r语言txt数据读入问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了r语言txt数据读入问题相关的知识,希望对你有一定的参考价值。
reportcard<-read.table(file="D:/R/reportcard.TXT",header=true)
在读取txt文件时为什么提示Error in read.table(file = "D:/R/reportcard.TXT", header = true) :
object 'true' not found??以下是远数据表。
card name class sex politic chinese english math
20060001 陈文章 1 男 93 89 87 85
20060002 张强 1 男 84 86 89 92
20060003 李芬 1 女 95 90 93 89
20060004 陆洋 2 男 83 78 76 86
20060005 姚舒 3 女 90 92 94 95
20060006 丁琼玉 2 女 81 84 83 78
20060007 钟达峰 2 男 78 83 75 82
20060008 朱桐 3 男 92 94 96 96
20060009 吴燕 1 女 87 91 90 94
20060010 曹斌 3 男 81 80 82 87
20060011 宋令文 3 男 88 96 97 95
20060012 杨华 2 女 95 93 92 92
那么大小写有什么限制??
那么大小写有什么限制??
那么大小写有什么限制??
那么大小写有什么限制??
追答R语言里面只有TRUE,没有true!
本回答被提问者采纳 参考技术B header=ture 这个地方,应该是 header=TURE,一般都直接写 header=TR语言︱文件读入读出一些方法罗列(批量xlsx文件数据库文本txt文件夹)
笔者寄语:小规模的读取数据的方法较为简单并且多样,但是,批量读取目前看到有以下几种方法:xlsx包、RODBC包、批量转化成csv后读入。
R语言中还有一些其他较为普遍的读入,比如代码包,R文件,工作空间等。
source #读取R代码
dget #读取R文件
load #读取工作空间
————————————————————————————————
SPSS-STATA格式的读入包——foreign
读取其他软件的格式foreign
install.packages("foreign")
#读取SPSS stata sas
spss<-read.spss("hsb2.sav",to.data.frame=T)
stata<-read.dta("hsb2.dta")
————————————————————————————————
一、小规模数据——简单读入方式
read.table、write.table 、read.csv 、write.csv、readLine(字符型格式常用)。
常见格式:
read.table(file, header = FALSE, sep = "", quote = "\\"'",
dec = ".", skip = 0,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#")read.table(file.choose())sep指定分隔符,默认是空格; quote是引号,默认就是双引号; dec是小数点的表示,默认就是一个点; skip是确定是否跳过某些行; strip.white确定是否消除空白字符; blank.lines.skip确定是否跳过空白行; comment.char指定用于表示注释的引导符号。
在使用read.table、read.csv读取字符数据时,会发生很多问题:
1、问题一:Warning message:EOF within quoted string; 需要设置quote,read.csv("/..csv",quote = "");
2、问题二:出现所有的数据被加入了双引号,比如“你好”,“睡觉”;
解决方案:先as.character(x[1:5]),可以发现比如”\\”你好\\”“,这样的格式,就可以用sep = "\\""来解决。
其中非结构化数据,在读入的时候会出现很多分隔符的问题,
可以见博客:【R】数据导入读取read.table函数详解,如何读取不规则的数据(fill=T)
——————————————————————————————————————————————————————————————————
二、数据库读入——RODBC包
RODBC包中能够基本应付数据库读入。一般数据数据库读入过程中主要有:
连接数据库(odbcConnect)、读入某张表(sqlFetch)、读某表某指标(sqlQuery)、关闭连接(close)
还有一些功能:
把R数据读入数据库(sqlSave)、删除数据库某表(sqlDrop)
#安装RODBC包
install.packages("RODBC")
library(RODBC)
mycon<-odbcConnect("mydsn",uid="user",pwd="rply")
#通过一个数据源名称(mydsn)和用户名(user)以及密码(rply,如果没有设置,可以直接忽略)打开了一个ODBC数据库连接
data(USArrests)
#将R自带的“USArrests”表写进数据库里
sqlSave(mycon,USArrests,rownames="state",addPK=TRUE)
#将数据流保存,这时打开SQL Server就可以看到新建的USArrests表了
rm(USArrests)
#清除USArrests变量
sqlFetch(mycon, "USArrests" ,rownames="state")
#输出USArrests表中的内容
sqlQuery(mycon,"select * from USArrests")
#对USArrests表执行了SQL语句select,并将结果输出
sqlDrop(channel,"USArrests")
#删除USArrests表
close(mycon)
#关闭连接——————————————————————————————————————————————————————————————————
三、批量读取——xlsx包
首先尝试用R包解决。即xlsx包。
