Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop MapReduce编程 API入门系列之倒排索引(二十四)相关的知识,希望对你有一定的参考价值。
不多说,直接上代码。





2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-12 21:54:05,166 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-12 21:54:05,169 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-12 21:54:05,477 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 3
2016-12-12 21:54:05,539 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:3
2016-12-12 21:54:05,810 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1000661716_0001
2016-12-12 21:54:06,184 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2016-12-12 21:54:06,185 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1000661716_0001
2016-12-12 21:54:06,193 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2016-12-12 21:54:06,220 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2016-12-12 21:54:06,297 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2016-12-12 21:54:06,314 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1000661716_0001_m_000000_0
2016-12-12 21:54:06,374 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:54:06,433 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@6b4d160c
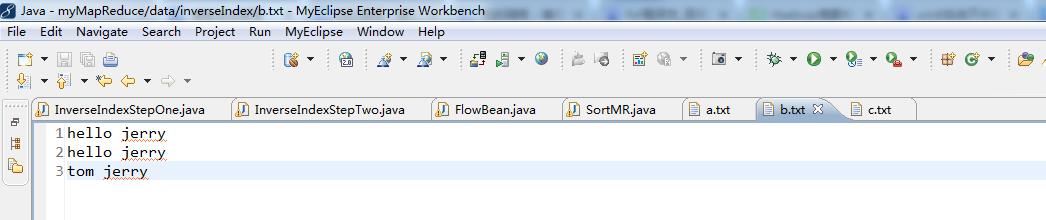
2016-12-12 21:54:06,441 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/inverseIndex/b.txt:0+35
2016-12-12 21:54:06,515 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 21:54:06,516 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 21:54:06,517 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 21:54:06,517 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 21:54:06,517 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 21:54:06,544 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 21:54:06,567 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 21:54:06,567 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 21:54:06,567 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 21:54:06,568 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 130; bufvoid = 104857600
2016-12-12 21:54:06,568 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26214376(104857504); length = 21/6553600
2016-12-12 21:54:06,590 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 21:54:06,599 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1000661716_0001_m_000000_0 is done. And is in the process of committing
2016-12-12 21:54:06,631 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 21:54:06,631 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local1000661716_0001_m_000000_0\' done.
2016-12-12 21:54:06,631 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1000661716_0001_m_000000_0
2016-12-12 21:54:06,631 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1000661716_0001_m_000001_0
2016-12-12 21:54:06,637 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:54:06,687 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@418b04a5
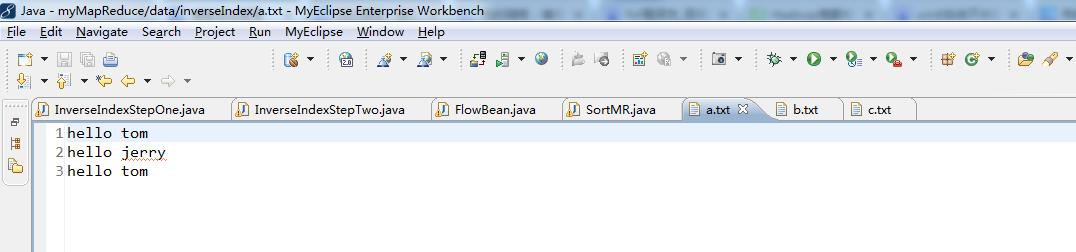
2016-12-12 21:54:06,691 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/inverseIndex/a.txt:0+33
2016-12-12 21:54:06,742 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 21:54:06,742 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 21:54:06,742 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 21:54:06,742 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 21:54:06,743 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 21:54:06,744 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 21:54:06,747 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 21:54:06,748 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 21:54:06,748 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 21:54:06,748 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 128; bufvoid = 104857600
2016-12-12 21:54:06,748 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26214376(104857504); length = 21/6553600
2016-12-12 21:54:06,756 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 21:54:06,761 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1000661716_0001_m_000001_0 is done. And is in the process of committing
2016-12-12 21:54:06,766 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 21:54:06,766 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local1000661716_0001_m_000001_0\' done.
