MongoDB
Posted zdqc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB相关的知识,希望对你有一定的参考价值。
第1章 MongoDB的简介及部署
1.1 数据库管理系统
1、什么是数据?
数据是指对客观时间进行记录并可以鉴别的符号,是对客观事物的性质,状态以及相互关系等进行记载的物理符号或这些物理符号的组合。它是可识别的、抽象的符号。
2、什么是数据库管理系统?
数据库管理系统 是一种针对对象数据库,为管理数据库而设计的大型电脑软件管理系统。具有代表性的数据管理系统有:Oracle、Microsoft SQL Server、Access、mysql及PostgreSQL等。通常数据库管理员会使用数据库管理系统来创建数据库系统。 现代DBMS使用不同的数据库模型追踪实体、属性和关系。在个人电脑、大型计算机和主机上应用最广泛的数据库管理系统是关系型DBMS。在关系型数据模型中,用二维表格表示数据库中的数据。这些表格称为关系。
3、常见数据库管理系统都有哪些?
开放源代码数据库系统
² Apache Derby-Apache软件基金会的纯Java数据库管理系统
² Berkeley DB加州大学Berkeley分校研究成果
² eXist简单的XML开放源代码数据库
² 火鸟
² HSQL
² Ingres
² LevelDB-Google所研发的键/值对数据库编程库
² mSQL
² MySQL网络上十分流行的数据库服务器,若结合Linux系统、php脚本技术和ApacheWeb服务器使用,则被称为LAMP。
² PostgreSQL
² SQLite C库,支持完全的SQL标准数据库,基于命令行SQLite下载
² Xindice简单的XML数据库,由Apache软件基金会开发
商业数据库系统
² 4th Dimension或者叫4D,是一套从Mac OS发展出来的数据库系统。现在亦有閞发视窗版。
² Adabas Software AG(德国)开发的的数据库参看这里
² askSam,结合了数据库和文本编辑,具有很多革新特性
² Caché,适用于企业内部系统应用
² Conzept16
² c-tree Plus FairCom公司的ISAM和关系数据库。参看http://www.faircom.com. C语言编写。
² DB1 IBM产品
² DB2 IBM产品,当前版本10.5(截至2013年11月1日)。
² dBase在DOS时代十分重要的数据库,Windows版本是Visual dBase
² FileMaker由Claris演化而来,一个界面非常友好的关系型数据库,能够同时在Mac OS和Windows上使用,最新版本12.0
² FoxBase被微软收购,继续开发出微软FoxPro,2.6版之前有DOS和Windows版。
² Google Fusion Tables
² Gupta SQLBase,当前版本9.0
² HyperFileSQL
² IDMS
² IMS
² Informix,当前版本10.0(Cheetah)
² InterBase
² MaxDB参看SAP DB
² Microsoft Access,微软公司Office组件之一,当前版本Access 2016(另外还有6.0、97、2000、XP/2002、2003、2007、2010、2013),从微软公司兼并的一家公司的产品发展而来。
² Microsoft Visual FoxPro,当前版本9.0
² MS SQL-Server,当前版本2014 SP1
² Sybase,早期版本被微软购买开发出SQL-Server。
² Oracle,当前版本12c,最受欢迎的商业数据库
² Paradox Borland开发后转手Corel(WordPerfect Office)继续开发
² PrimeBase
² RRDtool,Round Robin Database
² SAP DB由SAP开发,后由MySQL继续开发和维护现属于MaxDB。
² Tamino XML数据库k,基于Adabas的版本由Software AG开发,参看[1]
² Tdbengine
² Teradata功能非常强大,适用于非常海量数据,通常用来从事数据仓库。
² Visual dBase,最终版本5.0,已退出市场。
4、数据库管理系统使用情况世界排名
https://db-engines.com/en/ranking
1.2 NoSQL简介
1.2.1 NoSQL是什么?
?NoSQL=Not Only SQL
?1998年Carlo Strozzi首次提出(不提供SQL功能的关系型数据库)
?2009年Eric Evans再次提出NoSQL概念
?NoSQL、Relational Database相铺相成
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1.2.2 NoSQL 数据库分类
|
类型 |
部分代表 |
特点 |
|
列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
|
文档存储 |
MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 |
|
key-value存储 |
Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
|
对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
|
xml数据库 |
Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
1.2.3 NoSQL的优点/缺点
优点:
² 高可扩展性
² 分布式计算
² 低成本
² 架构的灵活性,半结构化数据
² 没有复杂的关系
缺点:
² 没有标准化
² 有限的查询功能(到目前为止)
² 最终一致是不直观的程序
1.3 传统NoSQL与RDBMS特性对比
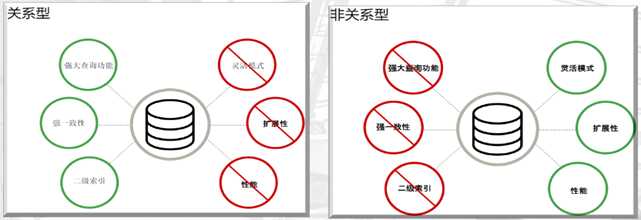
1.3.1 RDBMS
² 高度组织化结构化数据
² 结构化查询语言(SQL) (SQL)
² 数据和关系都存储在单独的表中。
² 数据操纵语言,数据定义语言
² 严格的一致性
² 基础事务
1.3.2 NoSQL
² 代表着不仅仅是SQL
² 没有声明性查询语言
² 没有预定义的模式
² 键值对存储,列存储,文档存储,图形数据库
² 最终一致性,而非ACID属性
² 非结构化和不可预知的数据
² CAP定理
² 高性能,高可用性和可伸缩性
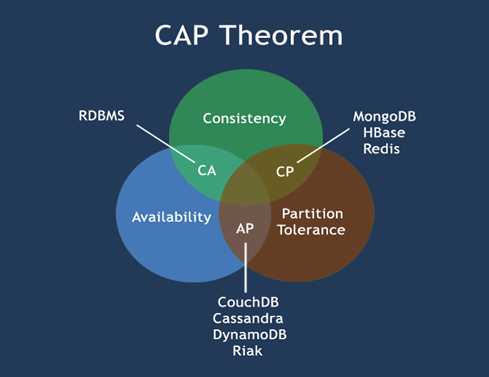
1.3.3 CPA定理
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer‘s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
² 一致性(Consistency) (所有节点在同一时间具有相同的数据)
² 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
² 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
² CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
² CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
² AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
1.4 MongoDB介绍
1、什么是MongoDB ?
² MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
² 在高负载的情况下,添加更多的节点,可以保证服务器性能。
² MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
² MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
2、主要特点
² MongoDB的提供了一个面向文档存储,操作起来比较简单和容易。
² 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
² 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
² 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
² Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
² MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
² Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
² Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
² Map函数和Reduce函数是使用javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
² GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
² MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
² MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
² MongoDB安装简单。
3、MongoDB的哲学
4、关系型与非关系型模型

5、MongoDB与RDBMS的区别
MongoDB与RDBMS最大的区别在于:没有固定的行列组织数据结构
6、MongoDB数据存储格式
文档型
--JSON
² MongoDB使用JSON(JavaScript ObjectNotation)文档存储记录。
² ?JSON数据库语句可以容易被解析
² ?Web 应用大量使用
² NAME-VALUE 配对,例如:
{
product: “car”,
brand: “Benz”,
color: “blue”}
--BSON
² 二进制的JSON,JSON文档的二进制编码存储格式
² BSON有JSON没有的Date和BinData
² MongoDB中document以BSON形式存放

> db.meeting.insert({meeting:"SHOUG June",Date:"2015-06-15"});
--灵活的数据格式
{
_id: ObjectID("1"),
username: “Silence”,
regDate: “10-10-2015”,
scores: {
math: "80",
english: "200"
}
}
文档里嵌入了文档
{
_id: ObjectID("1"),
username: “Silence”,
regDate: “10-10-2015”,
scores: {
math: "80",
english: "200"
}
Attr:[“a1”,”a2”]
}
一个KEY对应一个数组
文档里嵌入文档里嵌入文档里嵌入文档
7、优势:
开源产品
² ?MongoDB是开源产品
² ?On GitHub
² ?Licensed under the AGPL
² ?起源& 赞助by MongoDB公司
² ?提供商业版licenses 许可
支持水平扩展

支持多种存储引擎
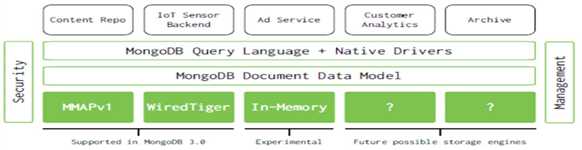
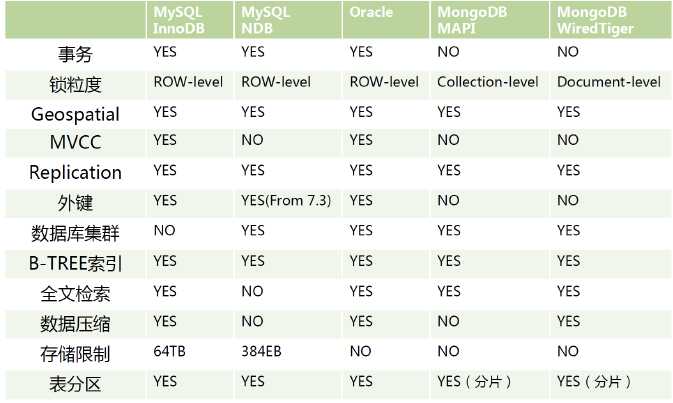
8、存储引擎比较
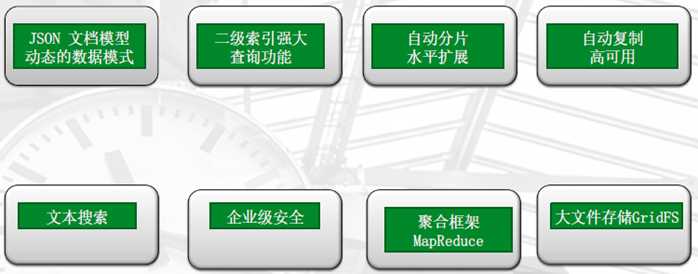
9、具备丰富的功能
1.5 MongoDB体系结构
l 跨平台
--Linux、Unix、Mac、Windows
--整体架构相同
l MongoDBServer
--实例、数据库及其对应关系
l 数据逻辑结构
--文档、集合、数据库
l 数据存储
--元数据、实际数据
l 数据逻辑结构
层次关系
--文档(document)
--集合(collection)
--数据库(database)

数据库
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
"show dbs" 命令可以显示所有数据的列表。
$ ./mongo
MongoDB shell version: 3.0.6
connecting to: test
> show dbs
local 0.078GB
test 0.078GB
>
执行 "db" 命令可以显示当前数据库对象或集合。
$ ./mongo
MongoDB shell version: 3.0.6
connecting to: test
> db
test
>
运行"use"命令,可以连接到一个指定的数据库。
> use local
switched to db local
> db
local
>
以上实例命令中,"local" 是你要链接的数据库。
在下一个章节我们将详细讲解MongoDB中命令的使用。
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串("")。
不得含有‘ ‘(空格)、.、$、/、和� (空字符)。
应全部小写。
最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config:
当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档
文档是一组键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
RDBMS 与 MongoDB 对应的术语:
|
RDBMS |
MongoDB |
|
数据库 |
数据库 |
|
表格 |
集合 |
|
行 |
文档 |
|
列 |
字段 |
|
表联合 |
嵌入文档 |
|
主键 |
主键 (MongoDB 提供了 key 为 _id ) |
|
数据库服务和客户端 |
|
|
Mysqld/Oracle |
mongod |
|
mysql/sqlplus |
mongo |
注意:文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
键不能含有� (空字符)。这个字符用来表示键的结尾。
.和$有特别的意义,只有在特定环境下才能使用。
以下划线"_"开头的键是保留的(不是严格要求的)。
集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
当第一个文档插入时,集合就会被创建。
合法的集合名
集合名不能是空字符串""。
集合名不能含有�字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
capped collections
Capped collections 就是固定大小的collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 "RRD" 概念类似。
Capped collections是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能 和标准的collection不同,你必须要显式的创建一个capped collection, 指定一个collection的大小,单位是字节。collection的数据存储空间值提前分配的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})
在capped collection中,你能添加新的对象。
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
数据库不允许进行删除。使用drop()方法删除collection所有的行。
注意: 删除之后,你必须显式的重新创建这个collection。
在32bit机器中,capped collection最大存储为1e9( 1X109)个字节。
元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),如下:
dbname.system.namespaces 列出所有名字空间。
dbname.system.indexes 列出所有索引。
dbname.system.profile 包含数据库概要(profile)信息。
dbname.system.users 列出所有可访问数据库的用户。
dbname.local.sources 包含复制对端(slave)的服务器信息和状态。
对于修改系统集合中的对象有如下限制。
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。 {{system.profile}}是可删除的。
--MongoDB与RDBMS数据结构逻辑对比
MongoDB适用场景
l 网站数据应用较多
l ?缓存
l ?大尺寸、低价值的数据
l ?高伸缩性的场景
业务架构经常发生变化的场景(表结构经常变,需求总在变)
架构变化频繁的场景,数据或者业务量膨胀式增长的情况
l ?用于对象及JSON数据的存储,应用平滑的业务。比如说py Java
1.6 MongoDB的搭建及基本操作
1、系统准备
(1)redhat或cnetos6.2以上系统
(2)系统开发包完整
(3)ip地址和hosts文件解析正常
(4)iptables防火墙&SElinux关闭
(5)关闭大页内存机制
########################################################################
root用户下
在vi /etc/rc.local最后添加如下代码
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
其他系统关闭参照官方文档:
https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
2、mongodb安装
(1)创建所需用户和组
groupadd -g 800 mongod
[email protected] tools]# useradd -u 801 -g800 mongod
[[email protected] tools]# id mongod
uid=800(mongod) gid=800(mongod) groups=800(mongod)
passwd mongod
(2)创建mongodb所需目录结构
mkdir -p /mongodb/bin
mkdir -p /mongodb/conf
mkdir -p /mongodb/log
mkdir -p /mongodb/data
(3)上传并解压软件到指定位置
mongodb-linux-x86_64-3.2.8.tgz
cd mongodb-linux-x86_64-3.2.8/bin/
cp * /mongodb/bin
(4)设置目录结构权限
chown -R mongod:mongod /mongodb
(5)设置用户环境变量
su - mongod
vi .bash_profile
export PATH=/mongodb/bin:$PATH
source .bash_profile
(6)启动mongodb
mongod
--dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017
--logappend --fork
启动参数介绍:
--dbpath=数据路径
--logpath 日志文件的位置及名字
--port 端口号
--logecting日志追加记录(默认是覆盖型)
--fork 以守护进程方式启动
(7)登录mongodb
[[email protected] ~]$ mongo
注:连接之后会有warning,需要修改
vim /etc/security/limits.conf
#* - nofile 65535
reboot重启生效
mongod --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017 --logappend -fork
如果不好用就在root下启动
(8)使用配置文件
mongod -f /mongodb/conf/mongodb.conf 启动
mongod -f /mongodb/conf/mongodb.conf --shutdown 关闭
------------
[[email protected] conf]$ cat
/mongodb/conf/mongodb.conf
logpath=/mongodb/log/mongodb.log
dbpath=/mongodb/data
port=27017
logappend=true
fork=true
[[email protected] conf]$
+++++++++++++++++++
(YAML模式:)
--
NOTE:
YAML does not support tab characters for indentation: use spaces instead.
--
systemLog:#系统日志模块
destination: file
path: "/mongodb/log/mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "<PATH>"
processManagement:#进程管理
fork: true
pidFilePath: <string>
net:#网络模块
bindIp: <ip>#监听地址
port: <port>#端口号
setParameter:
enableLocalhostAuthBypass: false
security:
authorization: enabled
replication:
oplogSizeMB: <NUM>
replSetName: "<REPSETNAME>"
secondaryIndexPrefetch: "all"
sharding:
clusterRole: <string>
archiveMovedChunks: <boolean>
---for mongos only
replication:
localPingThresholdMs: <int>
sharding:
configDB: <string>
---
.........
++++++++++++++++++++++
举例
vim /mongodb/conf/mongo.conf
systemLog:
destination: file
path: "/mongodb/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/data/"
processManagement:
fork: true
net:
port: 27017
mongod -f /mongodb/conf/mongodb.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
(9)mongodb的关闭方式
---kill进程形式
$ kill -2 PID
原理:-2表示向mongod进程发送SIGINT信号。
或
$ kill -4 PID
原理:-4表示向mognod进程发送SIGTERM信号。
---自带模式
admin> db.shutdownServer()
或
admin> db.adminCommand({shutdown:1})
或
$ mongod -f mongodb.conf --shutdown
killing process with pid: 1621
注:mongod进程收到SIGINT信号或者SIGTERM信号,会做一些处理
l 关闭所有打开的连接
l 将内存数据强制刷新到磁盘
l 当前的操作执行完毕
安全停止
!!!切记kill -9
数据库直接关闭
l 数据丢失
l 数据文件损失
l 修复数据库(成本高,有风险)
使用脚本启动
[[email protected] ~]# cat /etc/init.d/mongod
#!/bin/bash
#
#chkconfig: 2345 80 90
#description:mongodb
MONGODIR=/mongodb
MONGOD=$MONGODIR/bin/mongod
#MONGO=$MONGODIR/bin/mongo
#DBDIR=$MONGODIR/data
#LOGPATH=$MONGODIR/log/mongodb.log
MONGOCONF=$MONGODIR/conf/mongodb.conf
start() {
su - mongod -c "$MONGOD -f $MONGOCONF"
}
stop() {
su - mongod -c "$MONGOD -f $MONGOCONF --shutdown"
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 2
start
;;
*)
echo $"Usage: $0 {start|stop|restart}"
exit 1
esac
[[email protected] ~]#
修改权限
chmod +x /etc/init.d/mongod
1.7 多实例配置
[[email protected] ~]# su - mongod
[[email protected] ~]$ cd /mongodb/
[[email protected] mongodb]$ mkdir -p
27018/{conf,data,log}
[[email protected] 27018]$ cp
../conf/mongodb1.conf /mongodb/27018/conf/mongodb.conf
[[email protected] 27018]$ cat
conf/mongodb.conf
systemLog:
destination: file
path: "/mongodb/27018/log/mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/27018/data"
processManagement:
fork: true
net:
port: 27018
[[email protected] 27018]$
[[email protected] 27018]$ mongod -f /mongodb/27018/conf/mongodb.conf
about to fork child process, waiting until server is ready for connections.
