北京大学肖臻老师《区块链技术与应用》公开课笔记-BTC
Posted 一只夫夫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了北京大学肖臻老师《区块链技术与应用》公开课笔记-BTC相关的知识,希望对你有一定的参考价值。
本笔记为学习期间对主要知识和逻辑的记录,根据课程内容分为BTC和ETH两篇,本篇为BTC部分
文章目录
- 01-课程简介
- 02-BTC-密码学原理
- 03-BTC-数据结构
- 04-BTC-共识协议
- 05-BTC-实现
- 06-BTC-网络
- 07-BTC-挖矿难度
- 08-BTC-挖矿
- 09-BTC-脚本
- 10-BTC-分叉
- 11-BTC-问答
- 12-BTC-匿名性
- 13-BTC-思考
01-课程简介
- 参考资料(以代码为准)
- BitCoin and Cryptocurrency Technologies A Comprehensive Introduction(2016年出版,已经比较过时)
- 以太坊白皮书、黄皮书、源代码
- Solidity文档
课程大纲:比特币
- 比特币
- 密码学基础
- 比特币的数据结构
- 共识协议和系统实现
- 挖矿算法和难度调整
- 比特币脚本
- 软分叉和硬分叉匿名和隐私保护
课程大纲:以太坊
- 以太坊
- 概述:基于账户的分布式账本
- 数据结构:状态树、交易树、收据树
- GHOST协议
- 挖矿:memory-hard mining puzzle
- 挖矿难度调整
- 权益证明
- Casper the Friendly Finality Gadget(FFG)
- 智能合约
- 总结与展望
02-BTC-密码学原理
比特币主要用到了密码学中的两个功能:1.哈希2.签名
- 密码学中用到的哈希函数被称为cryptographic hash function: 它有几个重要的性质:
- collision(这里指哈希碰撞) resistance:找不到另外一个输入使得其哈希值与原输入的哈希值一致
- hiding 哈希函数的计算过程是单向的,不可逆的
- puzzle friendly 指哈希值的取值范围事先是不可预测的,即挖矿找到随机数使其哈希小于target只能不断尝试
- 在比特币系统中开账户:
-
在本地创立一个公私钥匙对(public key ,private key),这就是一个账户。公私钥匙对是来自于非对称的加密技术(asymmetric encryption algorithm)。
-
加密用你的公钥,你收到之后用你自己的私钥解密
-
签名用私钥,解密用公钥
-
所以需要很好的随机源来产生公私钥对
03-BTC-数据结构
-
哈希指针
普通指针存储的是某个结构体在内存中的地址。而比特币中哈希指针,只保存该结构体的哈希值H()。根据哈希值找位置并判断是否被篡改
-
比特币中最基本的结构就是区块链
-
