode的RPC服务端口号
dfs.namenode.http-address NameNode的HTTP服务端口号
dfs.datanode.address DataNode的RPC服务端口号,数据传输用
dfs.datanode.http.address DataNode的HTTP服务端口号
dfs.datanode.ipc.address DataNode的IPC端口号,与NameNode通信
fs.trash.interval 开启回收站,如果通过hdfs的shell命令删除的数据会放到回收站,回收站默认清除时间为1小时,也可以自定
上传HADOOP安装包
规划安装目录 /home/hadoop/apps/hadoop-2.8.3
解压安装包
修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
在hadoop目录/etc/hadoop下
vi hadoop-env.sh
JAVA_HOME java放在哪个位置
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk_1.8.65
vi core-site.xml
fs.defaultFS 主机名:端口号
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:8000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value> </property> </configuration>
vi hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hadoop:50090</value> </property> </configuration>
vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
vi yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vi salves
想要哪些节点的DataNode启动
hadoop
hadoop001
hadoop002
3.1.9 复制到其他虚拟机
把第一台安装好的jdk和hadoop以及配置文件发送给另外两台
hosts文件
jdk安装后的文件夹
Hadoop安装后的文件夹
/etc/profile 文件
例如
scp -r /usr/local/jdk1.8.0_102 hadoop01:/usr/local/
scp -r /etc/hosts hadoop01:/etc/hosts
时间同步
ntpdata ip date -s "时间"
最后记得设置ssh免密登录
ssh-keygen
ssh-copy-id -i /root/id_ras.pub host(ip)
3.1.9 启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
通过网页查看
hadoop:50070
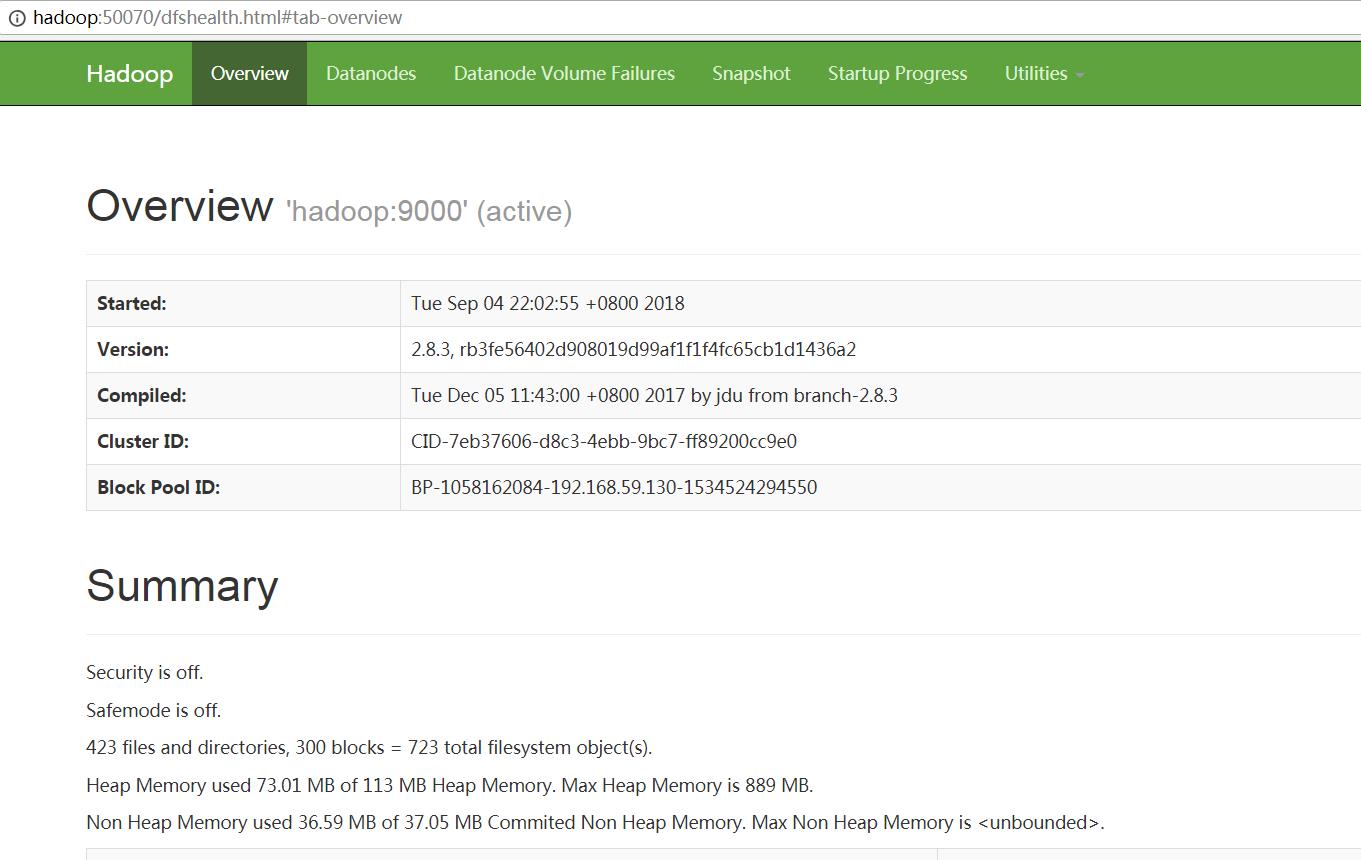
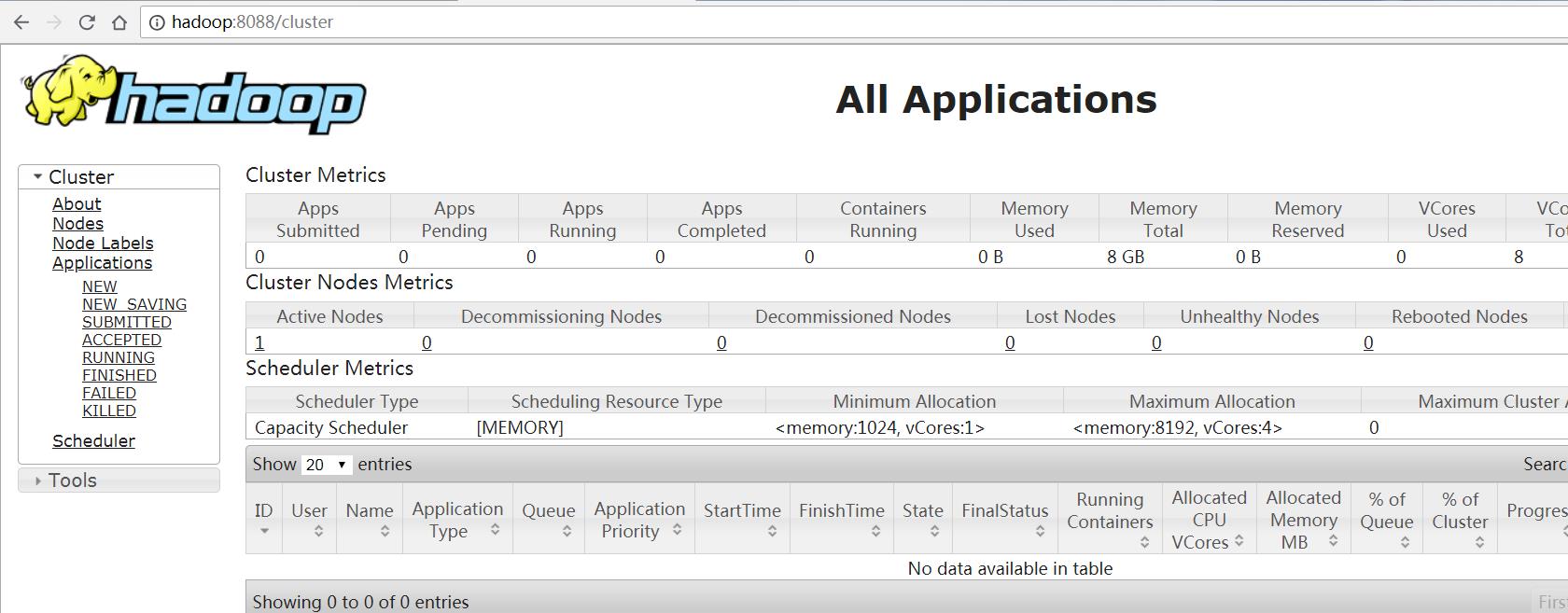
查看yarn
hadoop:8088
以上是关于hadoop的主要内容,如果未能解决你的问题,请参考以下文章