Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)相关的知识,希望对你有一定的参考价值。
不多说,直接上代码。
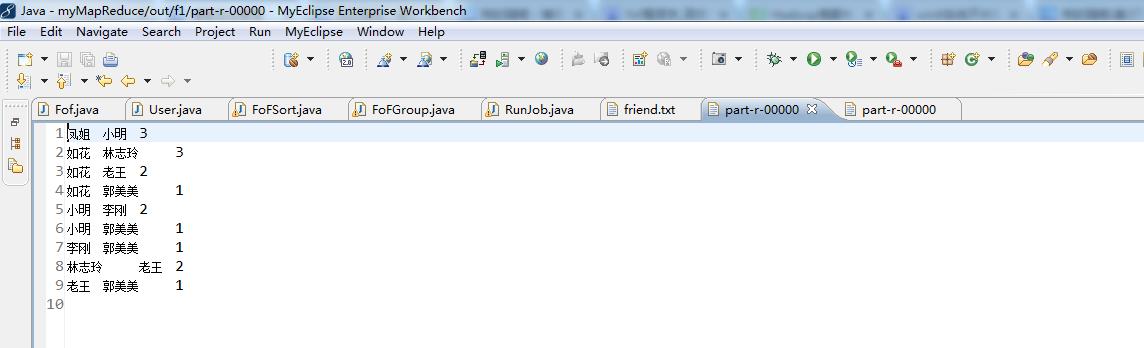
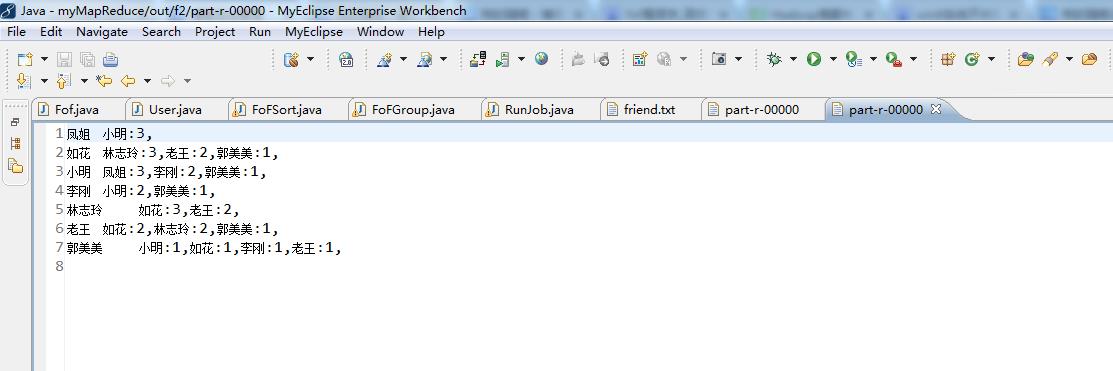
代码
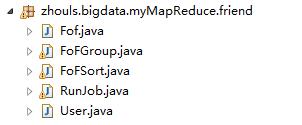
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.Text;
public class Fof extends Text{//自定义Fof,表示f1和f2关系
public Fof(){//无参构造
super();
}
public Fof(String a,String b){//有参构造
super(getFof(a, b));
}
public static String getFof(String a,String b){
int r =a.compareTo(b);
if(r<0){
return a+"\\t"+b;
}else{
return b+"\\t"+a;
}
}
}
package zhouls.bigdata.myMapReduce.friend;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
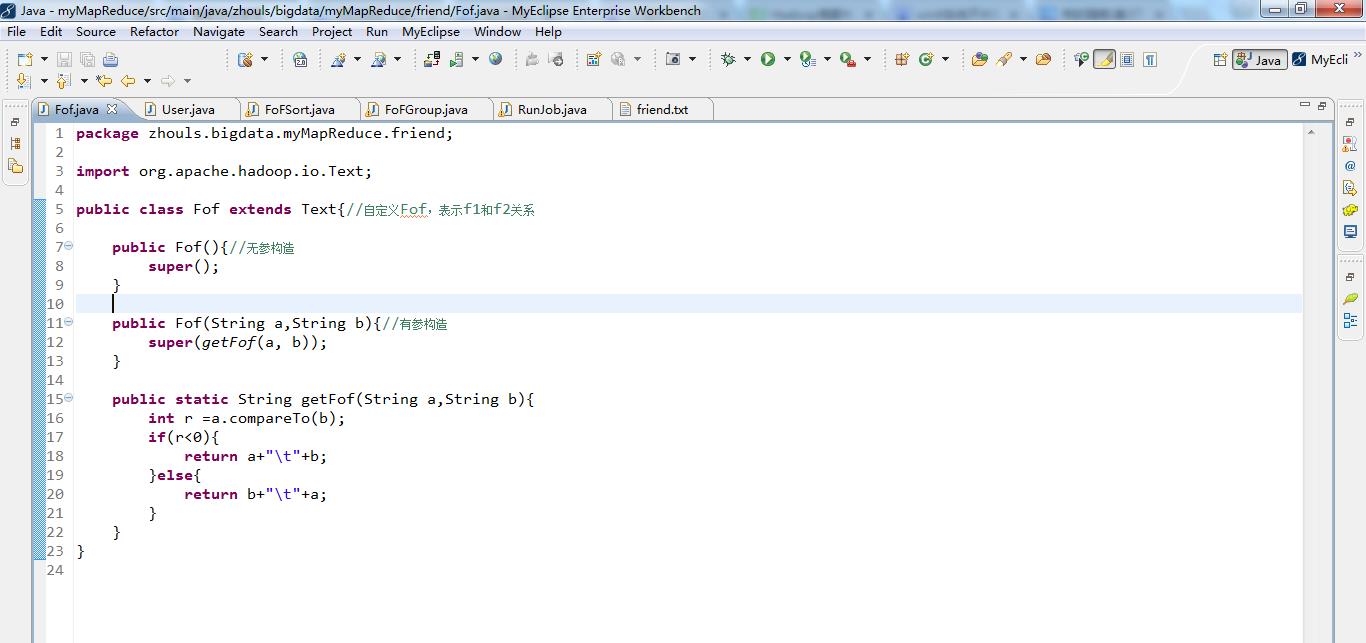
public class User implements WritableComparable<User>{
//WritableComparable,实现这个方法,要多很多
//readFields是读入,write是写出
private String uname;
private int friendsCount;
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public int getFriendsCount() {
return friendsCount;
}
public void setFriendsCount(int friendsCount) {
this.friendsCount = friendsCount;
}//这一大段的get和set,可以右键,source,产生get和set,自动生成。
public User() {//无参构造
}
public User(String uname,int friendsCount){//有参构造
this.uname=uname;
this.friendsCount=friendsCount;
}
public void write(DataOutput out) throws IOException { //序列化