区块链和普通的链表相比有什么区别:
-
用哈希指针代替了普通指针(B block chain is a linked list using hash pointers)
-
普通链表可以改变任意一个元素,对链表中其他元素是没有影响的。而区块链是牵一发而动全身,因此只需要保存最后一个哈希值,就可以判断区块链有没有改变,在哪里改变了。
-
-
区块分为Block header以及 Block body
- block header就含有Merkle tree 里的root hash
-
-
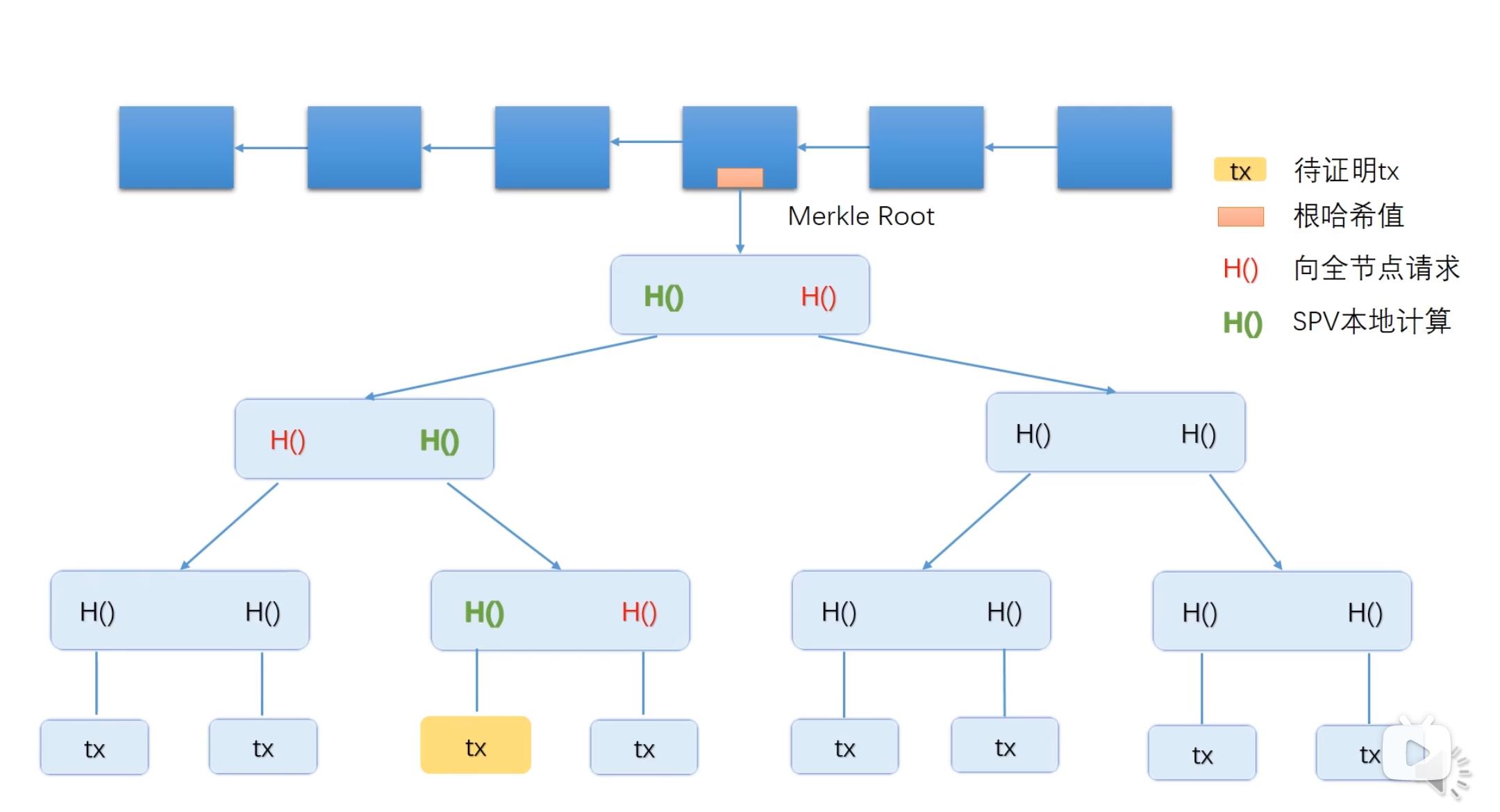
Merkle Tree(比特币中区块的数据结构)
-
其中最下面一层是数据块(data blocks),上面三层内部节点都是哈希指针(hash pointers),第一层是根节点,根节点的区块也可以取个哈希,叫根哈希(root hash)。每个数据块是一个交易
-
作用:提供merkle proof:证明某个数据块中的交易包含在了区块中
-
证明黄色tx在区块中:
根据全节点返回的红色哈希值,算出根哈希值是否就块头中的跟哈希值
轻节点只有块头
-
如何证明merkle tree里面没有包含某个交易?
如果对叶节点的排列顺序做一些要求,比如按照交易的哈希值排序。每一个叶节点都是一次交易,对交易的内容取一次哈希,按照哈希值从小到大排列。要查的交易先算出一个哈希值,看看如果它在里面该是哪个位置。比如说在第三个第四个之间,这时提供的proof是第三个第四个叶节点都要往上到根节点。如果其中哈希值都是正确的,最后根节点算出的哈希值也是没有被改过的,说明第三、四个节点在原来的merkle tree里面,确实是相邻的点。要找的交易如果存在的话,应该在这两个节点中间。但是它没有出现,所以就不存在。其复杂度也是log形式,代价是要排序。排好序的叫作sorted merkle tree。比特币中没有用到这种排好序的merkle tree,因为比特币中不需要做不存在证明。
-
-
04-BTC-共识协议
-
数字货币和纸质货币区别是可以复制,叫作双花攻击 即double spending attack。
去中心化货币要解决两个问题:-
问题
-
数字货币的发行
-
怎么验证交易的有效性,防止double spending attack。
-
-
解决方法:
-
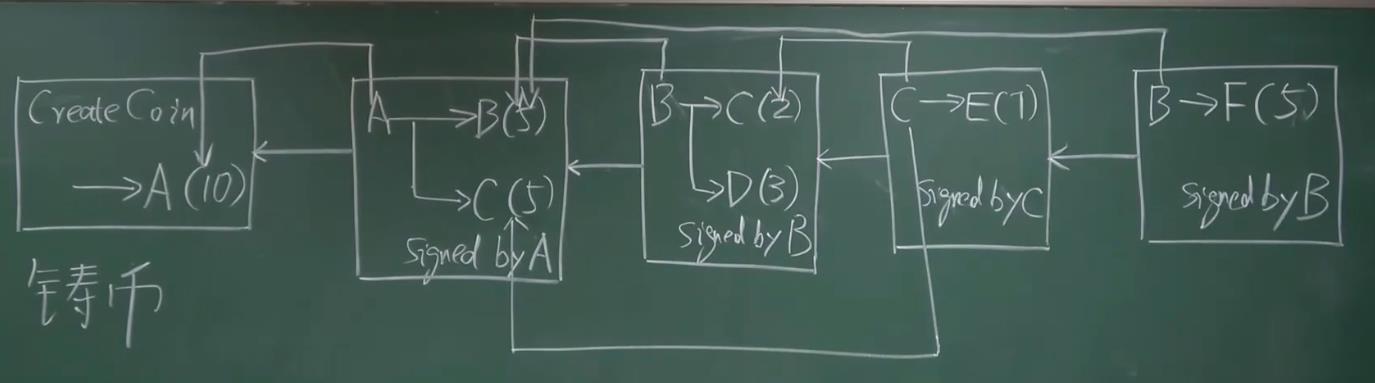
比特币的发行是由挖矿决定的
每一个比特币的最终来源都是每一个新挖出来区块里面的铸币交易
-
依靠区块链的数据结构
指明币的来源以及来源余额,来源的最终源头都是每个新区块里的铸币交易
-
-
-
转账交易
-
信息
-
付款人通过其他渠道获得收款人公钥
-
收款人、其他人需要知道付款人公钥(交易中付款人给出的)
- 验证付款人身份
- 币的来源中,铸币交易的输出就有付款人公钥的哈希,能够验证合法
-
如何防范别人用自己公钥伪造签名?