2016-12-12 21:54:06,766 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1000661716_0001_m_000001_0
2016-12-12 21:54:06,766 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1000661716_0001_m_000002_0
2016-12-12 21:54:06,769 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:54:06,797 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@30616f6c
2016-12-12 21:54:06,800 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/inverseIndex/c.txt:0+22
2016-12-12 21:54:06,879 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 21:54:06,879 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 21:54:06,879 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 21:54:06,880 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 21:54:06,880 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 21:54:06,881 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 21:54:06,884 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 21:54:06,884 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 21:54:06,884 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 21:54:06,884 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 86; bufvoid = 104857600
2016-12-12 21:54:06,884 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600
2016-12-12 21:54:06,891 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 21:54:06,895 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1000661716_0001_m_000002_0 is done. And is in the process of committing
2016-12-12 21:54:06,898 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 21:54:06,898 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local1000661716_0001_m_000002_0\' done.
2016-12-12 21:54:06,899 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1000661716_0001_m_000002_0
2016-12-12 21:54:06,899 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2016-12-12 21:54:06,903 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2016-12-12 21:54:06,903 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1000661716_0001_r_000000_0
2016-12-12 21:54:06,917 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:54:06,948 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@43234903
2016-12-12 21:54:06,954 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@a609d4
2016-12-12 21:54:06,979 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, iosortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 21:54:06,996 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1000661716_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 21:54:07,040 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1000661716_0001_m_000000_0 decomp: 144 len: 148 to MEMORY
2016-12-12 21:54:07,052 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 144 bytes from map-output for attempt_local1000661716_0001_m_000000_0
2016-12-12 21:54:07,099 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 144, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->144
2016-12-12 21:54:07,103 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1000661716_0001_m_000001_0 decomp: 142 len: 146 to MEMORY
2016-12-12 21:54:07,105 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 142 bytes from map-output for attempt_local1000661716_0001_m_000001_0
2016-12-12 21:54:07,105 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 142, inMemoryMapOutputs.size() -> 2, commitMemory -> 144, usedMemory ->286
2016-12-12 21:54:07,110 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1000661716_0001_m_000002_0 decomp: 96 len: 100 to MEMORY
2016-12-12 21:54:07,112 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 96 bytes from map-output for attempt_local1000661716_0001_m_000002_0
2016-12-12 21:54:07,112 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 96, inMemoryMapOutputs.size() -> 3, commitMemory -> 286, usedMemory ->382
2016-12-12 21:54:07,113 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 21:54:07,114 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 3 / 3 copied.
2016-12-12 21:54:07,115 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 3 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 21:54:07,130 INFO [org.apache.hadoop.mapred.Merger] - Merging 3 sorted segments
2016-12-12 21:54:07,131 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 3 segments left of total size: 334 bytes
2016-12-12 21:54:07,133 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 3 segments, 382 bytes to disk to satisfy reduce memory limit
2016-12-12 21:54:07,133 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 382 bytes from disk
2016-12-12 21:54:07,134 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 21:54:07,134 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 21:54:07,136 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 362 bytes
2016-12-12 21:54:07,136 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 3 / 3 copied.
2016-12-12 21:54:07,144 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2016-12-12 21:54:07,163 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1000661716_0001_r_000000_0 is done. And is in the process of committing
2016-12-12 21:54:07,166 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 3 / 3 copied.
2016-12-12 21:54:07,166 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1000661716_0001_r_000000_0 is allowed to commit now
2016-12-12 21:54:07,172 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task \'attempt_local1000661716_0001_r_000000_0\' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/InverseIndexStepOne/_temporary/0/task_local1000661716_0001_r_000000
2016-12-12 21:54:07,173 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 21:54:07,173 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local1000661716_0001_r_000000_0\' done.
