redis该怎么用
Posted 李留广
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis该怎么用相关的知识,希望对你有一定的参考价值。
最近一些人在介绍方案时,经常会出现redis这个词,于是很多小伙伴百度完redis也就觉得它是一个缓存,然后项目里面把数据丢进去完事,甚至有例如将实体属性拆分塞进redis hash里面的奇怪用法等等!原因是什么呢?大家觉得redis火,使用了redis项目就是高大上的,于是不管三七二十一,项目里用上强塞一个用上!这里本人想说的是你知道redis为什么这么火么,应该怎么用么?下面带着本人拙建,简单分析一下:
一、redis性能
redis是一个基于内存hash结构的缓存型db,同mysql等传统数据库对比性能时,读操作在1k左右数据的时候相差基本上在10-100倍的差别,写入的性能差别就更大了,下面是一些测试数据
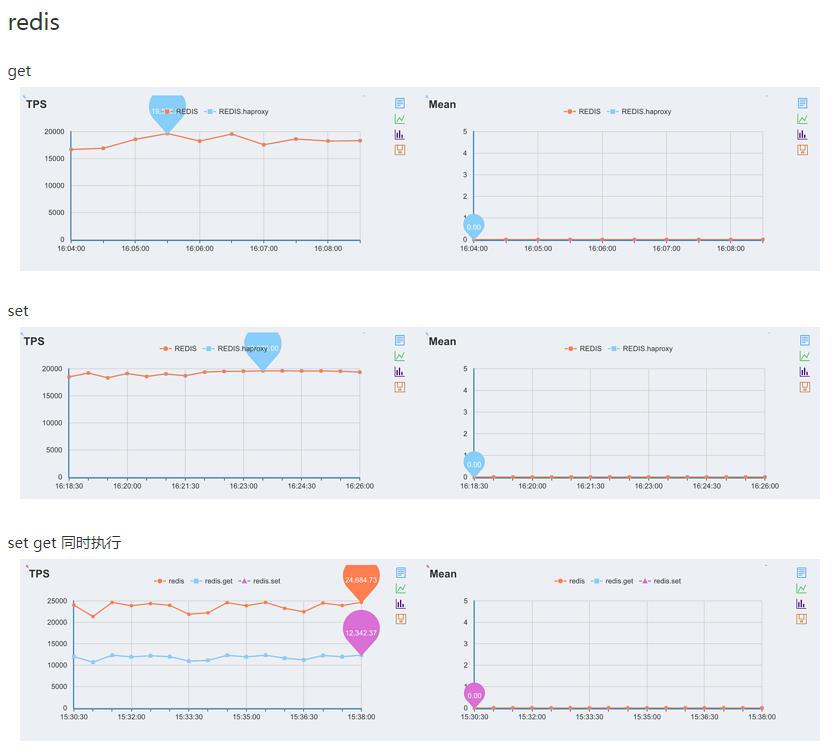
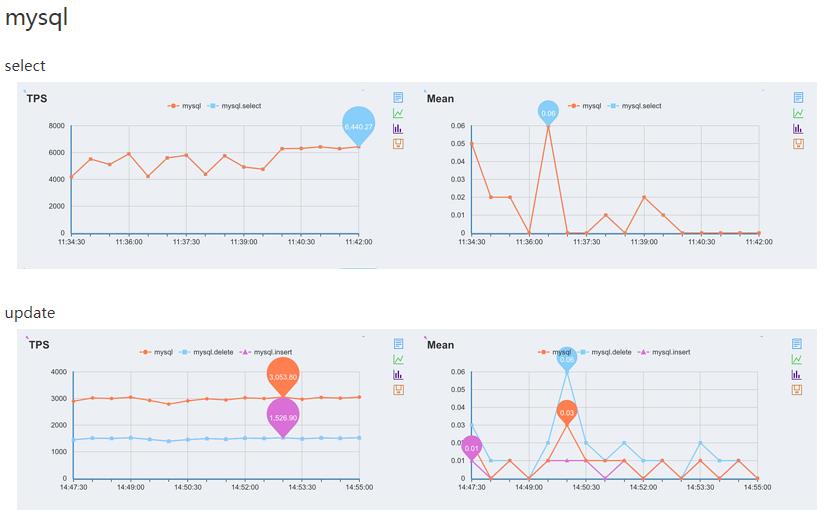
通过对redis的set、get命令测试观察,redis的读写性能在单线程下可以达到每秒2W左右;通过对mysql的select和insert、delete语句测试,mysql的读性能可达到5000每秒左右,写性能可到达3000每秒,读性能基本是写性能的2倍。而上述测试是基于redis单实例、单连接的情况,如果根据cpu核数来增加redis实例,并且使用pie和多连接,这个数据还能轻松的再上一个数量级~
二、redis缓存
