Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)相关的知识,希望对你有一定的参考价值。
不多说,直接上代码。
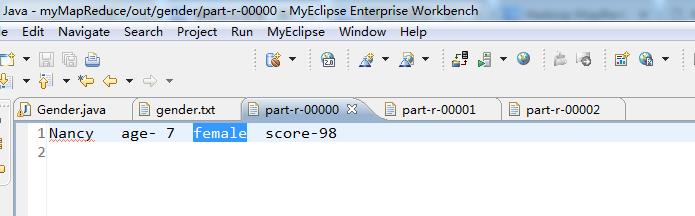
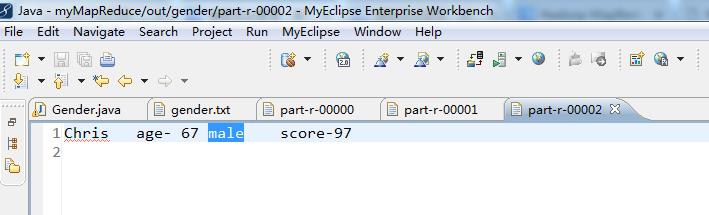
统计出每个年龄段的 男、女 学生的最高分

这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据。

代码
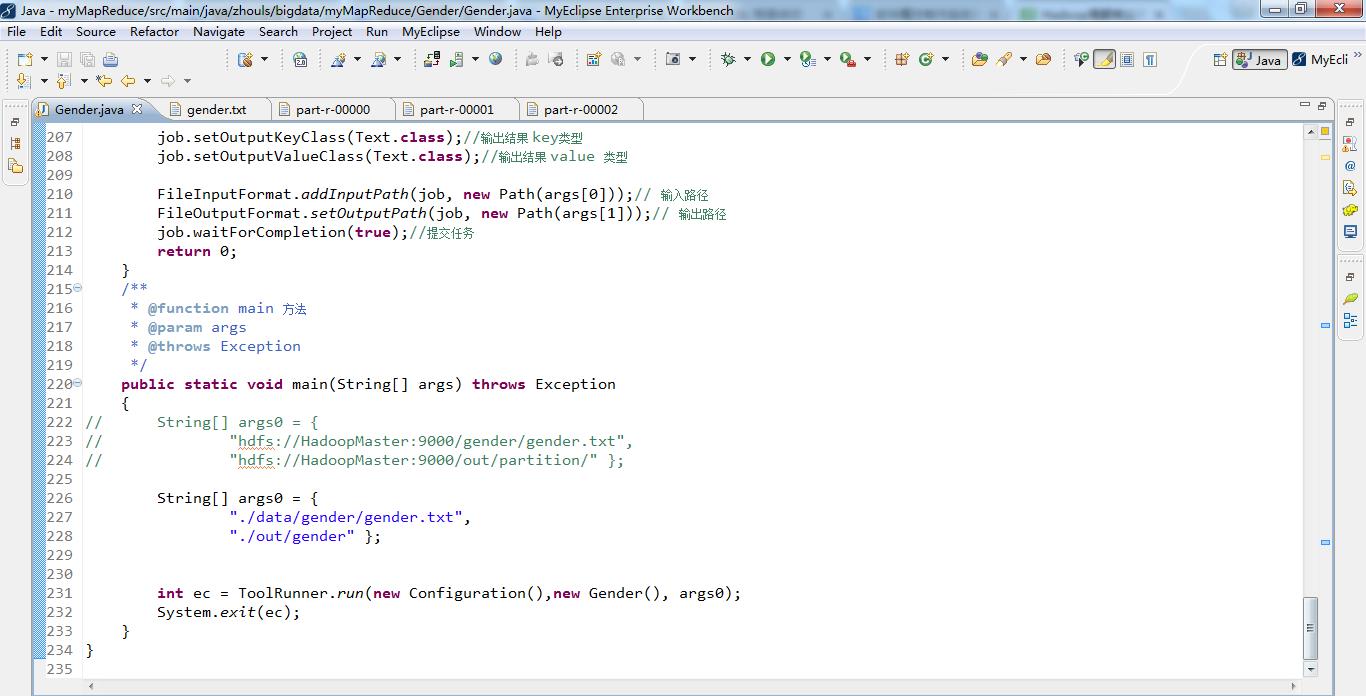
package zhouls.bigdata.myMapReduce.Gender; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * * @function 统计不同年龄段内 男、女最高分数 * * */ /* Alice<tab>23<tab>female<tab>45 Bob<tab>34<tab>male<tab>89 Chris<tab>67<tab>male<tab>97 Kristine<tab>38<tab>female<tab>53 Connor<tab>25<tab>male<tab>27 Daniel<tab>78<tab>male<tab>95 James<tab>34<tab>male<tab>79 Alex<tab>52<tab>male<tab>69 Nancy<tab>7<tab>female<tab>98 Adam<tab>9<tab>male<tab>37 Jacob<tab>7<tab>male<tab>23 Mary<tab>6<tab>female<tab>93 Clara<tab>87<tab>female<tab>72 Monica<tab>56<tab>female<tab>92 */ public class Gender extends Configured implements Tool { /* * * @function Mapper 解析输入数据,然后按需求输出 * @input key=行偏移量 value=学生数据 * @output key=gender value=name+age+score * */ public static class PCMapper extends Mapper<Object, Text, Text, Text> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException {//拿Alice<tab>23<tab>female<tab>45 String[] tokens = value.toString().split("<tab>");//使用分隔符<tab>,将数据解析为数组 tokens //得到Alice 23 female 45 //即tokens[0] tokens[1] tokens[2] tokens[3] String gender = tokens[2].toString();//性别 String nameAgeScore = tokens[0] + "\\t" + tokens[1] + "\\t"+ tokens[3]; //输出 key=gender value=name+age+score //输出 key=female value=Alice +23+45 context.write(new Text(gender), new Text(nameAgeScore));//将 (female , Alice+ 23+ 45) 写入到context中 } } public static class MyHashPartitioner extends Partitioner<Text, Text> { /** Use {@link Object#hashCode()} to partition. */ @Override public int getPartition(Text key, Text value,int numReduceTasks) { return (key.hashCode()) % numReduceTasks; } } /** * * @function Partitioner 根据 age 选择 reduce 分区 * */ public static class PCPartitioner extends Partitioner<Text, Text> { @Override public int getPartition(Text key, Text value, int numReduceTasks) { // TODO Auto-generated method stub String[] nameAgeScore = value.toString().split("\\t"); String age = nameAgeScore[1];//学生年龄 int ageInt = Integer.parseInt(age);//按年龄段分区 // 默认指定分区 0 if (numReduceTasks == 0) return 0; //年龄小于等于20,指定分区0 if (ageInt <= 20) { return 0; } // 年龄大于20,小于等于50,指定分区1 if (ageInt > 20 && ageInt <= 50) { return 1 % numReduceTasks; } // 剩余年龄,指定分区2 else return 2 % numReduceTasks; } } /** * * @function 定义Combiner 合并 Mapper 输出结果 * */ public static class PCCombiner extends