1. HashSet集合存储数据的结构(哈希表)
1.1 什么是哈希表?
哈希表底层使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。
1.2 哈希表存储数据结构原理
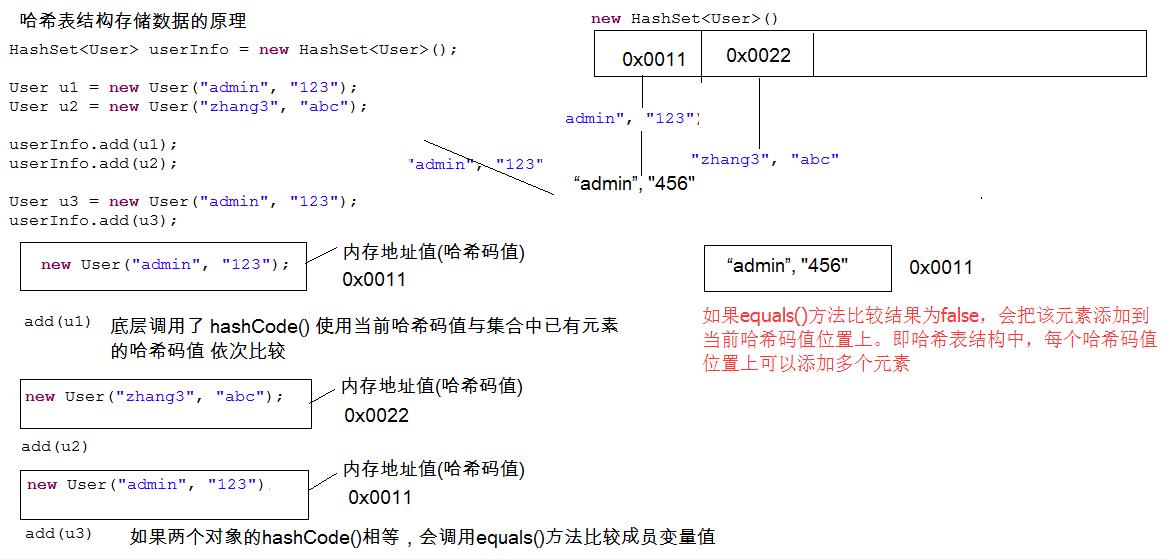
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法其实就是Object类中的hashCode方法。由于任何对象都是Object类的子类,所以任何对象也拥有这个方法。即就是在给哈希表中存放对象时,会调用对象的hashCode方法,算出对象在表中的存放位置,这里需要注意,如果两个对象hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个值存放在哈希表中。
1.3 哈希表存储数据结构原理图
2. hash
hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
-
如果散列表中存在和散列原始输入
K相等的记录,那么K必定在f(K)的存储位置上 -
不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞
-
如果两个hash值不同(前提是同一hash算法),那么这两个hash值对应的原始输入必定不同
3. hashCode
-
hashCode的存在主要是为了查找的快捷性,hashCode是用来在散列存储结构中确定对象的存储地址的
-
如果两个对象equals相等,那么这两个对象的hashCode一定也相同
-
如果对象的equals方法被重写,那么对象的hashCode方法也尽量重写
-
如果两个对象的hashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
-
如果根据equals方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
4. hashCode作用
我们知道Set里面的元素是不可以重复的,那么如何做到?
Set是根据equals()方法来判断两个元素是否相等的。比方说Set里面已经有1000个元素了,那么第1001个元素进来的时候,最多可能调用1000次equals方法,如果equals方法写得复杂,对比的东西特别多,那么效率会大大降低。使用HashCode就不一样了,比方说HashSet,底层是基于HashMap实现的,先通过HashCode取一个模,这样一下子就固定到某个位置了,如果这个位置上没有元素,那么就可以肯定HashSet中必定没有和新添加的元素equals的元素,就可以直接存放了,都不需要比较;如果这个位置上有元素了,逐一比较,比较的时候先比较HashCode,HashCode都不同接下去都不用比了,肯定不一样,HashCode相等,再equals比较,没有相同的元素就存,有相同的元素就不存。如果原来的Set里面有相同的元素,只要HashCode的生成方式定义得好(不重复),不管Set里面原来有多少元素,只需要执行一次的equals就可以了。这样一来,实际调用equals方法的次数大大降低,提高了效率。
5. HashSet存储JavaAPI中的类型元素
给HashSet中存储JavaAPI中提供的类型元素时,不需要重写元素的hashCode和equals方法,因为这两个方法,在JavaAPI的每个类中已经重写完毕,如String类、Integer类等。
举个栗子:
public class HashSetDemo {
public static void main(String[] args) {
//创建HashSet对象
HashSet<String> hs = new HashSet<String>();
//给集合中添加自定义对象
hs.add("zhangsan");
hs.add("lisi");
hs.add("wangwu");
hs.add("zhangsan");
//取出集合中的每个元素
Iterator<String> it = hs.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
}
}
输出结果:
wangwu
lisi
zhangsan
6. HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一
举个栗子:
自定义Student类
public class Student {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (obj == null)
return false;
if (this == obj)
return true;
if (!(obj instanceof Student)){
return false;
}
Student other = (Student) obj;
return this.age == other.age && this.name.equals(other.name);
}
}
创建HashSet集合,存储Student对象
public class HashSetDemo {
public static void main(String[] args) {
//创建HashSet对象
HashSet<Student> hs = new<Student> HashSet();
//给集合中添加自定义对象
hs.add(new Student("zhangsan",21));
hs.add(new Student("lisi",22));
hs.add(new Student("wangwu",23));
hs.add(new Student("zhangsan",21));
//取出集合中的每个元素
Iterator it = hs.iterator();
while(it.hasNext()){
Student s = (Student)it.next();
System.out.println(s);
}
}
}
输出结果:
Student [name=lisi, age=22]
Student [name=zhangsan, age=21]
Student [name=wangwu, age=23]
7. 写在后面
保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须重写hashCode和equals方法建立属于当前对象的比较方式。