forked process: 2546
child process started successfully, parent exiting
[[email protected] 27018]$
[[email protected] 27018]$ netstat -lutnp | grep mongod
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN 2376/mongod
tcp 0 0 0.0.0.0:27018 0.0.0.0:* LISTEN 2546/mongod
[[email protected] 27018]$
1.8 MongoDB的简单使用:
--帮助
help
KEYWORDS.help
KEYWORDS.[TAB]
db 和数据库管理操作有关的
rs 和replication set (复制集有关)
sh 和shard分片有关的命令
当use的时候,系统就会自动创建一个数据库。
如果use之后没有创建任何集合。
系统就会删除这个数据库。
– 删除数据库
如果没有选择任何数据库,会删除默认的test数据库
--常用操作
[[email protected] ~]$ mongo
MongoDB shell version: 3.2.8
connecting to: test
Server has startup warnings:
2017-11-29T13:21:04.895+0800 I CONTROL [initandlisten]
2017-11-29T13:21:04.895+0800 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. rlimits set to 15153 processes, 65535 files. Number of processes should be at least 32767.5 : 0.5 times number of files.
> show dbs;#查看所有数据库
local 0.000GB
> use local 切换库
switched to db local
> show tables; 查看表
startup_log
> use admin
switched to db admin
>
> show collections;
>
> db.stats()查看某一个数据库的状态
{
"db" : "admin",
"collections" : 0,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 0,
"numExtents" : 0,
"indexes" : 0,
"indexSize" : 0,
"fileSize" : 0,
"ok" : 1
}
> db.version()查看当前db版本
3.2.8
> db显示当前数据库
admin
> db.getName()
admin
>
查看当前数据库的连接机器地址
> db.getMongo()
connection to 127.0.0.1
>注意use 的时候会默认创建一临时个库,需要创建一个集合
mongos>
db.createCollection("abc")
{ "ok" : 1 }
mongos>
1.8.1 创建集合
> db.createCollection(‘a‘)
{ "ok" : 1 }
> show tables
a
1.8.2 在某个表中插入数据
> db.oldboy.insert({username:"old1"})
WriteResult({ "nInserted" : 1 })
> show tables
a
oldboy
>
> db.oldboy.find() 查询表中数据
{ "_id" : ObjectId("5a1e5d1ee6cdd57682fccb03"), "username" : "old1" }
>
1.8.3 删除集合
> db.a.drop()
true
> show tables
oldboy
>
1.8.4 改名
> db.oldboy.renameCollection("old")
{ "ok" : 1 }
> show tables
old
>
插入
for(i=0;i<10000;i++){ db.log.insert({"uid":i,"name":"mongodb","age":6,"date":new Date()}); }
查询uid为50的
db.log.find({uid:50})
{ "_id" : ObjectId("5a1e5f79e6cdd57682fccb36"), "uid" : 50, "name" : "mongodb", "age" : 6, "date" : ISODate("2017-11-29T07:19:21.451Z") }
> db.log.findOne()
{
"_id" : ObjectId("5a1e5f79e6cdd57682fccb04"),
"uid" : 0,
"name" : "mongodb",
"age" : 6,
"date" : ISODate("2017-11-29T07:19:21.225Z")
}
1.8.5 --查询集合中的记录数
app> db.log.find() //查询所有记录
注:默认每页显示20条记录,当显示不下的的情况下,可以用it迭代命令查询下一页数据。
设置每页显示数据的大小:
> DBQuery.shellBatchSize=50; //每页显示50条记录
50
app> db.log.findOne() //查看第1条记录
app> db.log.count() //查询总的记录数
1.8.6 --删除集合中的记录数
app> db.log.remove({}) //删除集合中所有记录
> db.log.remove({uid:0}) 删除集合中某一行
> db.log.distinct("name") //查询去掉当前集合中某列的重复数据:
[ "mm" ]
1.8.7 ==查看集合存储信息
app> db.log.stats()
app> db.log.dataSize() //集合中数据的原始大小
app> db.log.totalIndexSize() //集合中索引数据的原始大小
app> db.log.totalSize() //集合中索引+数据压缩存储之后的大小
app> db.log.storageSize() //集合中数据压缩存储的大小
> db.log.dataSize()
799920
> db.log.totalIndexSize()
188416
> db.log.totalSize()
704512
> db.log.storageSize()
516096
>
1.9 用户管理
MongoDB数据库默认是没有用户名及密码的,即无权限访问限制。为了方便数据库的管理和安全,需创建数据库用户。
1、在创建普通用户时,一般事先use 到想要设置权限的库下;或者所有普通用户使用同一个验证库,比如test
2、root角色的创建,要在admin下进行创建
3、创建用户时你use到的库,在将来登录时候,使用以下方式登录,否则是登录不了的
mongo -u oldboy -p 123 10.0.0.51/test
1.9.1 用户创建语法
01
老男孩IT教育,只培养技术精英
{
user: "<name>",
pwd: "<cleartextpassword>",
customData: { <any information> },
roles: [
{ role: "<role>",
db: "<database>" } | "<role>",
...
]
}
user字段:用户的名字;pwd字段:用户的密码;cusomData字段:为任意内容,例如可以为用户全名介绍;roles字段:指定用户的角色,可以用一个空数组给新用户设定空角色;roles字段,可以指定内置角色和用户定义的角色。
#常用角色说明见官方文档
https://docs.mongodb.com/manual/reference/built-in-roles/
1.9.2 创建用户
admin数据库
--创建超级管理员:管理所有数据库
$ mongo
use admin
db.createUser(
{
user: "root",
pwd: "root123",
roles: [ { role: "root", db: "admin" } ]
}
)
验证用户
db.auth(‘root‘,‘root123‘)
#注:用户创建完成后需在配置文件打开auth验证并重启后生效。
auth=true
修改配置文件
security:
authorization: enabled
重启登录
mongod -f /mongodb/conf/mongo.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
[[email protected] ~]$ mongo -uroot -proot123 10.0.0.51/admin
1.9.3 创建对某库的只读用户
> use test
switched to db test
> db.createUser(
... {
... user: "test",
... pwd: "test",
... roles: [ { role: "read", db: "test" } ]
... }
... )
Successfully added user: {
"user" : "test",
"roles" : [
{
"role" : "read",
"db" : "test"
}
]
}
> db.auth("test","test")
1
>
[[email protected] ~]$ mongo -utest -ptest test
> db.createCollection(‘b‘)
{
"ok" : 0,
"errmsg" : "not authorized on test to execute command { create: "b" }",
"code" : 13
}
>
1.9.4 自定义数据库
创建app数据库的管理员:先登录到admin数据库
use app
db.createUser(
{
user: "admin",
pwd: "admin",
roles: [ { role: "dbAdmin", db: "app" } ]
}
)
db.auth(‘admin‘,‘admin‘)
1.9.5 创建app数据库读写权限的用户并具有clusterAdmin权限:
use app
db.createUser(
{
user: "app04",
pwd: "app04",
roles: [ { role: "readWrite", db: "app" },
{ role: "clusterAdmin", db: "admin" }
]
}
)
1.9.6 创建app数据库读写权限的用户并对test数据库具有读权限:
use app
db.createUser(
{
user: "app03",
pwd: "app03",
roles: [ { role: "readWrite", db: "app" },
{ role: "read", db: "test" }
]
}
)
1.9.7 创建app数据库读、写权限的用户:
use app
db.createUser(
{
user: "app01",
pwd: "app01",
roles: [ "readWrite" ]
}
)
db.createUser(
{
user: "app02",
pwd: "app02",
roles: [ "read" ]
}
)
1.9.8 查询用户
> db.system.users.find();
{ "_id" : "admin.root", "user" : "root", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "X3moBn0Fl9UVJ2HNTKz5aA==", "storedKey" : "j7gwsqswfWYa4UUod/XkFQncDtw=", "serverKey" : "sS70OM2ysJ3j9pOB/4JiYBngI1A=" } }, "roles" : [ { "role" : "root", "db" : "admin" } ] }
{ "_id" : "test.test", "user" : "test", "db" : "test", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "QGW0NrAxGyuyv/XUicOLTQ==", "storedKey" : "6hsgOGTeJr6wQr7twSpB8p6OJZg=", "serverKey" : "GhuJrGy2nhlSNgMXFJa6oDgtU0o=" } }, "roles" : [ { "role" : "read", "db" : "test" } ] }
>
数据库用户角色(Database User Roles):
read:授予User只读数据的权限
readWrite:授予User读写数据的权限
数据库管理角色(Database Administration Roles):
dbAdmin:在当前dB中执行管理操作
dbOwner:在当前DB中执行任意操作
userAdmin:在当前DB中管理User
备份和还原角色(Backup and Restoration Roles):
backup
restore
跨库角色(All-Database Roles):
readAnyDatabase:授予在所有数据库上读取数据的权限
readWriteAnyDatabase:授予在所有数据库上读写数据的权限
userAdminAnyDatabase:授予在所有数据库上管理User的权限
dbAdminAnyDatabase:授予管理所有数据库的权限
集群管理角色(Cluster Administration Roles):
clusterAdmin:授予管理集群的最高权限
clusterManager:授予管理和监控集群的权限,A user with this role can access the config and local databases, which are used in sharding and replication, respectively.