xlsx包在加载时容易遇到问题。基本都是由于java环境未配置好,或者环境变量引用失败。因此要首先配置java环境,加载rJava包。
百度了一下,网上已有很多解决方案。我主要是参考这个帖子,操作步骤为:
1、 安装最新版本的java。如果你用的R是64位的,请下载64位java。
下载地址: http://www.java.com/en/download/manual.jsp
要安装在 C:\\Program Files\\Java 下面,win8的尤其小心不要安装为C:\\Program Files(x86)。可能是R在读取路径时,对x86这样的文件夹不大好识别吧,我第一次装在x86里,读取是失败的。
2、在R中加载环境,即一行代码,路径要依据你的java版本做出更改。R
Sys.setenv(JAVA_HOME='C:\\\\Program Files\\\\Java\\\\jre1.8.0_45\\\\')
之后再加载rjava包或者xlsx包就成功了。
xlsx包加载成功后,用read.xlsx就可以直接读取xlsx文件,还可以指定读取的行和段,以及第几个表,以及可以保存为xlsx文件,这个包还是很强大的。
但是这个方法存在两个问题:
1、不是所有的公司电脑都能自由的配置java环境。很多人的权限是受限的。而且有些公司内部应用是在java环境下配置的。就算你找了IT去安装java,但是一些内部应用可能会因为版本号兼容问题而出错,得小失大。
2、用xlsx包读取数据,在数据量比较小的时候速度还是比较快的。但是如果xlsx本身比较大,包含数据多,read.xlsx效率会很低,不如data.table包的fread读取快捷以及省内存。但fread函数不支持xlsx的读入。。。
(参见这篇帖子,里面对千万行数据,fread也只用了10秒左右,比常规的read.table或者read.csv至少省时一倍)
综上,由于java环境的复杂性与兼容度,还有xlsx包本身读取速度的限制,用xlsx包读取xlsx包的方法,更适合于:
1、个人电脑,自己想怎么玩都无所谓,或者高大上的linux, mac环境
2、数据量不会特别大,而且excel文件很干净,需要细节的操作
实际操作案例:
批量写入
#1、读取xlsx中所有的sheet表格
#如果像vector一样定义List??——list()函数来主动定义,用data.list[[i]]来赋值
data.list<-list()
for (i in 1:2)
data.list[[i]]=read.xlsx("C1.xlsx",i)
#3、利用List批量读出操作
#难点:如果构造输出表格的名称——paste来构造名称
flie=list()
xlsxflie=paste(1:2,".xlsx",sep="")
for(i in 1:2)
flie[[i]]=paste("C:/Users/long/Desktop/",xlsxflie[i],sep="")
write.xlsx(data.list2[[i]],file)
其中出现了一个小错误:Error in file[[i]] : object of type 'closure' is not subsettable
这一错误是因为我写错函数名字了... file->flie(详情见:http://bbs.pinggu.org/thread-3142627-1-1.html)
——————————————————————————————————————————————————————————————————
四、批量读入XLSX文件——先转换为CSV后读入
CSV读入的速度较快,笔者这边整理的是一种EXCEL VBA把xlsx先转换为csv,然后利用read.csv导入的办法。
WPS中调用VBA需要额外下砸一个插件,
之后应用list.files以List方式读入。
#lapply读取法
filenames <- list.files("C:/Users/a.csv", pattern = ".csv",full.names = TRUE) #变成list格式
#没有full.names = TRUE,都会出现cannot open file: No such file or directory
name=function(x)
read.csv(x,header=T)
datalist <- lapply(filenames,name) #filenames执行name函数——————————————————————————————————————————————————————————————————
五、批量读入文件夹中的指定文件(如*.xlsx)
代码思路:先遍历文件夹(list.files),然后通过循环依次读写(read.xlsx)。为什么lsit.files不能直接把完整数据读入文件?——需要read.xlsx这一步骤
##批量读入文件夹中的xlsx文件
#如何批量读取一个文件夹中的各种txt文件
micepath <- "C:/Users/long/Desktop"
micefiles <- list.files(micepath, pattern = "*.xlsx$", full.names = TRUE)
##文件信息放入list中
files=list()
for (i in 1:2)
files[i]=read.xlsx(micefiles[[i]],header = F,1)
——————————————————————————————————————————————————————————————————
五、批量读入文件夹中的文本文件(*.txt),并生成名称、文档数据框
——用在情感分析中情感词的打分数
代码思路:先遍历文件夹中所有txt(list.files)、构造文本读入函数(read.txt)、找文本名字(list.files)、然后生成数据框(as.data.frame)
##批量读入txt文件,并将文本放入同一个数据框
reviewpath <- "F:/R语言/R语言与文本挖掘/情感分析/数据/rawdata/review_sentiment/train2"
completepath <- list.files(reviewpath, pattern = "*.txt$", full.names = TRUE)
######批量读入文本
read.txt <- function(x)
des <- readLines(x) #每行读取