Reducer<Text, Text, Text, Text> { private Text text = new Text(); public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { int maxScore = Integer.MIN_VALUE; String name = " "; String age = " "; int score = 0; for (Text val : values) { String[] valTokens = val.toString().split("\\\\t"); score = Integer.parseInt(valTokens[2]); if (score > maxScore) { name = valTokens[0]; age = valTokens[1]; maxScore = score; } } text.set(name + "\\t" + age + "\\t" + maxScore); context.write(key, text); } } /* * * @function Reducer 统计出 不同年龄段、不同性别 的最高分 * input key=gender value=name+age+score * output key=name value=age+gender+score * */ static class PCReducer extends Reducer<Text, Text, Text, Text> { @Override public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { int maxScore = Integer.MIN_VALUE; String name = " "; String age = " "; String gender = " "; int score = 0; // 根据key,迭代 values 集合,求出最高分 for (Text val : values) { String[] valTokens = val.toString().split("\\\\t"); score = Integer.parseInt(valTokens[2]); if (score > maxScore) { name = valTokens[0]; age = valTokens[1]; gender = key.toString(); maxScore = score; } } context.write(new Text(name), new Text("age- " + age + "\\t" + gender + "\\tscore-" + maxScore)); } } /** * @function 任务驱动方法 * @param args * @return * @throws Exception */ @Override public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration();//读取配置文件 Path mypath = new Path(args[1]); FileSystem hdfs = mypath.getFileSystem(conf); if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } @SuppressWarnings("deprecation") Job job = new Job(conf, "gender");//新建一个任务 job.setJarByClass(Gender.class);//主类 job.setMapperClass(PCMapper.class);//Mapper job.setReducerClass(PCReducer.class);//Reducer job.setPartitionerClass(MyHashPartitioner.class); //job.setPartitionerClass(PCPartitioner.class);//设置Partitioner类 job.setNumReduceTasks(3);// reduce个数设置为3 job.setMapOutputKeyClass(Text.class);//map 输出key类型 job.setMapOutputValueClass(Text.class);//map 输出value类型 job.setCombinerClass(PCCombiner.class);//设置Combiner类 job.setOutputKeyClass(Text.class);//输出结果 key类型 job.setOutputValueClass(Text.class);//输出结果 value 类型 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 job.waitForCompletion(true);//提交任务 return 0; } /** * @function main 方法 * @param args * @throws Exception */ public static void main(String[] args) throws Exception { // String[] args0 = { // "hdfs://HadoopMaster:9000/gender/gender.txt", // "hdfs://HadoopMaster:9000/out/partition/" }; String[] args0 = { "./data/gender/gender.txt", "./out/gender" }; int ec = ToolRunner.run(new Configuration(),new Gender(), args0); System.exit(ec); } }