2016-12-12 21:54:07,174 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1000661716_0001_r_000000_0
2016-12-12 21:54:07,174 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2016-12-12 21:54:07,189 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1000661716_0001 running in uber mode : false
2016-12-12 21:54:07,191 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2016-12-12 21:54:07,193 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1000661716_0001 completed successfully
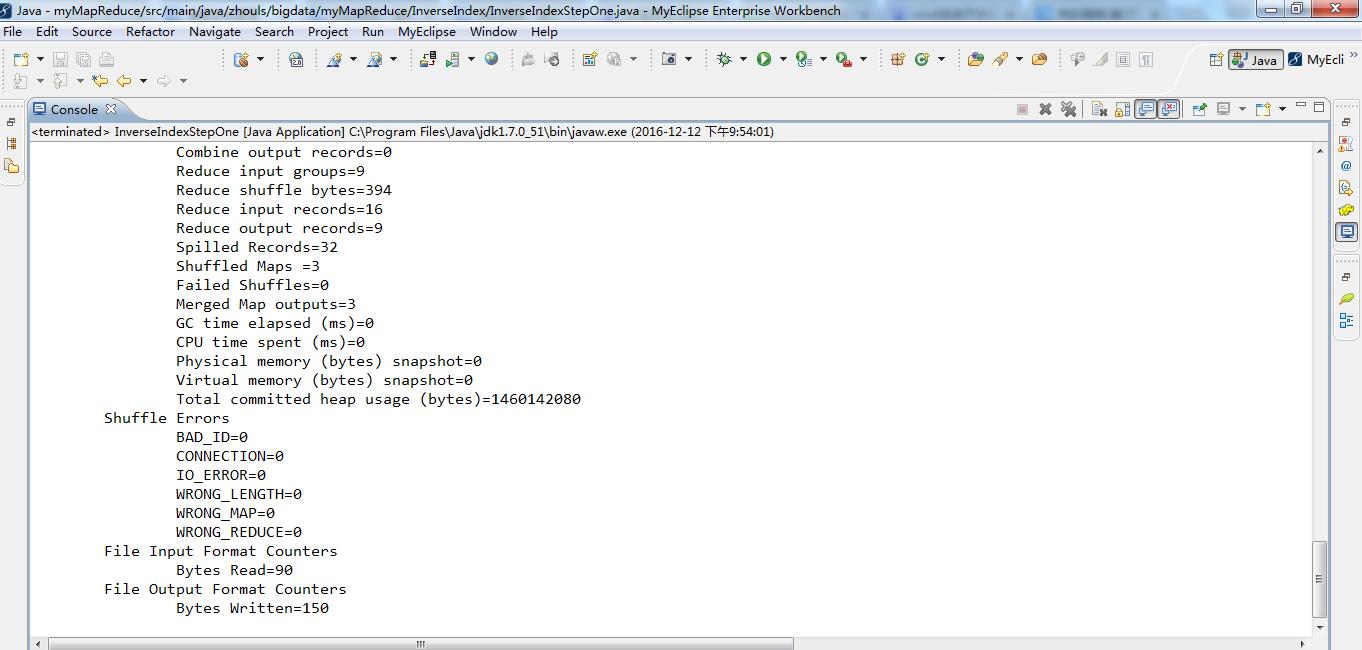
2016-12-12 21:54:07,223 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 33
File System Counters
FILE: Number of bytes read=5146
FILE: Number of bytes written=777798
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=8
Map output records=16
Map output bytes=344
Map output materialized bytes=394
Input split bytes=396
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=394
Reduce input records=16
Reduce output records=9
Spilled Records=32
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=1460142080
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=90
File Output Format Counters
Bytes Written=150

2016-12-12 21:55:03,523 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-12 21:55:05,038 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-12 21:55:05,044 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-12 21:55:05,350 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2016-12-12 21:55:05,428 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1
2016-12-12 21:55:05,846 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local549789154_0001
2016-12-12 21:55:06,425 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2016-12-12 21:55:06,427 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local549789154_0001
2016-12-12 21:55:06,488 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2016-12-12 21:55:06,510 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2016-12-12 21:55:06,605 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2016-12-12 21:55:06,609 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local549789154_0001_m_000000_0
2016-12-12 21:55:06,691 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:55:06,728 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@550aaabb
2016-12-12 21:55:06,738 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/InverseIndexStepOne/part-r-00000:0+138
2016-12-12 21:55:06,821 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 21:55:06,821 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 21:55:06,821 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 21:55:06,821 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 21:55:06,821 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 21:55:06,828 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 21:55:06,851 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 21:55:06,852 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 21:55:06,852 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 21:55:06,852 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 138; bufvoid = 104857600
2016-12-12 21:55:06,852 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26214364(104857456); length = 33/6553600
2016-12-12 21:55:06,882 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 21:55:06,895 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local549789154_0001_m_000000_0 is done. And is in the process of committing
2016-12-12 21:55:06,919 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 21:55:06,920 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local549789154_0001_m_000000_0\' done.