out.writeUTF(uname);
out.writeInt(friendsCount);
}
public void readFields(DataInput in) throws IOException {//反序列化
this.uname=in.readUTF();
this.friendsCount=in.readInt();
}
public int compareTo(User o) {//核心
int result = this.uname.compareTo(o.getUname());
if(result==0){
return Integer.compare(this.friendsCount, o.getFriendsCount());
}
return result;
}
}
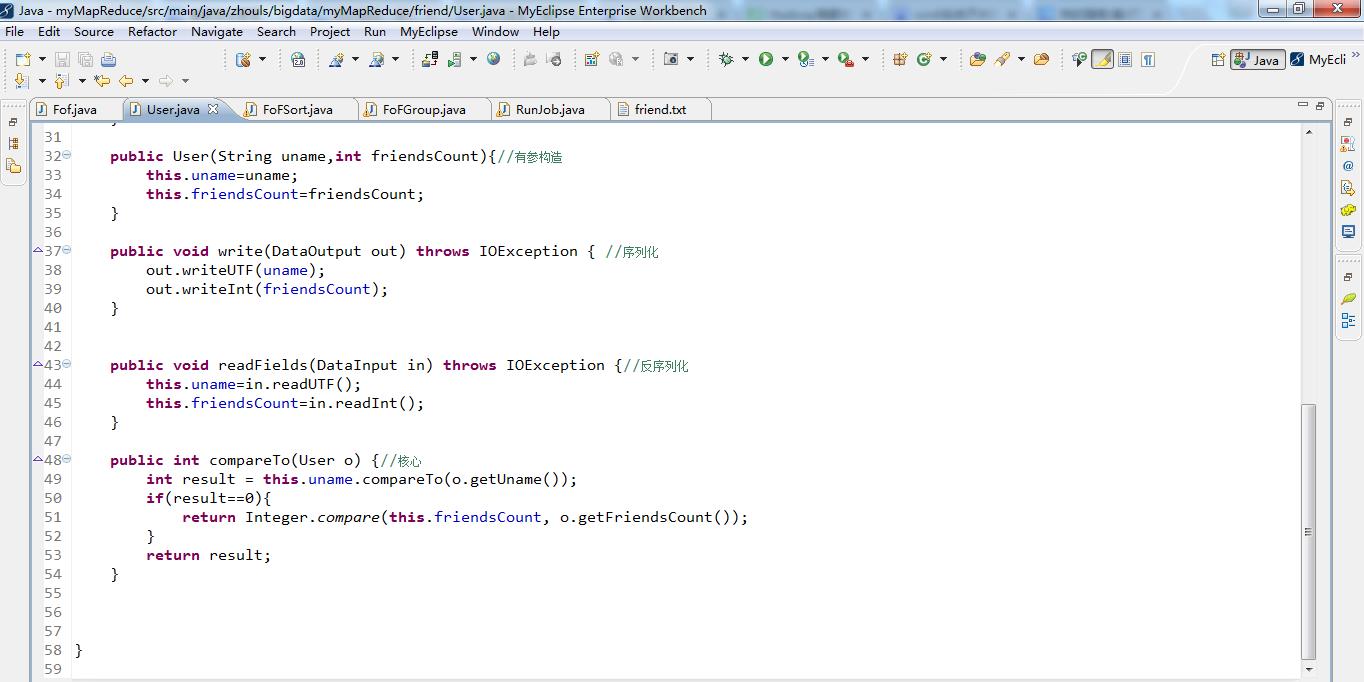
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FoFSort extends WritableComparator{
public FoFSort() {//把自定义的User,传进了
super(User.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {//排序核心
User u1 =(User) a;
User u2=(User) b;
int result =u1.getUname().compareTo(u2.getUname());
if(result==0){
return -Integer.compare(u1.getFriendsCount(), u2.getFriendsCount());
}
return result;
}
}
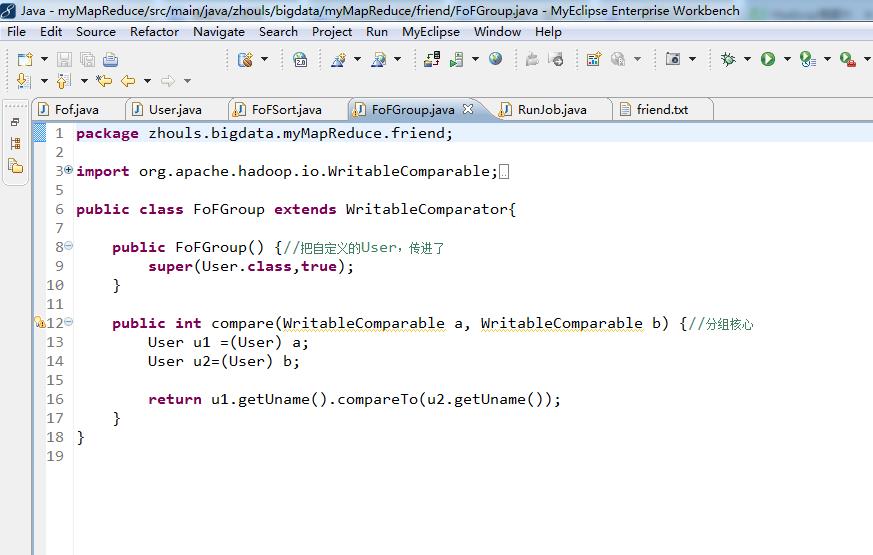
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FoFGroup extends WritableComparator{
public FoFGroup() {//把自定义的User,传进了
super(User.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {//分组核心
User u1 =(User) a;
User u2=(User) b;
return u1.getUname().compareTo(u2.getUname());
}
}
package zhouls.bigdata.myMapReduce.friend;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.StringUtils;
public class RunJob {