-
这些是靠输入输出脚本来执行的,输入输出脚本在一起能够正确执行,就说明交易合法
本质上就是看之前收款的公钥哈希跟此次交易的公钥的哈希对不对得上
-
-
-
-
分布式共识:账本的内容要取得分布式的共识
-
还有一个著名结论:CAP Theorem
-
Consistency【系统状态的一致性】
-
Availability【别人都可以用】
-
Partition tolerance
该理论内容是:任何一个分布式系统,比如分布式哈希表,这三个性质中,最多只能满足两个,假如想要前两个性质,那么就不会得到第三个性质。
-
-
比特币的共识协议:
-
按照计算力来投票
每个节点都可以在本地组装出一个候选区块,把它认为合法的交易放在里面,然后开始尝试各种nonce值(占4 byte),看哪一个能满足不等式H(block header)≤target的要求。如果某个节点找到了符合要求的nonce,它就获得了记账权。
所谓的记账权,就是往比特币账本里写入下一个区块的权利。只有找到这个nonce,获得记账权的节点才有权利发布下一个区块。其他节点收到这个区块之后,要验证这个区块的合法性。
-
验证合法性:
- nBits域(目标阈值的编码)
- nonce
- 交易合法:合法签名、没有被双花
如果同时找到了nonce,那么就看谁在最长合法链上
-
-
-
05-BTC-实现
-
基于交易的账本模式
区块链是去中心化的账本,比特币使用的是基于交易的账本模式(transaction【交易】-based ledger【账本】)。系统当中并不会显示每个账户有多少钱。
-
基于账户的账本模式:以太坊
-
UTXO:
比特币全节点要维持一个UTXO集合,即还没有被花掉的输出的集合。以便快速检测double spending。
-
Transaction fee
-
total inputs=total outputs
有些交易total inputs略微大于total outputs。
假如输入1比特币,输出0.99比特币,另外0.01比特币作为交易费给获得记账权发布区块的节点。 -
主要还是出块奖励
出块奖励每隔21万个区块减半,21万个区块大概要挖4年。比特币系统设计的平均出块时间是10分钟,就是整个系统平均10分钟会产生一个新的区块。
-
-
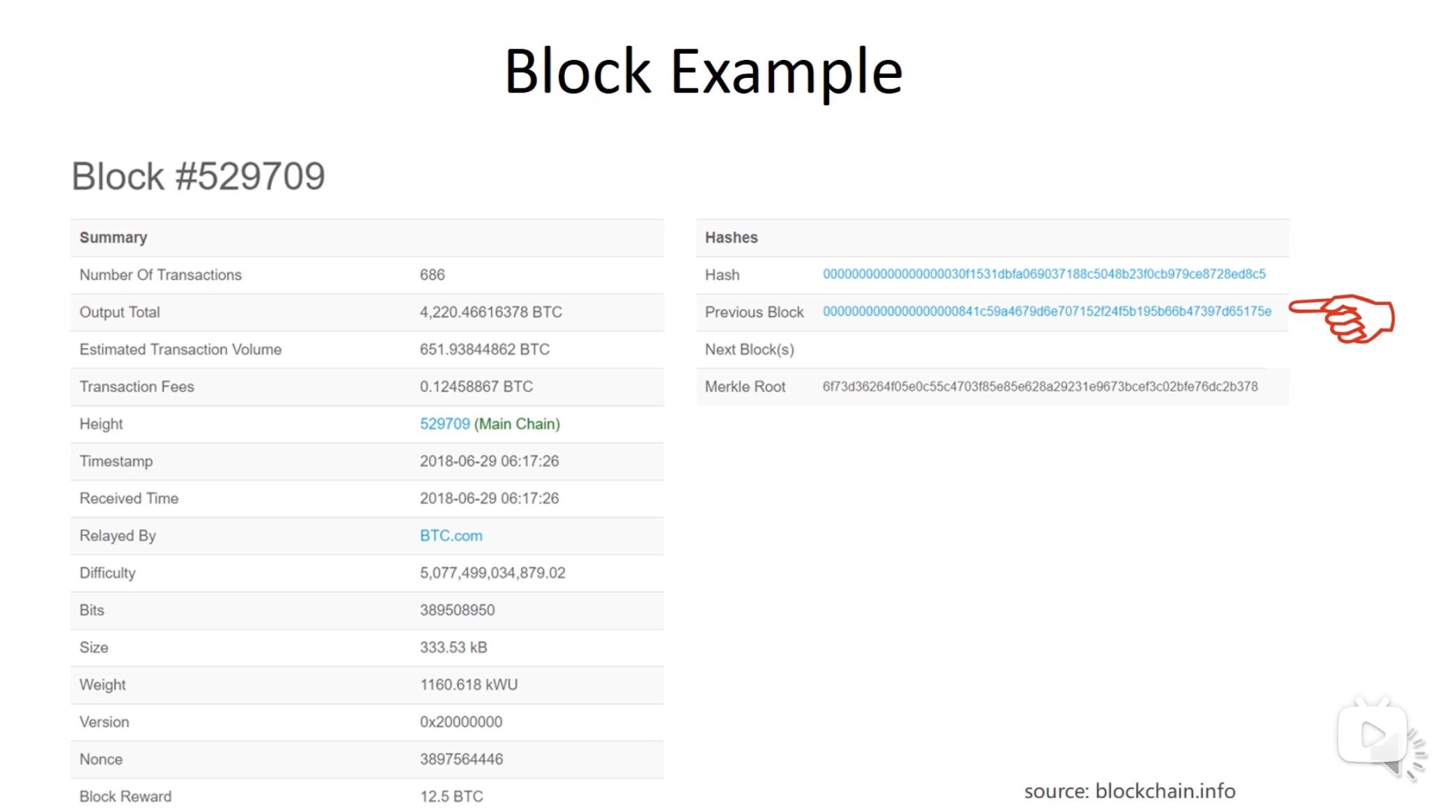
Block Example
-
注释:
一个区块的例子
第一行:该区块包含了686个交易
第二行:总输出XXX个比特币
第四行:总交易费(686个交易的交易费之和)
最下面一行:区块奖励(矿工挖矿的主要动力)
第五行:区块的序号
第六行:区块的时间戳
第九行:挖矿的难度(每隔2016个区块要调整挖矿的难度,保持出块时间在10分钟左右)
倒数第二行:挖矿时尝试的随机数右边:第一行:该区块块头的哈希值
第二行:前一个区块块头的哈希值
(注意:计算哈希值只算块头)
两个哈希值的共同点:前面都有一串0。是因为,设置的目标预值,表示成16进制,就是前面一长串的0。所以凡是符合难度要求的区块,块头的哈希值算出来都是要有一长串的0。
第四行:merkle root 是该区块中包含的那些交易构成的merkle tree的根哈希值。
-
提高搜索空间
挖矿时只改随机数不够,nonce只有2的32次方个可能的取值,还可以更改根哈希值。
可以改变铸币交易中的coinbase域,从而改变block header里的hashMerkleRoot,搜索空间增大到了2的92次方。
可以理解为,铸币交易没有输入信息,销毁比特币没有输出信息,所以可以输入额外的信息。因此人们常常通过销毁比特币的方式往区块链中增添他们想要的内容。
-
Bernoulli trial(伯努利实验)
挖矿过程每次尝试一个nonce可以看作是一个Bernoulli trial(伯努利实验)。每一个随机的伯努利实验就构成了一个伯努利过程。它的一个性质是:无记忆性。
可以用泊松过程来代替伯努利过程。我们真正关心的是系统出块时间,出块时间是服从指数分布。
-
progress free
指数分布也是无记忆性的。因为概率分布曲线的特点是:随便从一个地方截断,剩下一部分曲线跟原来是一样的。比如:已经等十分钟了,还没有人找到合法的区块,那么还需要等多久呢?仍然参考概率密度函数分布 ,平均仍然要等十分钟。将来还要挖多长时间,跟过去已经挖了多长时间是没有关系的。
-
保证挖矿公平性
算力强的矿工过去做的工作是更多的,过去尝试了那么多不成功的nonce之后,后面nonce成功的概率就会增大。以此progress free 是挖矿公平性的保证
-
-
/** Nodes collect new transactions into a block, hash them into a hash tree,