return(paste(des, collapse = "")) #没有return则返回最后一个函数对象
review <- lapply(completepath, read.txt)
#如果程序警告,这里可能是部分文件最后一行没有换行导致,不用担心。
######list转数据框
docname <- list.files(reviewpath, pattern = "*.txt$")
reviewdf <- as.data.frame(cbind(docname, unlist(review)),
stringsAsFactors = F) 其中,list.files()中,full.names=T代表读入文件+信息,full.names=F代表读入文件名字。
本代码来源于书《数据挖掘之道》情感分析章节。
——————————————————————————————————————————————————————————————————
六、excel的xlsx格式读取——openxlsx包
跟xlsx包可以一拼,为什么没有特别好的excel包,因为微软的软件不开源,而且内嵌设置时长变化,所以么有一款统一的好函数包,来进行读取。
library(openxlsx)
data=read.xlsx("hsb2.xlsx",sheet=1)——————————————————————————————————————————————————————————————————
七、write.table读出txt文本
write.table(data,"names",
quote = F,row.names = FALSE, col.names = FALSE)id names
1 “您好”
2 “格式”
3 “读取”如果我想得到,这样格式的呢:
您好 格式 读取需要调整ecol,默认的ecol="\\n",就是回车,所以会造成换行,所以需要换成“\\r”,同时中间需要有空格分开,所以最终ecol="\\r\\ "用【\\+空格】来表达空格

——————————————————————————————————————————————————————————————————————
八 文件夹读入
文件夹读入的方式也挺多的。
第一步:获取文件夹内全文件内容
两种函数:dir()以及list.files()
dir('C:\\\\Users\\\\long\\\\Desktop\\\\',pattern = "txt$")
list.files('C:\\\\Users\\\\long\\\\Desktop\\\\',pattern = "txt$")第二步:生成系统路径
> paste("C:\\\\Users\\\\long\\\\Desktop\\\\","txt")
[1] "C:\\\\Users\\\\long\\\\Desktop\\\\ txt"
> file.path("C:\\\\Users\\\\long\\\\Desktop","txt")
[1] "C:\\\\Users\\\\long\\\\Desktop/txt"对比两者,一般用paste来生成系统路径的时候,在最终结果,结合的地方会多一个空格,当然也可以用去空格的方式排除,但是不够好。
所以可以用file.path的方式直接生成,比较方便,而且绝对正确。
————————————————————————————————
应用一:R语言中大样本读出并生成txt文件
笔者进过分词处理之后的文本词量有3亿+个词,一下子导出成txt马上电脑就死机,报错内存不足的问题。
于是在找各种办法解决如何生成一整个TXT文件。于是就有以下比较简单的办法,可以直接实现。
步骤一:先把分词内容拆分成几个部分,输出成多个txt文件;
步骤二:用windows自带的CMD里面的指令,来生成特定的TXT文件。
详情可见(参考与百度知道):
1、使用组合键“Win + R”打开运行窗口,输入“cmd”命令,进入命令行窗口。
2、在命令行窗口,进入需要合并的Txt文件的目录,如下图所示已进行“F:\\stock”目录。

3、确认目录正确后,输入“type *.txt >>f:\\111.txt”,该命令将把当前目录下的所有txt文件的内容输出到f:\\111.txt。
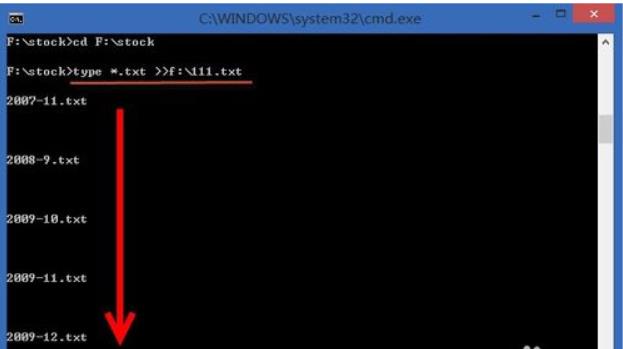
4、到此,打开合并后的f:\\111.txt,即可看到多个Txt文件都已按顺序合并到F盘的111.txt文件中。
————————————————————————————————————————————
应用二:R语言中,用write.csv时候,用office打开,多出了很多行?
如果文本字符长度很大,那么就会出现内容串到下面一行的情况,譬如10行的内容,可能变成了15行。好像office默认单个单元格的字符一般不超过2500字符,超过就会给到下一行。
所以笔者在导入5W条数据时候,多出了很多行,于是只能手动删除。
如果用txt格式导出,用Notepad++打开是好的,但是用excel打开又多出来不少行,所以用excel打开是用代价的。
但是由于excel是最好的导入SQL的格式,于是不得不手工删除,同时牺牲一部分的内容。
————————————————————————————————————————————
应用三:R语言中,用tcltk读入时候,报错?
Error: OutOfMemoryError (Java): Java heap space解决方案从两个方面着手,1、加大内存如-Xmx1024m;2、检查优化代码及时释放内存
————————————————————————————————————————————
应用四:用R语言来移动图片文件——file.copy
for (i in 1:length(selectname))
originpath = paste(origin_source,selectname[i],sep = '')
savepath = paste(save_path,selectname[i],sep = '')
file.copy(originpath, save_path)
可以看到 file.copy是主要用来做移动的函数,originpath是路径名(细致到文件名称以及后缀),savepath可以是文件夹名称。
以上是关于r语言txt数据读入问题的主要内容,如果未能解决你的问题,请参考以下文章