clusterMonitor:授予监控集群的权限,对监控工具具有readonly的权限
hostManager:管理Server
1.9.9 删除用户
删除app01用户:先登录到admin数据库
# mongo -uroot–proot192.168.1.24/admin
use app
db.dropUser("app01")
第2章 数据操作语言CRUD简介
2.1 MongoDB与SQL的对比
术语与概念区别

2.2 SQL语言与CRUD语言对照

插入语句

查询类

数据更新操作

数据删除操作

第3章 MongoDB复制集技术
3.1 MongoDB复制集简介
一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合。复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础。
保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险,牛逼到不行。
换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载,简直就是云存储的翻版...
一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。
主服务器很重要,包含了所有的改变操作(写)的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。
每个复制集还有一个仲裁者,仲裁者不存储数据,只是负责通过心跳包来确认集群中集合的数量,并在主服务器选举的时候作为仲裁决定结果。
3.2 复制集架构介绍:
1、一般是1主2从的架构或者是1主多从的架构
2、普通主从1主库,2个普通从库。
为什么三个节点构成复制集?
因为在mongodb中原生态支持心跳检测。通过 raft 投票原则,必须大于50%的票数为准。
3、在mongodb中,从节点默认不让做任何操作。可以通过设置让从节点提供读服务
4、raft协议
1) 自动投票选主
2) 自动通知mongodb客户端,连接新主
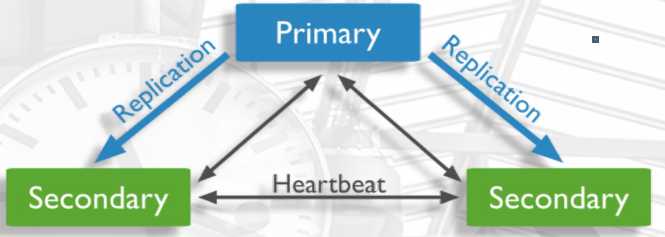
如果主服务器失效,会变成:
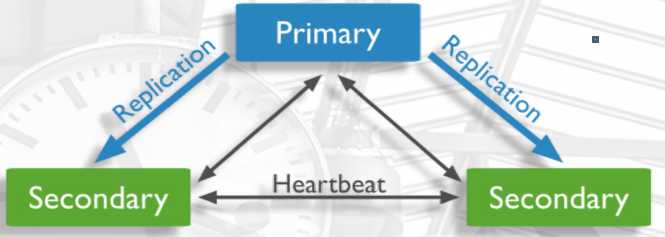
如果加上可选的仲裁者:
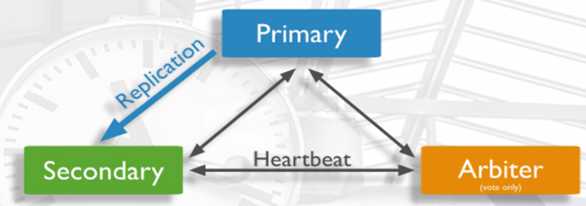
arbiter:指投票,不复制数据
仲裁节点,只做投票,不做复制数据,可以选择一个配置较低的主机,尽量和诸暨店放在不同的位置
隐藏节点(hidden节点)
客户端将不会把读请求分发到隐藏节点上,即使我们设定了复制集读选项。这些隐藏节点将不会收到来自应用程序的请求。我们可以将隐藏节点专用于报表节点或是备份节点。延时节点也应该是一个隐藏节点。

延时节点(delay节点)
延时节点的数据集是延时的,因此它可以帮助我们在人为误操作或是其他意外情况下恢复数据。举个例子,当应用升级失败,或是误操作删除了表和数据库时,我们可以通过延时节点进行数据恢复。
priority:优先级
{
"_id" : <num>, "host" : <hostname:port>, "priority" : 0, "slaveDelay" : <seconds>, "hidden" : true
}
3.3 MongoDB复制集原理
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
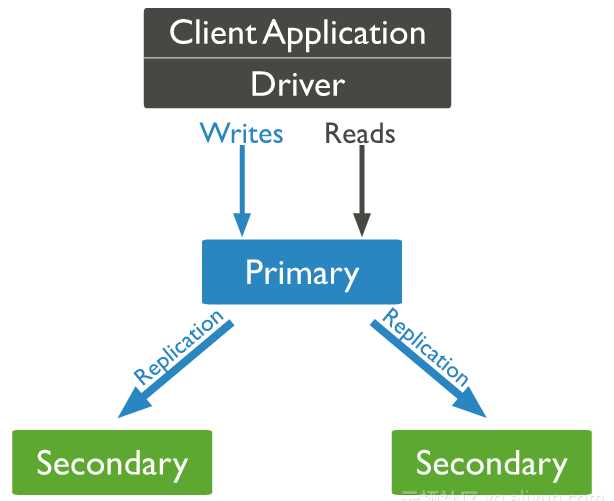
Primary选举
复制集通过replSetInitiate命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得『大多数』成员投票支持的节点,会成为Primary,其余节点成为Secondary。
『大多数』的定义
假设复制集内投票成员(后续介绍)数量为N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
|
投票成员数 |
大多数 |
容忍失效数 |
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
5 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
通常建议将复制集成员数量设置为奇数,从上表可以看出3个节点和4个节点的复制集都只能容忍1个节点失效,从『服务可用性』的角度看,其效果是一样的。(但无疑4个节点能提供更可靠的数据存储)
特殊的Secondary
² 正常情况下,复制集的Seconary会参与Primary选举(自身也可能会被选为Primary),并从Primary同步最新写入的数据,以保证与Primary存储相同的数据。
² Secondary可以提供读服务,增加Secondary节点可以提供复制集的读服务能力,同时提升复制集的可用性。另外,Mongodb支持对复制集的Secondary节点进行灵活的配置,以适应多种场景的需求。
Arbiter
l Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。
l 比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
l Arbiter本身不存储数据,是非常轻量级的服务,当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性。
Priority0
² Priority0节点的选举优先级为0,不会被选举为Primary
² 比如你跨机房A、B部署了一个复制集,并且想指定Primary必须在A机房,这时可以将B机房的复制集成员Priority设置为0,这样Primary就一定会是A机房的成员。(注意:如果这样部署,最好将『大多数』节点部署在A机房,否则网络分区时可能无法选出Primary)
Vote0
Mongodb 3.0里,复制集成员最多50个,参与Primary选举投票的成员最多7个,其他成员(Vote0)的vote属性必须设置为0,即不参与投票。
Hidden
Hidden节点不能被选为主(Priority为0),并且对Driver不可见。
因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务。
Delayed
Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时)。
因Delayed节点的数据比Primary落后一段时间,当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
数据同步
² Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的local.oplog.rs特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用。
² 因oplog的数据会不断增加,local.oplog.rs被设置成为一个capped集合,当容量达到配置上限时,会将最旧的数据删除掉。另外考虑到oplog在Secondary上可能重复应用,oplog必须具有幂等性,即重复应用也会得到相同的结果。
如下oplog的格式,包含ts、h、op、ns、o等字段
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "100" }
}
ts: 操作时间,当前timestamp + 计数器,计数器每秒都被重置
h:操作的全局唯一标识
v:oplog版本信息
op:操作类型
i:插入操作
u:更新操作
d:删除操作
c:执行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作针对的集合
o:操作内容,如果是更新操作
o2:操作查询条件,仅update操作包含该字段
Secondary初次同步数据时,会先进行init sync,从Primary(或其他数据更新的Secondary)同步全量数据,然后不断通过tailable cursor从Primary的local.oplog.rs集合里查询最新的oplog并应用到自身。
init sync过程包含如下步骤
² T1时间,从Primary同步所有数据库的数据(local除外),通过listDatabases + listCollections + cloneCollection敏命令组合完成,假设T2时间完成所有操作。
² 从Primary应用[T1-T2]时间段内的所有oplog,可能部分操作已经包含在步骤1,但由于oplog的幂等性,可重复应用。
² 根据Primary各集合的index设置,在Secondary上为相应集合创建index。(每个集合_id的index已在步骤1中完成)。
² oplog集合的大小应根据DB规模及应用写入需求合理配置,配置得太大,会造成存储空间的浪费;配置得太小,可能造成Secondary的init sync一直无法成功。比如在步骤1里由于DB数据太多、并且oplog配置太小,导致oplog不足以存储[T1, T2]时间内的所有oplog,这就Secondary无法从Primary上同步完整的数据集。
3.4 Primary选举
Primary选举除了在复制集初始化时发生,还有如下场景
² 复制集被reconfig
² Secondary节点检测到Primary宕机时,会触发新Primary的选举
² 当有Primary节点主动stepDown(主动降级为Secondary)时,也会触发新的Primary选举
Primary的选举受节点间心跳、优先级、最新的oplog时间等多种因素影响。
节点间心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
节点优先级
² 每个节点都倾向于投票给优先级最高的节点
² 优先级为0的节点不会主动发起Primary选举
² 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
Optime
拥有最新optime(最近一条oplog的时间戳)的节点才能被选为主。
网络分区
只有更大多数投票节点间保持网络连通,才有机会被选Primary;如果Primary与大多数的节点断开连接,Primary会主动降级为Secondary。当发生网络分区时,可能在短时间内出现多个Primary,故Driver在写入时,最好设置『大多数成功』的策略,这样即使出现多个Primary,也只有一个Primary能成功写入大多数。
3.5 复制集的读写设置
Read Preference
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
² primary: 默认规则,所有读请求发到Primary
² primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
² secondary: 所有的读请求都发到secondary
² secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
² nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
Write Concern