* and scan through nonce values to make the block's hash satisfy proof-of-work
* requirements. When they solve the proof-of-work, they broadcast the block
* to everyone and the block is added to the block chain. The first transaction
* in the block is a special one that creates a new coin owned by the creator
* of the block.
*/
class CBlockHeader
public:
// header
int32_t nVersion;
uint256 hashPrevBlock;
uint256 hashMerkleRoot;
uint32_t nTime;
uint32_t nBits;
uint32_t nNonce;
CBlockHeader()
SetNull();
SERIALIZE_METHODS(CBlockHeader, obj) READWRITE(obj.nVersion, obj.hashPrevBlock, obj.hashMerkleRoot, obj.nTime, obj.nBits, obj.nNonce);
void SetNull()
nVersion = 0;
hashPrevBlock.SetNull();
hashMerkleRoot.SetNull();
nTime = 0;
nBits = 0;
nNonce = 0;
bool IsNull() const
return (nBits == 0);
uint256 GetHash() const;
int64_t GetBlockTime() const
return (int64_t)nTime;
;
06-BTC-网络
-
网络结构
- 应用层:BitCoin Block Chain
- 网络层:P2P Overlay network
-
传播
-
种子节点
要加入P2P网络首先得知道至少有一个种子节点,然后你要跟种子节点联系,它会告诉你它所知道的网络中的其他节点,节点之间是通过TCP通信的,这样有利于穿透防火墙。当你要离开时不需要做任何操作,不用通知其他节点,退出应用程序就行了。别的节点没有听到你的信息,过一段时间之后就会把你删掉。
-
邻居节点
比特币网络的设计原则是:简单、鲁棒,而不是高效。每个节点维护一个邻居节点的集合,消息传播在网络中采取flooding的方式。节点第一次听到某个消息的时候,把它传播给去他所有的零度节点,同时记录一下这个消息我已经收到过了。下次再收到这个消息的时候,就不用转发给零度节点了。
邻居节点的选取是随机的,没有考虑底层的拓扑结构。比如一个在加利福尼亚的节点,它选的零度节点可能是在阿根廷的。这样设计的好处是增强鲁棒性,它没有考虑底层的拓扑结构,但是牺牲的是效率,你向身边的人转账和向美国的人转账速度是差不多的。
-
等待上链
比特币系统中,每个节点要维护一个等待上链的交易的集合。假如一个集合的交易都是等待写入区块链里的,那么第一次听到某个交易的时候,把这个交易加入这个集合,并且转发这个交易给节点,以后再收到这个交易就不用转发了,这样避免交易会在网络上无线的传播下去。转发的前提是该交易是合法的。
-
带宽
比特币协议对区块的大小有1M字节的限制。比特币系统采用的传播方式是非常耗费带宽的,带宽是瓶颈。按1M的区块大小限制来算的话,一个新发布的区块有可能需要几十秒,才能传输到网络大部分境地,这已经是挺长时间了,所以这个限制值不算小。
-
07-BTC-挖矿难度
- 比特币算法:SHA-256
2 256 2^256 2256
H ( b l o c k h e a d e r ) ≤ t a r g e t H(block \\, header) \\leq target H(blockheader)≤target
d i f f i c u l t y = d i f f i c u l t y 1 t a r g e t t a r g e t difficulty = difficulty1target \\over target difficulty=targetdifficulty1target
-
调整动机:出块时间变短
如果后面分岔多的话,前面某个区块里的某个交易,很可能就遭受分岔攻击,恶意节点会试图回滚。因为后面分岔多,算力就会分散,恶意节点得逞的概率更大。这个时候恶意节点就不需要51%的算力了,可能10%的算力就够了,因此出块时间不是越短越好。
-
调整内容
比特币协议中规定,每2016个区块后就要调整目标预值,这大概是每两个星期调整一次。即平均出块时间10分钟