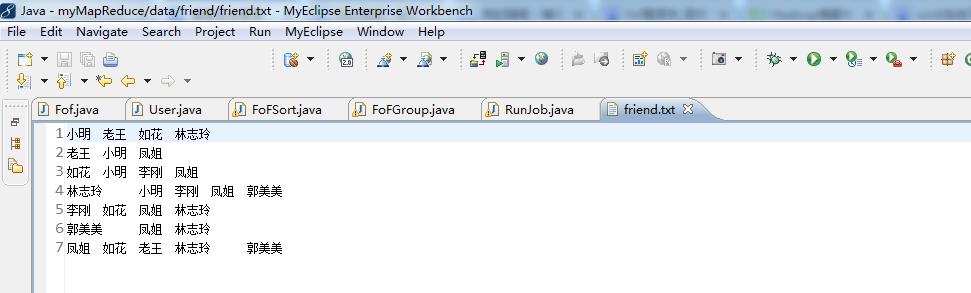
// 小明 老王 如花 林志玲
// 老王 小明 凤姐 排序在FoFSort.java
// 如花 小明 李刚 凤姐
// 林志玲 小明 李刚 凤姐 郭美美 分组在FoFGroup.java
// 李刚 如花 凤姐 林志玲
// 郭美美 凤姐 林志玲
// 凤姐 如花 老王 林志玲 郭美美
public static void main(String[] args) {
Configuration config =new Configuration();
// config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
// config.set("yarn.resourcemanager.hostname", "HadoopMaster");
// config.set("mapred.jar", "C:\\\\Users\\\\Administrator\\\\Desktop\\\\wc.jar");
// config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");//默认分隔符是制表符"\\t",这里自定义,如","
if(run1(config)){
run2(config);//设置两个run,即两个mr。
}
}
public static void run2(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("fof2");
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setSortComparatorClass(FoFSort.class);
job.setGroupingComparatorClass(FoFGroup.class);
job.setMapOutputKeyClass(User.class);
job.setMapOutputValueClass(User.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// //设置MR执行的输入文件
// FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/f1"));
//
// //该目录表示MR执行之后的结果数据所在目录,必须不能存在
// Path outputPath=new Path("hdfs://HadoopMaster:9000/out/f2");
//设置MR执行的输入文件
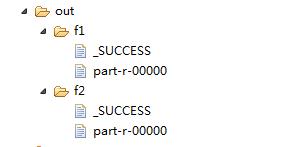
FileInputFormat.addInputPath(job, new Path("./out/f1"));