默认情况下,Primary完成写操作即返回,Driver可通过设置[Write Concern(https://docs.mongodb.org/manual/core/write-concern/)来设置写成功的规则。
如下的write concern规则设置写必须在大多数节点上成功,超时时间为5s。
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: majority, wtimeout: 5000 } }
)
上面的设置方式是针对单个请求的,也可以修改副本集默认的write concern,这样就不用每个请求单独设置。
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
异常处理(rollback)
² 当Primary宕机时,如果有数据未同步到Secondary,当Primary重新加入时,如果新的Primary上已经发生了写操作,则旧Primary需要回滚部分操作,以保证数据集与新的Primary一致。
² 旧Primary将回滚的数据写到单独的rollback目录下,数据库管理员可根据需要使用mongorestore进行恢复。
3.6 复制集部署及管理
3.6.1 规划
3个以上的mongodb节点或者多实例
多实例:
注意:多个端口:28017,28017,28018,28019,28020
多套目录:
mkdir -p /mongodb/28017/conf /mongodb/28017/data /mongodb/28017/log
mkdir -p /mongodb/28018/conf /mongodb/28018/data /mongodb/28018/log
mkdir -p /mongodb/28019/conf /mongodb/28019/data /mongodb/28019/log
mkdir -p /mongodb/28020/conf /mongodb/28020/data /mongodb/28020/log
多套文件
/mongodb/28017/conf/mongod.conf
/mongodb/28018/conf/mongod.conf
/mongodb/28019/conf/mongod.conf
/mongodb/28020/conf/mongod.conf
vi /mongodb/28017/conf/mongod.conf
cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
cp /mongodb/28017/conf/mongod.conf /mongodb/28020/conf/
[[email protected] mongodb]$ sed ‘s#29018#28020#g‘ 28020/conf/mongod.conf -i
[[email protected] mongodb]$ sed ‘s#28017#28019#g‘ 28019/conf/mongod.conf -i
[[email protected] mongodb]$ sed ‘s#28017#28018#g‘ 28018/conf/mongod.conf -i
3.6.2 配置文件
vi /mongodb/28017/conf/mongod.conf
systemLog:
destination: file
path: /mongodb/28017/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28017/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
port: 28017
replication:
oplogSizeMB: 2048
replSetName: my_repl
3.6.3 启动多实例
(5)启动多个实例备用
mongod -f /mongodb/28017/conf/mongod.conf
mongod -f /mongodb/28018/conf/mongod.conf
mongod -f /mongodb/28019/conf/mongod.conf
mongod -f /mongodb/28020/conf/mongod.conf
[[email protected] mongodb]$ netstat -lnutp| grep mong
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:28017 0.0.0.0:* LISTEN 1751/mongod
tcp 0 0 0.0.0.0:28018 0.0.0.0:* LISTEN 1774/mongod
tcp 0 0 0.0.0.0:28019 0.0.0.0:* LISTEN 1787/mongod
tcp 0 0 0.0.0.0:28020 0.0.0.0:* LISTEN 1810/mongod
3.6.4 配置复制集(1主2从)
连接到28017主库
[[email protected] mongodb]$ mongo -port 28017 admin
> config = {_id: ‘my_repl‘, members: [
{_id: 0, host: ‘10.0.0.51:28017‘},
{_id: 1, host: ‘10.0.0.51:28018‘},
{_id: 2, host: ‘10.0.0.51:28019‘}]
}
>
> rs.initiate(config)
{ "ok" : 1 }
my_repl:OTHER>
查询复制集状态
rs.status()
3.6.5 测试
在主库插入一个数据
my_repl:PRIMARY> db.movies.insert([ { "title" : "Jaws", "year" : 1975, "imdb_rating" : 8.1 },
... { "title" : "Batman", "year" : 1989, "imdb_rating" : 7.6 },
... ] );
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 2,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
从库查询:
mongo -port 28018 admin
my_repl:SECONDARY> db.movies.find().pretty();
注:在mongodb复制集当中,默认从库不允许读写。
rs.slaveOk();
my_repl:SECONDARY> db.movies.find().pretty();
3.6.6 查看复制集状态
rs.status(); //查看整体复制集状态
rs.isMaster(); // 查看当前是否是主节点
rs.add("ip:port"); // 新增从节点
rs.addArb("ip:port");
// 新增仲裁节点
my_repl:PRIMARY> rs.addArb("10.0.0.51:28020")
{ "ok" : 1 }
rs.remove("ip:port"); // 删除一个节点
my_repl:PRIMARY> rs.add("10.0.0.51:28020")
{ "ok" : 1 }
my_repl:PRIMARY> rs.remove("10.0.0.51:28020")
{ "ok" : 1 }
my_repl:PRIMARY>
注:添加特殊节点时,(1)可以在搭建阶段添加设置一些特性
(2)可以使用修改配置的方式将普通节点设置为特殊节点
/*找到需要改为延迟性同步的数组号*/;
3.6.7 修改节点特殊属性
配置延时节点(一般延时节点也配置成hidden)
cfg=rs.conf()
cfg.members[2].priority=0
cfg.members[2].slaveDelay=120 120 2分钟
cfg.members[2].hidden=true
rs.reconfig(cfg)
--------
配置成功后查看属性
使用rs.conf()查看
"_id" : 2,
"host" : "10.0.0.52:28019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : true,
"priority" : 0,
"tags" : {
},
"slaveDelay" : NumberLong(120),
"votes" : 1
3.6.8 副本集操作命令
--查看副本集的配置信息
admin> rs.config()
--查看副本集各成员的状态
admin> rs.status()
--副本集角色切换(不要人为顺便操作)
admin> rs.stepDown()
注:
admin> rs.freeze(300) //锁定从,使其不会转变成主库
freeze()和stepDown单位都是秒。
--设置副本节点可读:在副本节点执行
admin> rs.slaveOk()
eg:
admin> use app
switched to db app
app> db.createCollection(‘a‘)
{ "ok" : 0, "errmsg" : "not master", "code" : 10107 }
--查看副本节点
admin> rs.printSlaveReplicationInfo()
source: 192.168.1.22:27017
syncedTo: Thu May 26 2016 10:28:56 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
第4章 MongoDB分片技术简介
4.1 分片介绍
分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。通过一个名为mongos的路由进程进行操作,mongos知道数据和片的对应关系(通过配置服务器)。大部分使用场景都是解决磁盘空间的问题,对于写入有可能会变差,查询则尽量避免跨分片查询。使用分片的时机:
1,机器的磁盘不够用了。使用分片解决磁盘空间的问题。
2,单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源。
3,想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源。
4.2 分片集群架构
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。
² 垂直扩展:增加更多的CPU和存储资源来扩展容量。
² 水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
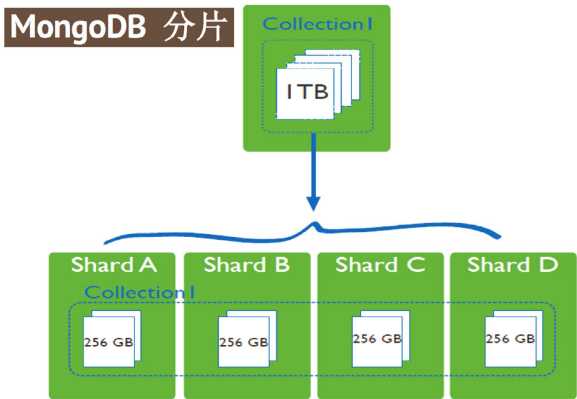
4.2.1 分布式集群
1、分布式系统设计理念
(1)分布式存储
能够将大数据按照一定的算法,均匀的分布到不同的节点上,能够按照原有的设计存储策略,提取数据。
(2)分布式的业务系统
除了时限分布式存储,还要考虑数据热点问题。
2、mongodb分片集群(原生态的分布式集群)
(1)分布式存储系统,并自带了自动分片和均衡的特性
(2)将来能 能不能成为一个分布式业务系统,取决于使用者。
4.2.2 分片集群的构造
1) mongos:数据路由,和客户端打交道的模块,mongos本身没有任何数据,他也不知道该怎么处理这些数据,去config server
2) config server:所有存取数据分方式,所有shard节点的信息,分片功能的一些配置信息,可以理解为真实数据的元数据。
