gdbt与adboost(或者说boosting)区别
Posted 去做点事情
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gdbt与adboost(或者说boosting)区别相关的知识,希望对你有一定的参考价值。
boosting 是一种将弱分类器转化为强分类器的方法统称,而adaboost是其中的一种,或者说AdaBoost是Boosting算法框架中的一种实现

https://www.zhihu.com/question/37683881
gdbt(Gradient Boosting Decision Tree,梯度提升决策树)
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:
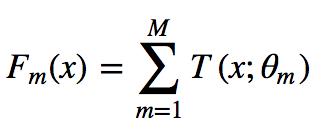
模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)。弱分类器的损失函数
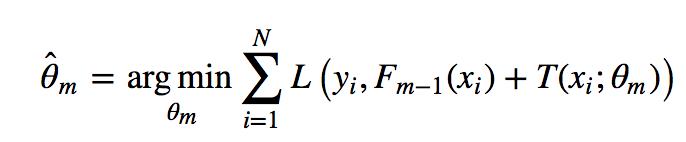
看公式就知道其实每次学习的是T,即当前的那个分类器
Fm−1(x)为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
-
- 但是其实我们真正关注的,1.是希望损失函数能够不断的减小,2.是希望损失函数能够尽可能快的减小。所以如何尽可能快的减小呢?
-
- 让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心了。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
-
- 这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
首先明确gbdt也属于boosting,但他和adboost不同,他不是每次训练部门数据,而是整个数据集(如上图所示)。那他为什么又属于boosting呢?个人认为:1.gdbt也是串行的 2.每次迭代需要上次的返回结果,这是这里的返回结果和adboost不同。(之前认为总分类器是将每轮训练得到的弱分类器加权求和得到的,但bagging是vote或者求平均。但是后来发现,bagging里面vote也可以通过软vote获得加权和)
https://www.cnblogs.com/ModifyRong/p/7744987.html
区别:1.adboost是优化错分数据权重,gdbt是通过残差优化每一轮的分类器
2.adboost是指数损失函数,gdbt是平方损失函数
以上是关于gdbt与adboost(或者说boosting)区别的主要内容,如果未能解决你的问题,请参考以下文章