//该目录表示MR执行之后的结果数据所在目录,必须不能存在
Path outputPath=new Path("./out/f2");
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean f =job.waitForCompletion(true);
if(f){
System.out.println("job 成功执行");
}
} catch (Exception e) {
e.printStackTrace();
}
}
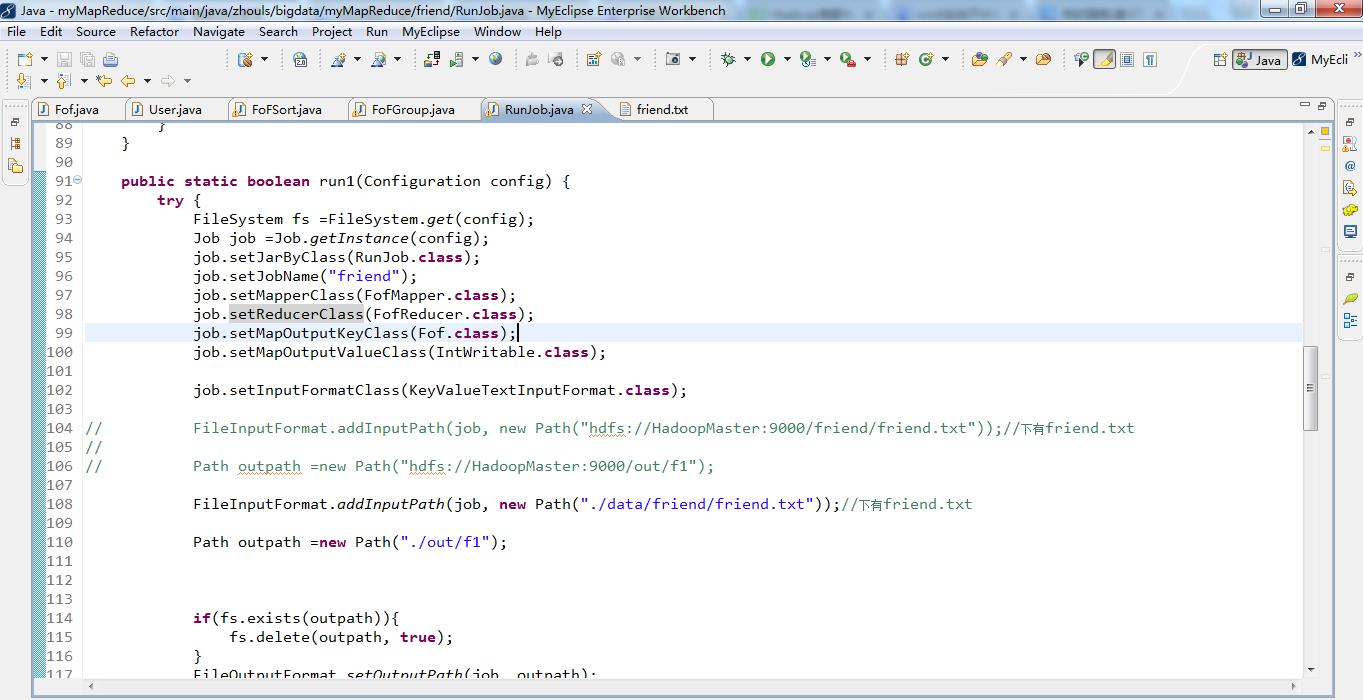
public static boolean run1(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("friend");
job.setMapperClass(FofMapper.class);
job.setReducerClass(FofReducer.class);
job.setMapOutputKeyClass(Fof.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/friend/friend.txt"));//下有friend.txt
//
// Path outpath =new Path("hdfs://HadoopMaster:9000/out/f1");
FileInputFormat.addInputPath(job, new Path("./data/friend/friend.txt"));//下有friend.txt
Path outpath =new Path("./out/f1");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class FofMapper extends Mapper<Text, Text, Fof, IntWritable>{
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String user =key.toString();
String[] friends =StringUtils.split(value.toString(), \'\\t\');
for (int i = 0; i < friends.length; i++) {
String f1 = friends[i];
Fof ofof =new Fof(user, f1);
context.write(ofof, new IntWritable(0));
for (int j = i+1; j < friends.length; j++) {
String f2 = friends[j];
Fof fof =new Fof(f1, f2);