3) shard:真正的数据存储位置,以chunk为单位存数据,每个分片是单独的 mongod 或者是复制集,在生产环境中,所有的分片都应该是复制集。
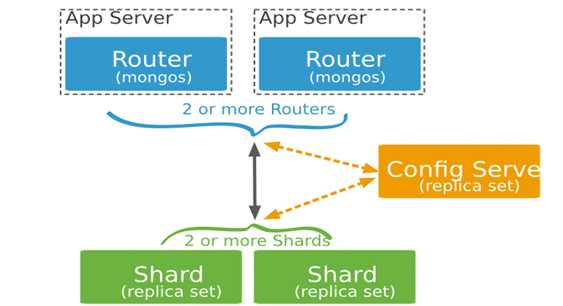
ConfigServer
存储集群所有节点、分片数据路由信息。默认需要配置3个ConfigServer节点。
Mongos
提供对外应用访问,所有操作均通过mongos执行。一般有多个mongos节点。数据迁移和数据自动平衡。
Mongod
存储应用数据记录。一般有多个Mongod节点,达到数据分片目的。
MongoDB分片由这三个节点构成,大概工作模式就是应用程序通过mongos路由到Config Server中取元数据,然后通过元数据到Shard中去数据并返回。
4.3 数据分布(chunk)
1) 使用chunk来存储数据
2) 集群搭建完成后,默认开启一个chunk,大小64M
3) 存储需求超过64M,chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk
4) chunk会被自动均衡迁移
chunksize的选择
² 适合业务的chunksize是最好的。
² chunk的分裂和迁移:非常消耗IO资源。
² chunk分裂的时机:插入和更新,读数据不会分裂。
² chunksize的选择:
n 小的chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。
n 大的chunksize:数据分裂少。数据块移动集中消耗IO资源。
² 通常100-200M
路由和平衡
当数据写入时,MongoDBCluster根据分片键设计写入数据。
当外部语句发起数据查询时,MongoDB根据数据分布自动路由至指定节点返回数据。
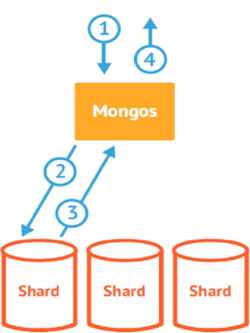
平衡(数据分布策略)
ShardedCluster支持将单个集合的数据分散存储在多shard上,用户可以指定根据集合内文档的某个字段即shard key来分布数据。
Mongos均衡特性
如图,第一个chunk的范围就是uid从-∞到12000范围内的数据。第二个就是12000到58000 。以此类推。对于一个刚配置为Sharding的collection ,最开始只有一个chunk,范围是从-∞到+∞。


随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
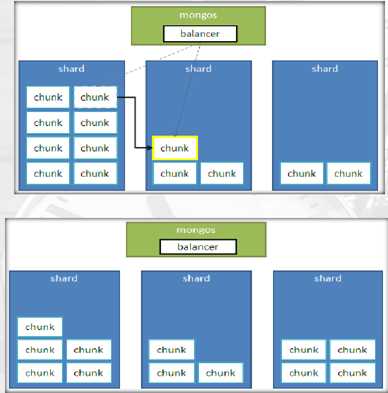
4.4 分片应用
片键(shard key)
MongoDB中数据的分片是、以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。所以一个好的片键对分片至关重要。片键必须是一个索引,通过sh.shardCollection加会自动创建索引(前提是此集合不存在的情况下)。一个自增的片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos会对结果进行归并排序。
对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。为了按照片键划分数据块,MongoDB使用基于范围的分片方式或者 基于哈希的分片方式。
² ?必须为分片collection 定义分片键。
² ?基于一个或多个列(类似一个索引)。
² ?分片键定义数据空间。
² ?想象key space 类似一条线上一个点数据。
² ?一个key range 是一条线上一段数据。
以范围为基础的分片
对于基于范围的分片,MongoDB按照片键的范围把数据分成不同部分。假设有一个数字的片键:想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点。MongoDB把这条直线划分为更短的不重叠的片段,并称之为数据块,每个数据块包含了片键在一定范围内的数据。在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
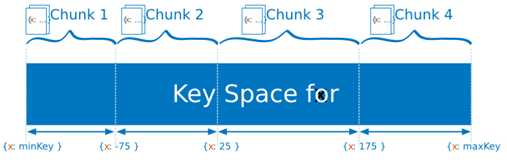
按照片键取值范围来作为数据块划分的区间依据,优点是按范围查询的时候它的效率很高,当给定一个查询范围,根据mongos中的映射表可以很快的定位到分片上的数据块。除此之外当两个分片的键取值比较靠近的时候,会被放到相近的块中,由于数据的局部性原理,这样的话可以加快查询效率,同时也可以减少内存换页次数。
缺点是可能会导致数据分布不均衡,如果选择的片键具有线性的性质,例如时间,将其作为片键的话 ,在某个时间段的写请求(读请求)都会被映射到同一个分片的同一个数据块上, 这样的话不仅会降低系统的读写性能,而且也会因写操作过于集中导致片间的不平衡。
注意:对于升序片键,要分析数据分布性问题,首先我们要记住分片是基于范围的。使用升序的片键,所有最新插入的数据都会落到某个很小的连续范围内。也就是说,这些插入都会被路由到一个块上,而这个块肯定存在某个片上,这实际上抵消了分片一个很大的好处,即将插入的负载自动分布到不同的机器上,这对插入负载很高的应用是不合理的。而且,mongodb是带平衡器的,如果某个片上的chunk过多,那么平衡器会将多出的chunk转移到其它片,升序片键其实也加重了转移chunk的负担
注意,升序片键并不影响更新,只要是随机更新的就可以。再想象这样一种情况,在最初的时候,整个分片里只有一个块,例如1到10000,当数据量增长至20000的时候,则该分片被分成两个数据块,然后将10000到20000的数据块迁移到分片2上,而之后,所有的写入操作都是写入到分片2中。这就造成了热点全部集中到了分片2上,而人工造成了不平衡的情况。
基于哈希的分片
分片过程中利用哈希索引作为分片的单个键,且哈希分片的片键只能使用一个字段,而基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有”相近”片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档。
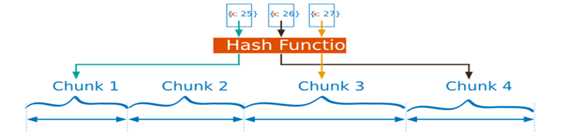
优点是可以确保一个比较均衡的数据分布,因为即使当两个文档的片键取值很接近的时候,例如上面例子中一个x=25,一个x=26,它们的哈希结果也会有很大的差别,这样的话数据会随机的分布到集群中,有利于数据的均衡的分布,减少数据块的移动次数,同时由于数据分散会减少单个数据块的写操作的压力,提高写入速度。
缺点是随机划分导致数据过于分散,当要查询某个范围内的数据时比如年龄大于20小于25的所有男生信息,如果直接使用范围划分的话,由于其具有良好的数据局部性特点,可能只要访问几个相邻的数据块就行了, 但是如果要使用哈希划分的方法很可能要访问所有的数据块。
注意:
对于像哈希这种完全随机片键,可以防止数据过度集中的分布性问题,有效减轻单个片的插入负载。但这并不完全合理。假设分片集合里的每个文档都包含一个MD5,而且MD5就是分片键,在对每个分片的MD5字段索引进行插入的时候,每次插入过程中,索引中的每个虚拟内存分页都有可能被访问到,实际上这就意味着索引必须总是装在内存里,如果索引和数据不断增多,超出了物理内存的限制,那么就会产生页错误(page fault),导致性能下降。
这其实是局部引用性问题。局部的概念,在这里指任意给定时间间隔内所访问的数据基本都是有关系的,例如虽然升序的片键是糟糕的,但是它提供了很好的局部性,对索引的连续插入都会发生在最近使用的虚拟内存分页里;因此,在任意时刻内存里只要有一部分索引就可以了。
再用上边的例子,比如说MD5是用户存的文件的MD5值,作为片键,用户上传100个文件,那么对索引的修改就基本会发生在随机的100个地方,但是如果我们使用用户ID作为片键,那么每次写索引基本都会发生在同一个地方,因为插入的文档都拥有相同的用户ID值。这就利用了局部性。
完全随机片键还有一个问题,对这个片键任意一个有意义的范围查询,都会被发送到所有的分片上,然后返回mongos汇总。但是对一个较粗粒度的片键进行范围查询,是可以落到单个分片上。
除了上面说的两种不好的片键之外,还有一种小基数的片键,即片键的值域比较小,通过该片键只能分成有限个数的片,取值有限的片键。这是一种粗力度的片键,比如上边说的用户ID。如果按照用户ID分片,你可以预料到插入会分布在各个分片上,因为无法预知哪个用户何时会插入数据。这样一来,粗粒度分片键也能拥有随机性,还能发挥分片集群的优势。而且粗粒度的片键还能使用局部性带来的效率提升。当某个用户上传100个文件,基于用户ID字段的分片建能确保这些插入都落到同一个分片上,并几乎能写入索引的同一部分,这样效率很高。粗粒度分片键在分布性和局部性上都表现很好,但是它也有一个很难解决的问题:块有可能无限制的增长。想想基于用户ID的片键,假如有几个特殊用户,他们上传了上百万个文件,那么一个块里就可能只有一个用户ID,这个块能拆分么?不能,因为用户ID是最小的粒度,拆分了查询就没法路由到数据。这就造成分片之间数据量不均衡。更典型的就是type,status这类的字段,因为它们的选择性实在是太低,导致无法拆分。片键基比较小时,所有的键值相同导致MongoDB不能分裂Chunk,迁移这些不可分裂的Chunk将更加耗时,即使迁移后也难以保证数据在各个分片上的平衡。Chunk数量被基约束住后,我们就不能利用MongoD分片集群特性将集合部署到更多的机器。
注意:1.片键可以是集合的索引,也可以是集合索引的部分前缀。
2.集群进行插入和查询的时候都要参照片键,它就相当于关系数据库中分库分表的作用。
3.如果查询条件中包含片键或者片键前缀的的话, mongos会将这个请求路由到分片的一个子集上;否则的话,mongos必须将请求转发到包含该集合所有文档的分片上。
例如: 片键 {
zipcode: 1, u_id: 1, c_date: 1 }
如果查询请求包含以下的字段的话:
{ zipcode: 1 }
{ zipcode 1,u_id 1}
{zipcode:1,u_id:1,c_date:1}
mongos都会将其路由到集合的子集上。
分片注意事项
² 分片键是不可变。
² 分片键必须有索引。
² 分片键大小限制512bytes。
² 分片键用于路由查询。
² MongoDB不接受已进行collection级分片的collection上插入无分片键的文档(也不支持空值插入)
分片键选择建议
递增的shardingkey
数据文件挪动小。(优势)
² 因为数据文件递增,所以会把insert的写IO永久放在最后一片上,造成最后一片的写热点。
² 同时,随着最后一片的数据量增大,将不断的发生迁移至之前的片上。
随机的shardingkey
² 数据分布均匀,insert的写IO均匀分布在多个片上。(优势)
² 大量的随机IO,磁盘不堪重荷。
混合型key
² 大方向随机递增。
² 小范围随机分布
一个好的片键必须包含的特性:
1、保证CRUD能利用局限性 ==》升序片键的优点
2、将插入数据均匀分布到各个分片上 ==》随机片键的优点
3、有足够的粒度进行块拆分 ==》粗粒度片键的优点
满足这些要求的的片键通常由两个字段组成,第一个是粗粒度,第二个是粒度较细。那么我们需要使用复合片键。例如对上面的例子,选取{userid:1,_id:1}作为片键,当用户同时插入数据时,我们可以预见大多数情况下,这些数据会被均匀的分布到所有的片上,而且分片里的唯一字段_id能保证对任意一个文档的查询和更新始终都能指向单个分片。如果对用户ID执行更复杂的查询,那么路由也只会将查询路由包含此用户ID存在的片上,而不会发到所有分片。由于_id(升序)的存在,保证了块始终是能继续拆分的,哪怕用户创建了大量文档,情况也是如此。