2016-12-12 21:55:06,920 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local549789154_0001_m_000000_0
2016-12-12 21:55:06,921 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2016-12-12 21:55:06,927 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2016-12-12 21:55:06,928 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local549789154_0001_r_000000_0
2016-12-12 21:55:06,948 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 21:55:06,996 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1c50c5b8
2016-12-12 21:55:07,002 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@311e2a2d
2016-12-12 21:55:07,024 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 21:55:07,029 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local549789154_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 21:55:07,073 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local549789154_0001_m_000000_0 decomp: 158 len: 162 to MEMORY
2016-12-12 21:55:07,079 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 158 bytes from map-output for attempt_local549789154_0001_m_000000_0
2016-12-12 21:55:07,154 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 158, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->158
2016-12-12 21:55:07,156 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 21:55:07,157 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 21:55:07,158 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 21:55:07,173 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 21:55:07,173 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 150 bytes
2016-12-12 21:55:07,175 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 158 bytes to disk to satisfy reduce memory limit
2016-12-12 21:55:07,176 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 162 bytes from disk
2016-12-12 21:55:07,177 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 21:55:07,177 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 21:55:07,179 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 150 bytes
2016-12-12 21:55:07,180 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 21:55:07,188 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2016-12-12 21:55:07,202 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local549789154_0001_r_000000_0 is done. And is in the process of committing
2016-12-12 21:55:07,206 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 21:55:07,206 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local549789154_0001_r_000000_0 is allowed to commit now
2016-12-12 21:55:07,217 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task \'attempt_local549789154_0001_r_000000_0\' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/InverseIndexStepTwo/_temporary/0/task_local549789154_0001_r_000000