context.write(fof, new IntWritable(1));
}
}
}
}
static class FofReducer extends Reducer<Fof, IntWritable, Fof, IntWritable>{
protected void reduce(Fof arg0, Iterable<IntWritable> arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
boolean f =true;
for(IntWritable i: arg1){
if(i.get()==0){
f=false;
break;
}else{
sum=sum+i.get();
}
}
if(f){
arg2.write(arg0, new IntWritable(sum));
}
}
}
static class SortMapper extends Mapper<Text, Text, User, User>{
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String[] args=StringUtils.split(value.toString(),\'\\t\');
String other=args[0];
int friendsCount =Integer.parseInt(args[1]);
context.write(new User(key.toString(),friendsCount), new User(other,friendsCount));
context.write(new User(other,friendsCount), new User(key.toString(),friendsCount));
}
}
static class SortReducer extends Reducer<User, User, Text, Text>{
protected void reduce(User arg0, Iterable<User> arg1,
Context arg2)
throws IOException, InterruptedException {
String user =arg0.getUname();
StringBuffer sb =new StringBuffer();
for(User u: arg1 ){
sb.append(u.getUname()+":"+u.getFriendsCount());
sb.append(",");
}
arg2.write(new Text(user), new Text(sb.toString()));
}
}
以上是关于Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)的主要内容,如果未能解决你的问题,请参考以下文章