t a r g e t = t a r g e t ∗ a c t u a l t i m e e x p e c t e d t i m e target = target*actual \\, time \\over expected \\, time target=target∗expectedtimeactualtime
08-BTC-挖矿
-
全节点
- 一直在线
- 在本地硬盘上维护完整的区块链信息
- 在内存里维护UTXO集合,一边快速检验交易的正确性
- 监听比特币网络上的交易信息,验证每个交易的合法性
- 决定哪些交易会被打包到区块里
- 监听别的矿工挖出来的区块,验证其合法性
- 挖矿
- 决定沿着哪条链挖下去
- 当出现等长的分叉链的时候,选择哪一个分叉
-
轻节点
- 不是一直在线
- 不用保存整个区块链,只要保存每个区块的块头
- 不用保存全部交易,只保存与自己有关的交易
- 无法检验大多数交易的合法性,只能校验与自己相关的那些交易的合法性
- 无法检测网上发布区块的正确性
- 可以验证挖矿的难度
- 只能检测那个是最长链,不知道哪个是最长合法链
-
挖矿设备演变
- CPU
- GPU
- ASIC( Application Specific Integrated Circuit )芯片
-
mining puzzle
一些新区块链可能采用相同算法,merge mining
-
矿池
矿主下连着很多矿工,矿工只负责计算哈希值。解决收入不稳定的问题。
-
计算矿工收入:
-
降低矿工难度
增大target,挖到一个nonce叫做share,计算这个矿工提交了多少share就可以了
coinbase域已经被矿主设置好了,所以偷不了
-
-
弊:
算力集中化,恶意攻击不一定要自己掌握算力
-
09-BTC-脚本
-
介绍
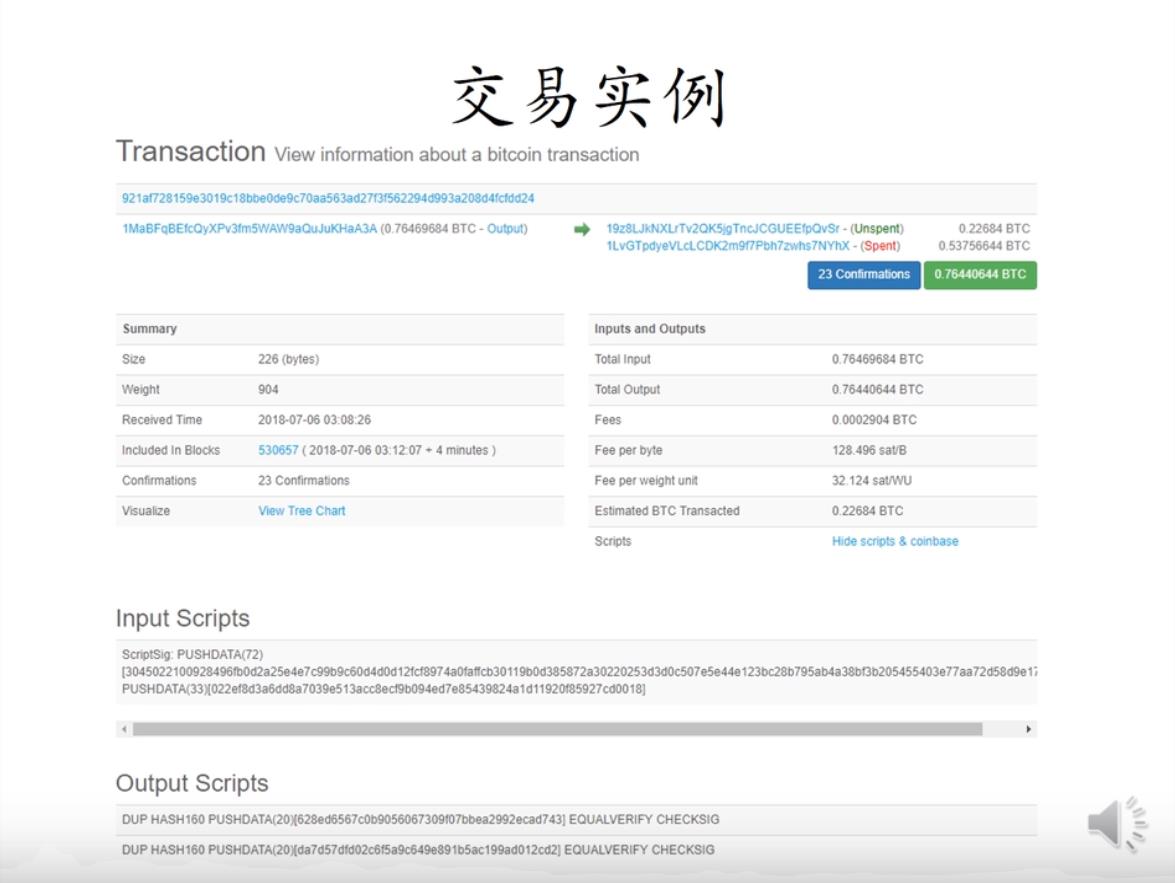
如图是比特币的一个交易实例。该交易有一个输入两个输出。左上角写着output,其实是这个交易的输入。右边两个输出,上面unspent即没有花出,下面spent表示已花出。该交易已经收到了23个确认,所以回滚的可能性很小了。
下面是这个交易的输入输出脚本,输入脚本包含两个操作,分别把两个很长的数压入栈里。比特币使用的脚本语言是非常简单的,唯一能访问的内存空间就是一个堆栈。不像通用的编程语言,像C语言C++那样有全局变量、局部变量、动态分配的内存空间,它这里就是一个栈,所以叫做基于栈的语言。这里输出脚本有两行,分别对应上面的两个输出。每个输出有自己单独的一段脚本。
交易结构
"result":
"txid": "921a...dd24", // transaction id
"hash": "921a...dd24",
"version": 1,
"size": 226,
"locktime": 0, // 用来设定交易的生效时间,0:立即生效
"vin": ..., // 输入脚本
"vout": ..., // 输出脚本
"blockhash": "0000000000000000000002c510d...4c0b",
"confirmations": 23,
"time": 1530846727, // 交易时间
"blocktime": 1530846727
"vin": [
"txid": "c0cb...c57b", // 来源交易的哈希值
"vout": 0, // 这个交易里的第几个输出
"scriptSig": // 输入脚本,下文写成input script
"asm": "3045...0018", // 输入脚本内容
"hex": "4830...0018"
,
],
"vout": [
"value": 0.22684000, // 单位是比特币
"n": 0, // 第几个输出
"scriptPubKey": // 输出脚本, 下文写成 output script
"asm": "DUP HASH160 628e...d743 EQUALVERIFY CHECKSIG", // 输出脚本内容
"hex": "76a9...88ac",
"reqSigs": 1, // 需要多少个签名才能兑现(单重多重)
"type": "pubkeyhash", // 公钥哈希
"address": ["19z8LJkNXLrTv2QK5....."] // 输出地址
,
"value": 0.53756644,
"n": 1,
"scriptPubKey":
"asm": "DUP HASH160 628e...d743 EQUALVERIFY CHECKSIG",
"hex": "76a9...88ac",
"reqSigs": 1,
"type": "pubkeyhash",
"address": ["1LvGTpdye....."]