2016-12-12 21:55:07,219 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 21:55:07,219 INFO [org.apache.hadoop.mapred.Task] - Task \'attempt_local549789154_0001_r_000000_0\' done.
2016-12-12 21:55:07,219 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local549789154_0001_r_000000_0
2016-12-12 21:55:07,223 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2016-12-12 21:55:07,431 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local549789154_0001 running in uber mode : false
2016-12-12 21:55:07,433 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2016-12-12 21:55:07,435 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local549789154_0001 completed successfully
2016-12-12 21:55:07,453 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 33
File System Counters
FILE: Number of bytes read=1072
FILE: Number of bytes written=386015
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=9
Map output records=9
Map output bytes=138
Map output materialized bytes=162
Input split bytes=145
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=162
Reduce input records=9
Reduce output records=3
Spilled Records=18
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=466616320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=158
File Output Format Counters
Bytes Written=121

代码
package zhouls.bigdata.myMapReduce.InverseIndex;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 倒排索引步骤一job
*
*
*/
public class InverseIndexStepOne {
public static class StepOneMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿到一行数据
String line = value.toString();
//切分出各个单词
String[] fields = StringUtils.split(line, " ");
//获取这一行数据所在的文件切片
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//从文件切片中获取文件名
String fileName = inputSplit.getPath().getName();
for(String field:fields){
//封装kv输出 , k : hello-->a.txt v: 1
context.write(new Text(field+"-->"+fileName), new LongWritable(1));
}
}
}
public static class StepOneReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// <hello-->a.txt,{1,1,1....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long counter = 0;
for(LongWritable value:values){
counter += value.get();
}
context.write(key, new LongWritable(counter));
}
}
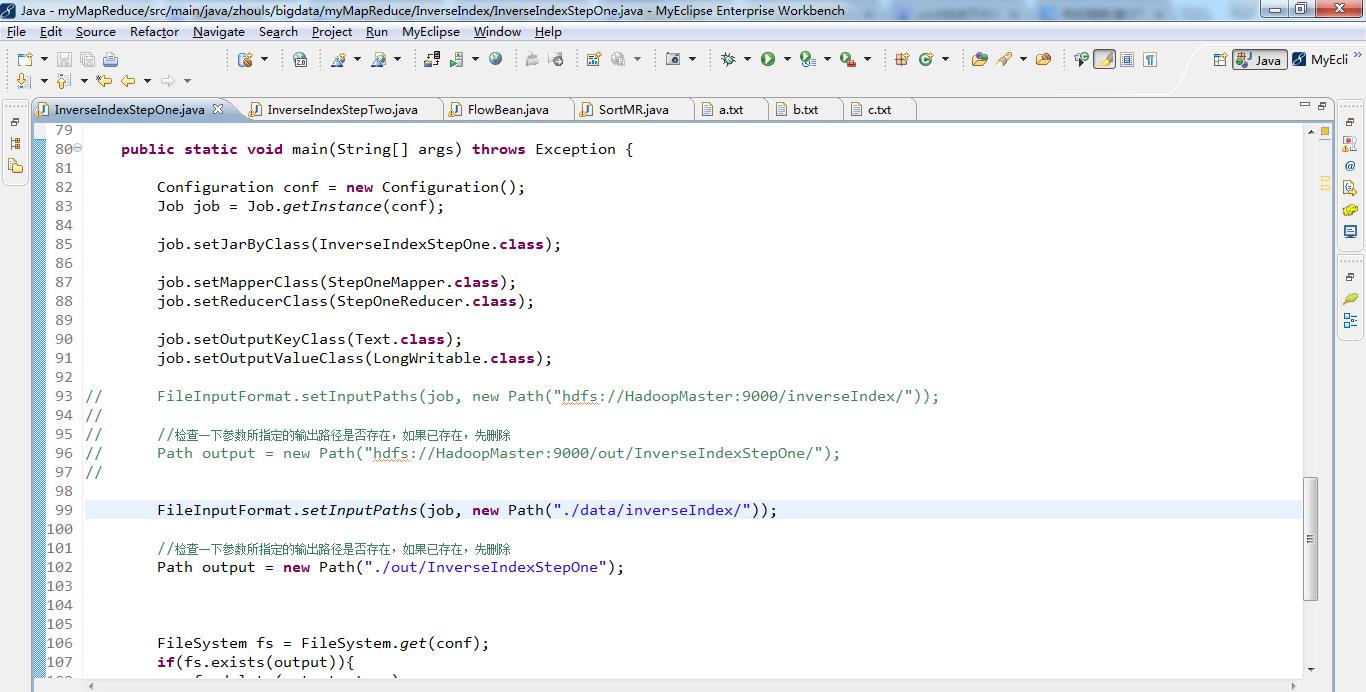
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InverseIndexStepOne.class);
job.setMapperClass(StepOneMapper.class);
job.setReducerClass(StepOneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// FileInputFormat.setInputPaths(job, new Path("hdfs://HadoopMaster:9000/inverseIndex/"));
//
// //检查一下参数所指定的输出路径是否存在,如果已存在,先删除
// Path output = new Path("hdfs://HadoopMaster:9000/out/InverseIndexStepOne/");
//