上面分析了redis的性能非常高,基本上同机器配置下完全吊打传统sql,甚至nosql的mongodb等。即使这样redis也只是一个分布式缓存,或者说是分布式缓存数据库,那么redis肯定不能像传统数据一样,动不动放个几T的数据,一般都是用来放热数据或者体量小的数据,其他的数据还是使用队列通过后台服务放到sql db里面;另外根据redis的特性,建议服务器cpu核心数要留个1/4,每个实例的内存最得多出1/2;假如24核的120G的服务器,建议部署18个reids实例,每个实例5G的内存,实际使用不要超过3G的数据量~reids是缓存就继承了缓存的优缺点,性能高是优点,缺点:缓存穿透、缓存雪崩。
1.缓存穿透:缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂了。
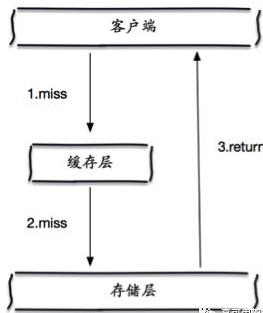
解决办法就是将从db过来的返回值进行缓存,根据实际情况重新加热,若db返回是空则缓存几分钟就可以了。
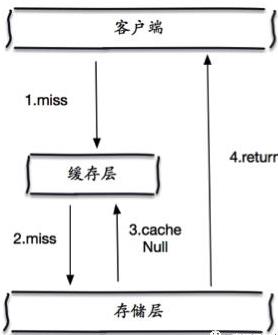
2.缓存雪崩:在我们设置缓存时采用了相同的过期时间或者缓存服务器因某些原因无法使用时,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
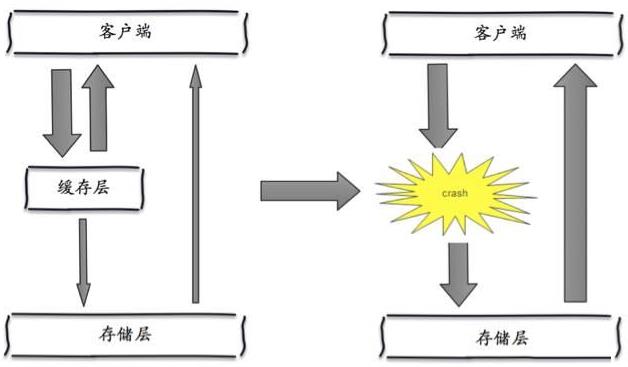
解决办法过期时间上增加一个范围的随机值,使用Redis Sentinel 和 Redis Cluster 实现高可用,另增设一个寿命更短的本机缓存来解决redis分布缓存抢修时的问题。
在发生无论是缓存穿透还是缓存雪崩,都建议使用队列来排队、拒绝大量请求涌入和分布式互斥锁来避免后端数据服务被冲击,防止已有的数据出现问题。
三、总结
redis很强大,无论是哨兵式集群还是自带的redis cluster方式集群,但是一定要对redis了解清楚才能更好的使用~
以上是关于redis该怎么用的主要内容,如果未能解决你的问题,请参考以下文章