所以在选择片键时尽量能保持良好的数据局部性而又不会导致过度热点的出现,很多时候,组合片键是一种比较常用的做法。
除此之外,也可以选择我们经常查询的字段作为片键,这类分片键可以使得查询时mongos仅仅将查询发送给特定的mongod实例,不需要等待多个实例返回数据后再进行合并。
4.5 分片集群搭建
4.5.1 规划:
mongos:
port 38017
dir:/mongodb/38017/conf /mongodb/38017/log /mongod/38017/data
confdb:
port:38018,38019,38020
replSetName: configReplSet
clusterRole: configsvr
dir:
/mongodb/38018/conf /mongodb/38018/log /mongod/38018/data
/mongodb/38019/conf /mongodb/38019/log /mongod/38019/data
/mongodb/38020/conf /mongodb/38020/log /mongod/38020/data
shard1:
port:38021,38022,38023
replSetName: sh1
clusterRole: shardsvr
dir:
/mongodb/38021/conf /mongodb/38021/log /mongod/38021/data
/mongodb/38022/conf /mongodb/38022/log /mongod/38022/data
/mongodb/38023/conf /mongodb/38023/log /mongod/38023/data
shard2:
port:38024,38025,38026
replSetName: sh2
clusterRole: shardsvr
dir:
/mongodb/38024/conf /mongodb/38024/log /mongod/38024/data
/mongodb/38025/conf /mongodb/38025/log /mongod/38025/data
/mongodb/38026/conf /mongodb/38026/log /mongod/38026/data
4.5.2 shard复制集配置:
2.1目录创建:
mkdir -p /mongodb/{38021..38026}/conf
mkdir -p /mongodb/{38021..38026}/log
mkdir -p /mongodb/{38021..38026}/data
配置文件
vi /mongodb/38021/conf/mongodb.conf
systemLog:
destination: file
path: /mongodb/38021/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38021/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38021
replication:
oplogSizeMB: 2048
replSetName: sh1
sharding:
clusterRole: shardsvr
processManagement:
fork: true
cp /mongodb/38021/conf/mongodb.conf /mongodb/38022/conf/
cp /mongodb/38021/conf/mongodb.conf /mongodb/38023/conf/
sed ‘s#38021#38022#g‘ /mongodb/38022/conf/mongodb.conf -i
sed ‘s#38021#38023#g‘ /mongodb/38023/conf/mongodb.conf -i
第二套
sh2:
vi /mongodb/38024/conf/mongodb.conf
========
根据需求修改相应参数:
systemLog:
destination: file
path: /mongodb/38024/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38024/data
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38024
replication:
oplogSizeMB: 2048
replSetName: sh2
sharding:
clusterRole: shardsvr
processManagement:
fork: true
========
cp /mongodb/38024/conf/mongodb.conf /mongodb/38025/conf/
cp /mongodb/38024/conf/mongodb.conf /mongodb/38026/conf/
sed ‘s#38024#38025#g‘ /mongodb/38025/conf/mongodb.conf -i
sed ‘s#38024#38026#g‘ /mongodb/38026/conf/mongodb.conf -i
[[email protected] mongodb]$ touch /mongodb/{28021..28026}/conf/mongodb.conf
启动
mongod -f /mongodb/38021/conf/mongodb.conf
mongod -f /mongodb/38022/conf/mongodb.conf
mongod -f /mongodb/38023/conf/mongodb.conf
mongod -f /mongodb/38024/conf/mongodb.conf
mongod -f /mongodb/38025/conf/mongodb.conf
mongod -f /mongodb/38026/conf/mongodb.conf
配置
mongo --port 38021
use admin
config = {_id: ‘sh1‘, members: [
{_id: 0, host: ‘10.0.0.51:38021‘},
{_id: 1, host: ‘10.0.0.51:38022‘},
{_id: 2, host: ‘10.0.0.51:38023‘,"arbiterOnly":true}]
}
> rs.initiate(config)
mongo --port 38024
use admin
config = {_id: ‘sh2‘, members: [
{_id: 0, host: ‘10.0.0.51:38024‘},
{_id: 1, host: ‘10.0.0.51:38025‘},
{_id: 2, host: ‘10.0.0.51:38026‘,"arbiterOnly":true}]
}
> rs.initiate(config)
4.5.3 config节点配置:
3.1目录创建:
mkdir -p /mongodb/38018/conf /mongodb/38018/log /mongodb/38018/data
mkdir -p /mongodb/38019/conf /mongodb/38019/log /mongodb/38019/data
mkdir -p /mongodb/38020/conf /mongodb/38020/log /mongodb/38020/data
3.2修改配置文件:
vi /mongodb/38018/conf/mongodb.conf
systemLog:
destination: file
path: /mongodb/38018/log/mongodb.conf
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38018/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38018
replication:
oplogSizeMB: 2048
replSetName: configReplSet
sharding:
clusterRole: configsvr
processManagement:
fork: true
cp /mongodb/38018/conf/mongodb.conf /mongodb/38019/conf/
cp /mongodb/38018/conf/mongodb.conf /mongodb/38020/conf/
sed ‘s#38018#38019#g‘ /mongodb/38019/conf/mongodb.conf -i
sed ‘s#38018#38020#g‘ /mongodb/38020/conf/mongodb.conf -i
启动节点,并配置复制集
mongod -f /mongodb/38018/conf/mongodb.conf
mongod -f /mongodb/38019/conf/mongodb.conf
mongod -f /mongodb/38020/conf/mongodb.conf
mongo --port 38018
use admin
config = {_id: ‘configReplSet‘, members: [
{_id: 0, host: ‘10.0.0.51:38018‘},
{_id: 1, host: ‘10.0.0.51:38019‘},
{_id: 2, host: ‘10.0.0.51:38020‘}]
}
> rs.initiate(config)
4.5.4 mongos节点配置:
4.1创建目录:
mkdir -p /mongodb/38017/conf /mongodb/38017/log /mongodb/38017/data
4.2配置文件:
vi /mongodb/38017/conf/mongos.conf
systemLog:
destination: file
path: /mongodb/38017/log/mongos.log
logAppend: true
net:
port: 38017
sharding:
configDB: configReplSet/10.0.0.51:38018,10.0.0.51:38019,10.0.0.51:38020
processManagement:
fork: true
4.3启动mongos
[[email protected] ~]$ mongos -f /mongodb/38017/conf/mongos.conf
4.6 分片集群操作
[[email protected] mongodb]$ mongo 10.0.0.51:38017/admin #登录
(2)添加分片
> db.runCommand( { addshard : "sh1/10.0.0.51:38021,10.0.0.51:38022,10.0.0.51:38023",name:"shard1"} )
> db.runCommand( { addshard : "sh2/10.0.0.51:38024,10.0.0.51:38025,10.0.0.51:38026",name:"shard2"} )
(3)列出分片
mongos> db.runCommand( { listshards : 1 } )