],
-
注:
输入输出结构为一个数组,它可以有多个输入输出组成
输入输出脚本的形式
-
执行方式
先执行当前交易的输入脚本,然后执行源交易的输出脚本
P2PK(Pay to Public Key)
// P2PK
// input script
PUSHDATA(Sig)
// output script
PUSHDATA(PubKey)
CHEKSIG
P2PKH(Pay to Public Key Hash)
// P2PKH(Pay to Public Key Hash) 最常用
// input script
PUSHDATA(Sig)
PUSHDATA(PubKey)
// output script
DUP // 复制栈顶元素
HASH160
PUSHDATA(PubKeyHash)
EQUALVERIFY
CHECKSIG
P2SH(Pay to Script Hash)
-
给出的不是收款人公钥的哈希,而是赎回脚本的哈希
- 赎回脚本形式
- P2PK
- P2PKH
- 多重签名形式
- 赎回脚本形式
-
input script需要给出一些签名及一段序列化的 redeemScript,验证分为两步
- 验证序列化的 redeemScript是否与output script 中的哈希值匹配
- 反序列化并执行 redeemScript,验证input script中给出的签名是否正确
-
本质:
把复杂度从输出脚本转移到输入脚本
// P2SH实现P2PK
// input script
PUSHDATA(Sig)
PUSHDATA(serialized redeemScript)
// output script
HASH160
PUSHDATA(redeemScriptHash)
EQUAL
// redeemScript
PUSHDATA(PubKey)
CHECKSIG
// P2SH实现多重签名
// input script
FALSE // 忽略这一行,这个是应对内部bug的
PUSHDATA(Sig_1)
PUSHDATA(Sig_2)
...
PUSHDATA(Sig_M)
PUSHDATA(serialized RedeemScript)
// output script
HASH160
PUSHDATA(RedeemScriptHash)
EQUAL
// redeemScript
M
PUSHDATA(pubkey_1)
PUSHDATA(pubkey_2)
...
PUSHDATA(pubkey_N)
N
CHECKMULTISIG
-
注
这个输入脚本,是电商花掉这笔输出的时候提供的。用户付款的交易,输出脚本只要知道这个哈希值就可以了
所有代码都省略了OP_前缀
Proof of Burn
// output script
RETURN
[zero or more ops or text]
这样的输出永远花不出去,这个证明销毁比特币的方法
其实输出金额为0,就相当于只付了交易费,这样不用保存在UTXO里
10-BTC-分叉
-
state fork
- deliberate fork:forking attack
-
protocal fork:对协议产生分歧
-
hard fork:硬分叉
-
比特币中的区块大小限制(block size limit)。1M->4M
1M=1百万 。一个交易大概认为是250个字节 1百万/250=4000 一个区块大概是4000个交易 平均10分钟出现一个区块 4000/(60×10)=7 大概每秒钟产生7笔交易即7tx/sec 这个传输速度是非常低的。
新节点会认为4M和1M都是合法的,旧节点不认4M的,所以这两条链都不会消失
-
-
soft fork:软分叉
-
block size limit。假设1M->0.5M
新节点不认原来区块,旧节点都认。所以就节点如果不更新软件,会一直跟在最长合法链之后然后被丢弃。所以不会产生永久分叉。
-
coinbase域
coinbase前8个字节作为随机nonce。
有人建议把后面的字节作为UTXO的根哈希值
-
Pay to Script Hash
-
-
旧节点不认的是硬分叉,旧节点认可的是软分叉。
软分叉:只要系统有多数节点更新,就不会产生永久分叉
硬分叉:只要系统中有节点不更新协议,就会产生永久分叉
-
11-BTC-问答
-
转账交易时如果接收者不在线怎么办?
这个时候不需要接收者在线,转账交易只不过是在区块链上记录一下,把一个人账户上的比特币转移到他人的账户上,他人是否当时连接在比特币网络上是没有影响的。
-
假设某个全节点收到了一个转账交易,有没有可能转账交易中接收者的收款地址是这个节点以前从来没有听说过的?
这是可能的。比特币账户在创建的时候是不需要通知其他人的,在本地产生一个公私钥对就可以了。只有在产生收款地址以后第一次收到钱时,其他节点才知道这个账户的存在。
-
如果账户的私钥丢失了,该怎么办?
私钥丢失之后是没有办法的。该账户上的钱就变成了死钱,永远取不出来了。在去中心化的系统里,是没有人可以给你重置密码的。
-
如果私钥泄露了怎么办?
