hadoop集群自带WordCount例子
Posted SUIB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop集群自带WordCount例子相关的知识,希望对你有一定的参考价值。
默认当前位置是hadoop安装包位置
jar包:share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar
一 前置准备
$ cd share/hadoop/mapreduce/
因为这个需要hdfs中的文件,需要掌握基本的hdfs命令
HDFS基本的文件命令: 格式: hadoop fs -cmd <args> 其中,cmd代表具体的文件命令,与unix对应的命令相同,args表示可变的参数。 如, hadoop fs ——获取完整的可用命令列表 hadoop fs -ls / ——返回根目录下/user的信息 hadoop fs -lsr / ——返回根目录下所有文件和子目录 hadoop fs -put example.txt . ——把本地文件复制到HDFS的默认目录中 hadoop fs -put example.txt /user/hadoop hadoop fs -get example.txt . ——把HDFS中的文件复制到本地 hadoop fs -cat ——在命令行中显示文件内容 hadoop fs -rm ——删除文件 hadoop fs -rmr ——删除目录
hdfs当前默认位置是在user/当前用户 文件夹 ,有些版本可能没有初始化这个文件夹 需要自己创建
$hadoop fs -mkdir /uesr $hadoop fs -mkdir /uesr/xingluou
本地创建一个文本test用来比较,随便写几个单词
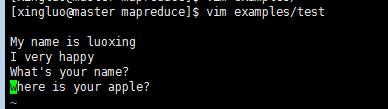
将这个本地文件复制到hdfs中
$ hadoop fs -put examples/test
二 运行自带的WordCount
$ hadoop jar hadoop-mapreduce-examples-3.1.0.jar wordcount test out
程序运行完后 查看当前hadoop文件

发现除了我们自己put进来的test还多生成了一个out目录

查看part-r-00000这个文件
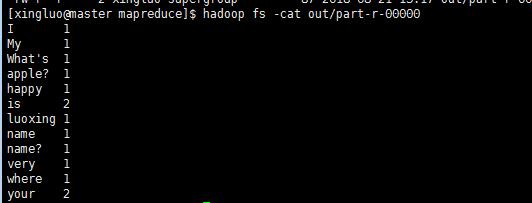
发现就是刚刚文本统计的结果
三.遇到的问题以及解决方案
1.运行自带的例子 提示找不到或无法加载主类org.apache.hadoop.mapreduce.v2.app.MRAppMaster
解决方案:没有classpath导致的 添加classpath即可
a)hadoop classpath 复制下来打印内容

b)编辑 ${HADOOP_HOME}/etc/hadoop/yarn-site.xml 添加yarn.application.classpath,将刚刚查看到的classpath添加即可
以上是关于hadoop集群自带WordCount例子的主要内容,如果未能解决你的问题,请参考以下文章