或者
代码
package com.dajiangtai.hadoop.junior; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * * @function 统计不同年龄段内 男、女最高分数 * @author zhouls * */ /* Alice<tab>23<tab>female<tab>45 Bob<tab>34<tab>male<tab>89 Chris<tab>67<tab>male<tab>97 Kristine<tab>38<tab>female<tab>53 Connor<tab>25<tab>male<tab>27 Daniel<tab>78<tab>male<tab>95 James<tab>34<tab>male<tab>79 Alex<tab>52<tab>male<tab>69 Nancy<tab>7<tab>female<tab>98 Adam<tab>9<tab>male<tab>37 Jacob<tab>7<tab>male<tab>23 Mary<tab>6<tab>female<tab>93 Clara<tab>87<tab>female<tab>72 Monica<tab>56<tab>female<tab>92 */ public class Gender extends Configured implements Tool { /* * * @function Mapper 解析输入数据,然后按需求输出 * @input key=行偏移量 value=学生数据 * @output key=gender value=name+age+score * */ public static class PCMapper extends Mapper<Object, Text, Text, Text> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException {//拿Alice<tab>23<tab>female<tab>45 String[] tokens = value.toString().split("<tab>");//使用分隔符<tab>,将数据解析为数组 tokens //得到Alice 23 female 45 //即tokens[0] tokens[1] tokens[2] tokens[3] String gender = tokens[2].toString();//性别 String nameAgeScore = tokens[0] + "\\t" + tokens[1] + "\\t"+ tokens[3]; //输出 key=gender value=name+age+score //输出 key=female value=Alice +23+45 context.write(new Text(gender), new Text(nameAgeScore));//将 (female , Alice+ 23+ 45) 写入到context中 } } public static class MyHashPartitioner extends Partitioner<Text, Text> { /** Use {@link Object#hashCode()} to partition. */ @Override public int getPartition(Text key, Text value,int numReduceTasks) { return (key.hashCode()) % numReduceTasks; } } /** * * @function Partitioner 根据 age 选择 reduce 分区 * */ public static class PCPartitioner extends Partitioner<Text, Text> { @Override public int getPartition(Text key, Text value, int numReduceTasks) { // TODO Auto-generated method stub String[] nameAgeScore = value.toString().split("\\t"); String age = nameAgeScore[1];//学生年龄 int ageInt = Integer.parseInt(age);//按年龄段分区 // 默认指定分区 0 if (numReduceTasks == 0) return 0; //年龄小于等于20,指定分区0 if (ageInt <= 20) { return 0; } // 年龄大于20,小于等于50,指定分区1 if (ageInt > 20 && ageInt <= 50) { return 1 % numReduceTasks; } // 剩余年龄,指定分区2 else return 2 % numReduceTasks; } } /** * * @function 定义Combiner 合并 Mapper 输出结果 * */ public static class PCCombiner extends Reducer<Text, Text, Text, Text> { private Text text = new Text(); public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { int maxScore = Integer.MIN_VALUE; String name = " "; String age = " "; int score = 0; for (Text val : values) { String[] valTokens = val.toString().split("\\\\t"); score = Integer.parseInt(valTokens[2]); if (score > maxScore) { name = valTokens[0]; age = valTokens[1]; maxScore = score; } } text.set(name + "\\t" + age + "\\t" + maxScore); context.write(key, text); } } /* * * @function Reducer 统计出 不同年龄段、不同性别 的最高分 * input key=gender value=name+age+score * output key=name value=age+gender+score * */ static class PCReducer extends Reducer<Text, Text, Text, Text> { @Override public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { int maxScore = Integer.MIN_VALUE; String name = " "; String age = " "; String gender = " "; int score = 0; // 根据key,迭代 values 集合,求出最高分 for (Text val : values) { String[] valTokens = val.toString().split("\\\\t"); score = Integer.parseInt(valTokens[2]); if (score > maxScore) { name = valTokens[0]; age = valTokens[1]; gender = key.toString(); maxScore = score; } } context.write(new Text(name), new Text("age- " + age + "\\t" + gender + "\\tscore-" + maxScore)); } } /** * @function 任务驱动方法 * @param args * @return * @throws Exception */ @Override public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration();//读取配置文件 Path mypath = new Path(args[1]); FileSystem hdfs = mypath.getFileSystem(conf); if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } @SuppressWarnings("deprecation") Job job = new Job(conf, "gender");//新建一个任务 job.setJarByClass(Gender.class);//主类 job.setMapperClass(PCMapper.class);//Mapper job.setReducerClass(PCReducer.class);//Reducer job.setPartitionerClass(MyHashPartitioner.class); //job.setPartitionerClass(PCPartitioner.class);//设置Partitioner类 job.setNumReduceTasks(3);// reduce个数设置为3 job.setMapOutputKeyClass(Text.class);//map 输出key类型 job.setMapOutputValueClass(Text.class);//map 输出value类型 job.setCombinerClass(PCCombiner.class);//设置Combiner类 job.setOutputKeyClass(Text.class);//输出结果 key类型 job.setOutputValueClass(Text.class);//输出结果 value 类型 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 job.waitForCompletion(true);//提交任务 return 0; } /** * @function main 方法 * @param args * @throws Exception */ public static void main(String[] args) throws Exception { String[] args0 = { "hdfs://master:9000/middle/partition/gender.txt", "hdfs://master:9000/middle/partition/out/" }; int ec = ToolRunner.run(new Configuration(),new Gender(), args0); System.exit(ec); } }
以上是关于Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop MapReduce编程 API入门系列之wordcount版本5
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2
Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
Hadoop MapReduce编程 API入门系列之mr编程快捷键活用技巧详解