比如你发现自己账户上出现一些可疑的交易,这个时候该怎么办?这时应该尽快把自己账上的钱转到另外一个安全的账户上,这个也跟我们平时的生活体验不太一样,如果在银行账户上出现一些可疑的交易,我们首先想到的是通知银行,能否把密码重置,账户冻结,免得别人把钱取走,而这些在区块链的世界里都是做不到的。
-
如果转账的时候写错了地址怎么办?
这是没有办法的。如果写错了地址而转错了人,我们也没有办法取消已经发布了的交易,比特币当中转账交易一旦发布到区块链里,就没有办法取消了。当转错了地址,如果我们知道是转给了谁,可以跟对方进行联系。如果不知道转的是谁的地址,或者是不存在的地址,那就没有办法了。
-
接着问一个问题:proof of burn 、OP_RETURN这些实际当中是怎么操作的?当一个全节点收到一个转账交易的时候,它首先要检查一下,这个交易的合法性,只有合法的交易才会被写入区块链里。而OP_RETURN这个语句是无条件的返回错误,既然如此,它怎么可能通过验证,怎么可能被写到区块链里呢?
验证当前交易合法性的时候,不会执行这个语句。即当前交易的输出脚本在验证交易合法性的时候,是不会被执行的。只有有人想花这笔钱,后面再有一个交易,要花这个交易的输出的时候才会执行这个交易的输出脚本。
-
挖矿时会不会有的矿工偷答案?
不会。发布的区块里有coinbase transaction,里面有一个收款人地址,是挖到矿的矿工的地址。假如A挖到了矿,里面就是A的收款地址。如果要偷答案的话,就要把A的地址换成自己的地址,而地址如果一变化,coinbase transaction的内容就发生了改变。这样会导致什么?导致merkle tree的根哈希值变化,因为这个交易和区块中所包含的其他交易是合在一起构成了merkle tree。任何一个地方发生改变,根哈希值就会变。而nonce是在块头里面,根哈希值也是在块头里面,block header的内容发生了变化之后,原来找到的nonce就作废了。所以不可能偷答案,因为每个矿工挖到的nonce是和他自己的收款地址绑定在一起的。
-
怎么判断交易费该给哪个矿工?即事先怎么知道哪个矿工会挖到矿?
事先不需要知道哪个矿工会得到这个交易费。交易费是怎么算的?total inputs>total outputs,其差额就是交易费。发布的交易里面,一个交易可以有很多个输入,也可以有很多个输出,总输入减总输出就是交易费。给谁不需要事先知道,哪个矿工挖到矿了,就可以把这个区块里所包含的交易差额收集起来,作为他自己的交易费
12-BTC-匿名性
-
比特币系统中什么情况下有可能破坏匿名性?
比如网上购物,比特币交易允许有多个输入多个输出。而多个输入有可能是同一个人,因为这个人可能同时控制了这两个账户的私钥。
-
比特币系统是运行于应用层(application layer)的,底层是(network layer)。所以要提高匿名性可以从两个方面入手。
-
网络层怎么提高匿名性?
而网络层的匿名性是比较好解决的。区块链是个新生事物,但网络层的匿名性学术界已经有了很好的方案:多路径转发。跟洋葱路由(TOR)是一样的原理。即消息不是由发出者直接发送给接收者,中间要经过很多次转发。中间的每一个节点,只知道它的上一个节点是谁,但并不知道最早发出消息的人是谁。当然中间一些节点可能是坏的,但路径上只要有一个节点是诚实的,就能够把最初发起人的身份隐藏起来。这也是洋葱路由的基本原理。 -
应用层怎么提高匿名性?
把不同人的币混在一起(coin mixing),即把你的身份跟别人的身份混在一起,让别人分不清楚谁是谁。不光是区块链,在其他各个需要匿名的领域都能用到。有一些专门做coin mixing的网站,提供一定的服务收取一定的服务费。所有想做coin mixing的人把币发给网站,网站内部进行一些重组,然后你再把币取回来,这时取出的币就不是发布到网站上的币了,它是随机抽取一些币给你。
-
-
为什么保护隐私性难度挺大?