FileInputFormat.setInputPaths(job, new Path("./data/inverseIndex/"));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path("./out/InverseIndexStepOne");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
}
}
package zhouls.bigdata.myMapReduce.InverseIndex;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import zhouls.bigdata.myMapReduce.InverseIndex.InverseIndexStepOne.StepOneMapper;
import zhouls.bigdata.myMapReduce.InverseIndex.InverseIndexStepOne.StepOneReducer;
public class InverseIndexStepTwo {
public static class StepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{
//k: 行起始偏移量 v: {hello-->a.txt 3}
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\\t");
String[] wordAndfileName = StringUtils.split(fields[0], "-->");
String word = wordAndfileName[0];
String fileName = wordAndfileName[1];
long count = Long.parseLong(fields[1]);
context.write(new Text(word), new Text(fileName+"-->"+count));
//map输出的结果是这个形式 : <hello,a.txt-->3>
}
}
public static class StepTwoReducer extends Reducer<Text, Text,Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
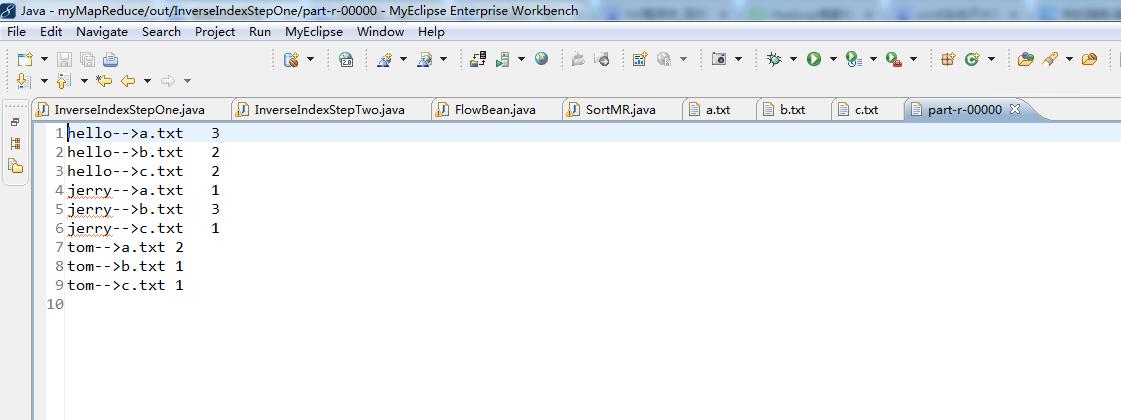
//拿到的数据 <hello,{a.txt-->3,b.txt-->2,c.txt-->1}>
String result = "";
for(Text value:values){
result += value + " ";
}
context.write(key, new Text(result));
//输出的结果就是 k: hello v: a.txt-->3 b.txt-->2 c.txt-->1
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//先构造job_one
// Job job_one = Job.getInstance(conf);
//
// job_one.setJarByClass(InverseIndexStepTwo.class);
// job_one.setMapperClass(StepOneMapper.class);
// job_one.setReducerClass(StepOneReducer.class);
//......
//构造job_two
Job job_tow = Job.getInstance(conf);
job_tow.setJarByClass(InverseIndexStepTwo.class);
job_tow.setMapperClass(StepTwoMapper.class);
job_tow.setReducerClass(StepTwoReducer.class);
job_tow.setOutputKeyClass(Text.class);
job_tow.setOutputValueClass(Text.class);
// FileInputFormat.setInputPaths(job_tow, new Path("hdfs://HadoopMaster:9000/out/InverseIndexStepOne/"));
//
// //检查一下参数所指定的输出路径是否存在,如果已存在,先删除
// Path output = new Path("hdfs://HadoopMaster:9000/out/InverseIndexStepTwo/");
FileInputFormat.setInputPaths(job_tow, new Path("./out/InverseIndexStepOne"));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path("./out/InverseIndexStepTwo");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job_tow, output);
//先提交job_one执行
// boolean one_result = job_one.waitForCompletion(true);
// if(one_result){
System.exit(job_tow.waitForCompletion(true)?0:1);
// }
}
}
以上是关于Hadoop MapReduce编程 API入门系列之倒排索引(二十四)的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop MapReduce编程 API入门系列之wordcount版本5
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2
Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
Hadoop MapReduce编程 API入门系列之mr编程快捷键活用技巧详解