本质原因是区块链是公开的,而且是不可篡改的。不可篡改性对于隐私保护来说是灾难性的。
零知识证明
-
概念:
零知识证明是指一方(证明者)向另一方(验证者)证明一个陈述是正确的,而无需透露除该陈述是正确的外的任何信息。
-
例子:
要证明一个账户是我的,只需要我给出私钥就行。但私钥不能直接泄露,所以就给出由私钥产生的签名,假设对方是知道这个账户的公钥的,那么就可以验证签名的正确性。这是不是一个零知识证明其实是有争议的,因为我给出了私钥之外的其他信息,具体算不算要看应用场合。
同态隐藏
零知识证明的数学基础是同态隐藏

-
第一个性质说明加密函数值E不会出现碰撞,这跟哈希函数有所不同,哈希函数是可能出现碰撞的。这个性质反过来说明如果E(x)和E(y)是相等的,那么x、y也是相等的。(该语句是上面语句的逆否命题)
-
第二个性质说明加密函数是不可逆的,知道加密后的值,没办法推出加密前的值。
-
第三个性质是最重要的,叫作同态运算。它说的是对加密之后的函数值进行某些代数运算,等价于对这些输入直接进行代数运算然后再加密。
同态加法:加密值的和等于和的加密。
同态乘法:加密值的乘积等于积的加密。 -
例子:
所示Alice想要向Bob证明她知道一组数x和y使得x+y=7,
同时不让Bob知道x和y的具体数值。-
解答
Alice把E(x)和E(y)的数值发给Bob
Bob通过收到的E(x)和E(y)计算出E(x+y)的值
Bob同时计算E(7)的值,如果E(x+y)=E(7),那么验证通过,否则验证失败
-
盲签方法
- 用户A提供SerialNum,银行在不知道SerialNum的情况下返回签名Token,减少A的存款
- 用户A把SerialNum和Token交给B完成交易
- 用户B拿SerialNum和Token给银行验证银行验证通过,增加B的存款
- 银行无法把A和B联系起来
零币和零钞(专为匿名性设置的加密货币)
零币和零钞在协议层就融合了匿名化处理,其匿名属性来自密码学保证
-
零币(zerocoin )系统中存在基础币和零币,通过基础币和零币的来回转换,消除旧地址和新地址的关联性,其原理类似于混币服务
零币中存在基础币(比如比特币)和零币。用的时候要证明本来是有一个基础币,让基础币变得不能花费(unspendable),然后换取一个零币,零币在花的时候只需要用零知识证明你花掉的币是系统中存在的某一个合法的币就行了,但是不用透露你花的是系统中具体的哪一个币。
-
零钞(zerocash)系统使用zk-SNARKs协议,不依赖一种基础币,区块链中只记录交易的存在性和矿工用来验证系统正常运行所需要关键属性的证明。区块链上既不显示交易地址也不显示交易金额,所有交易通过零知识验证的方式进行。
零钞没有基础币,是完全的零币。零钞和零币也不是100%匿名安全的,在影响匿名安全的因素中依然有一个因素无法解决,就是与实体发生交互的时候。比如有人想拿这些币干坏事,把很大的金额转换成这种加密货币的时候,或者是把这些加密货币转换成现金的时候,仍然要暴露身份。这些加密货币数学上设计的再好,只是说对已经在区块链当中的转账有匿名性,跟外界交互的匿名性仍然是一个弱点。所以它依然无法提供100%的匿名。
13-BTC-思考
-
哈希指针
哈希值本身就是指针
-
那么怎么才能找到前一个区块的内容呢?
全节点一般是把这些区块存储在一个(key,value)数据库里面。key是区块的哈希,value就是区块的内容。一个常用的key value数据库是level DB。所谓的区块链这种链表结构实际上是在level DB里面用哈希值算出来的。只要你掌握了最后一个区块的哈希值,那么你通过level DB的查找,哈希值key对应的value就可以把最后一个区块的内容取出来。然后这个区块块头里面,又有指向前一个区块的哈希值。那么再去查找key和value,可以找到前一个区块的内容,以此类推,一步一步往前找,最终能够把整个区块链都找出来。
-
-
区块恋
就是指,把一个私钥分成几份,有几个人各自保管,只有最终大家都拿出自己的部分私钥,才能合成完整的私钥
但是如果从中截断,一对情侣中一个人分手之后想把钱取出来,他已经知道了其中一半的私钥,只要把剩下的128位私钥猜出来就行了。私钥长度减少一半并不意味着难度降低一半,难度由2的256次方降到了2的128次方,前者远远大于后者,破解难度降了很多。如果是四个合伙人的例子,有三个人瞒着另一个人要把钱取出来,那么他们只需要尝试2的64次方就可以了。
因此对于多个人的共享账户,不要用截断私钥的方法,而最好采用多重签名,多重签名中用到的每一个私钥都是独立产生的。而且多重签名也提供一些别的灵活性,比如可以要求N个人当中任意给出M个签名就可以了。
-
分布式共识
严格来说,比特币并没有取得真正意义上的共识,因为取得的共识随时有可能被推翻,比如出现了分叉攻击。你以为已经取得了一个共识,分叉攻击后系统会回滚到前一个状态,从理论上说甚至有可能回滚到创世纪块。
-
比特币的稀缺性
矿工挖矿的原因是为了获得收益,挖矿的收益要大于开销才是有利可图的。要吸引别人来挖矿,要么增加挖矿的收益,要么降低挖矿开销。任何一个新发行的加密货币,都有一个能启动的问题。早期为了吸引矿工来挖矿,可以给矿工更多的收益。比特币的做法是:①早期难度设置的比较低。②早期的出块奖励比较高。
实际上,比特币这种总量恒定的性质是不适合用来做货币的。后面讲的以太坊就没有出块奖励定期减半的做法,一些新型的货币甚至要自带通胀的功能,每年要把货币的通行量提高一定的比例。因为稀缺的东西是不适合用来做货币的,通货膨胀会导致钱变得更不值钱了,但一个好的货币是要有通货膨胀的功能的。
-
量子计算
随着量子计算的发展,量子计算机计算力变得越来越强大,加密货币会不会变得不安全了?
这种担心是没必要的:
①量子计算技术离实用还有很长一段距离,在比特币的有生之年不一定能产生实质性的联系。如果量子计算在将来能强大到破坏加密体系的话,首先会冲击的是传统金融业。比如我们在网上进行的很多金融活动:网上银行、网上转账、网上支付,都会变得不安全了。所以与其担心量子计算对比特币的冲击,还不如担心量子计算对传统金融业的冲击,因为大多数的钱还是放在传统金融业里面的,加密货币的市值只占了现代金融体系当中的很小一部分。
②比特币当中没有把账户的公钥直接暴露出来,而是用公钥取哈希之后得到一个地址。比特币当中用的非对称加密体系,从私钥是可以推导出公钥的。所以只要把私钥保管好,公钥其实丢了也没有关系。从公钥显然是不能推出私钥的,否则就麻烦了。
假设将来量子计算技术发达了,能够从公钥中推出私钥,那怎么办呢?比特币在设计的时候又加了一层保护,没有用公钥本身,而是用公钥的哈希。所以如果有人想偷你账户上的钱的话,首先是要用地址推导出你的公钥,相当于把公钥的哈希值进行逆运算,而这一点即使是用量子计算机也是没有办法完成的。
以上是关于北京大学肖臻老师《区块链技术与应用》公开课笔记-BTC的主要内容,如果未能解决你的问题,请参考以下文章