(4)整体状态查看
mongos> sh.status();
Test库下的vast大表进行手工分片
1、激活数据库分片功能
mongo --port 38017 admin
admin> ( { enablesharding : "数据库名称" } )
eg:
admin> db.runCommand( { enablesharding : "test" } )
2、指定分片建对集合分片
eg:范围片键
--创建索引
Use test
admin> db.vast.ensureIndex( { id: 1 } )
开启分片
use admin
admin> db.runCommand( { shardcollection : "test.vast",key : {id: 1} } )
3、集合分片验证业务模拟
admin> use test
test> for(i=0;i<2000000;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
test> db.vast.stats()
--范围片键
admin> sh.shardCollection("数据库名称.集合名称",key : {分片键: 1} )
sh.shardCollection("test.vast",key : {id: 1} )
或
admin> db.runCommand( { shardcollection : "数据库名称.集合名称",key : {分片键: 1} } )
admin> db.runCommand( { shardcollection : "test.vast",key : {id: 1} } )
eg:
admin > sh.shardCollection("test.vast",key : {id: 1} )
或
admin> db.runCommand( { shardcollection : "test.vast",key : {id: 1} } )
--哈希片键
admin > sh.shardCollection( "数据库名.集合名", { 片键: "hashed" } )
eg:
创建哈希索引
对于oldboy库下的vast表建立hash索引
Use admin
admin> db.vast.ensureIndex( { a: "hashed" } )
开启分片
admin > sh.shardCollection( "test.vast", { a: "hashed" } )
hash分片结果测试
mongo --port 38021
use oldboy
db.vast.count();
mongo --port 38024
use oldboy
db.vast.count();
在复制集shard中查看
[[email protected] ~]$ mongo --host 10.0.0.52 --port 28021
sh1:PRIMARY> show dbs
admin 0.000GB
local 0.001GB
test 0.001GB
sh1:PRIMARY> use test
switched to db test
sh1:PRIMARY> show tables
abc
vast
4、判断是否Shard集群
admin> db.runCommand({ isdbgrid : 1})
5、列出所有分片信息
admin> db.runCommand({ listshards : 1})
6、列出开启分片的数据库
admin> use config
config> db.databases.find( { "partitioned": true } )
config> db.databases.find() //列出所有数据库分片情况
7、查看分片的片键 必须要 use 到 config
config> db.collections.find()
{ "_id" : "test.vast", "lastmodEpoch" : ObjectId("5a20ba8a50bb7c4486921325"), "lastmod" : ISODate("1970-02-19T17:02:47.296Z"), "dropped" : false, "key" : { "id" : 1 }, "unique" : false }
mongos>
8、查看分片的详细信息
admin> db.printShardingStatus()
或
admin> sh.status()
9、删除分片节点
sh.getBalancerState()
mongos> db.runCommand( { removeShard: "shard2" } )
4.6.1 blancer操作
mongos的一个重要功能,自动巡查所有shard节点上的chunk的情况,自动做chunk。
什么时候工作?
1、自动运行,会检测系统不繁忙的时候做迁移
2、在做节点删除的时候,立即开始迁移工作
3、blancer只能在预设定的时间窗口内运行
sh.getBalancerState() #查看状态
mongos> sh.stopBalancer()#关闭
mongos> sh.startBalancer()#开启
定义balancer的工作窗口(很重要):
db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "00:00", stop : "5:00" } } }, true )
自定义 自动平衡进行的时间段
// connect to mongos
> db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "00:00", stop : "5:00" } } }, true )
注意:设置时间窗口的原则:
1、避开业务繁忙时期
2、避开备份时间窗口
扩展关于集合的balance
关闭某个集合的balance
sh.disableBalancing("students.grades")
打开某个集合的balance
sh.enableBalancing("students.grades")
确定某个集合的balance是开启或者关闭
db.getSiblingDB("config").collections.findOne({_id : "students.grades"}).noBalance;
第5章 MongoDB备份恢复方式简介
5.1 备份恢复工具介绍
l mongodump/mongorestore
l mongoexport/mongoimport
商业化的工具
MMS
opsmanager
mongodump命令脚本语法如下:
>mongodump -h dbhost -d dbname -o dbdirectory
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:
需要备份的数据库实例,例如:test
-o:
备份的数据存放位置,例如:c:datadump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
-q:指明导出数据的过滤条件
-j, --numParallelCollections= number of collections to dump in parallel (4 by default)
--oplog 备份的同时备份oplog
-p:指明数据库的密码
mongorestore命令脚本语法如下:
>mongorestore -h <hostname><:port> -d dbname <path>
--host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017
--db , -d :
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
<path>:
mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:datadump est。
你不能同时指定 <path> 和 --dir 选项,--dir也可以设置备份目录。
--dir:
指定备份的目录
你不能同时指定 <path> 和 --dir 选项。
1、备份工具区别在哪里?
l mongoexport/mongoimport导入/导出的是JSON格式或者CSV格式,
l mongodump/mongorestore导入/导出的是BSON格式。
l JSON可读性强但体积较大,BSON则是二进制文件,体积小但对人类几乎没有可读性。
l 在一些mongodb版本之间,BSON格式可能会随版本不同而有所不同,所以不同版本之间用mongodump/mongorestore可能不会成功,具体要看版本之间的兼容性。当无法使用BSON进行跨版本的数据迁移的时候,使用JSON格式即mongoexport/mongoimport是一个可选项。
l 跨版本的mongodump/mongorestore个人并不推荐,实在要做请先检查文档看两个版本是否兼容(大部分时候是的)。
l JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。使用时应该注意。
注意:跨版本、夸架构的备份恢复用?mongoexport/mongoimport。常规的备份恢复使用,mongodump/mongorestore。
2、mongodump和mongorestore介绍
mongodump能够在Mongodb运行时进行备份,它的工作原理是对运行的Mongodb做查询,然后将所有查到的文档写入磁盘。
但是存在的问题时使用mongodump产生的备份不一定是数据库的实时快照,如果我们在备份时对数据库进行了写入操作,
则备份出来的文件可能不完全和Mongodb实时数据相等。另外在备份时可能会对其它客户端性能产生不利的影响。
5.2 mongoexport和mongoimport 迁移
==创建集合并插入数据:
admin> use app
switched to db app
app> for(i=0;i<200;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
app> db.vast.find()
1、导出工具mongoexport
Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。
(1)版本差异较大
(2)异构平台数据迁移
mongoexport具体用法如下所示:
$ mongoexport --help
参数说明:
-h:指明数据库宿主机的IP
-u:指明数据库的用户名
-p:指明数据库的密码
-d:指明数据库的名字
-c:指明collection的名字
-f:指明要导出那些列
-o:指明到要导出的文件名
-q:指明导出数据的过滤条件
--authenticationDatabase admin
--备份app库下的vast集合
$ mongoexport -h 192.168.1.21:30000 -uroot -pguo --authenticationDatabase admin -d app -c vast -o /home/mongod/backup/vasts.dat
注:备份文件的名字可以自定义,默认导出了JSON格式的数据。
如果我们需要导出CSV格式的数据,则需要使用--csv参数:
$ mongoexport -h 192.168.1.21:30000 -uroot -pguo --authenticationDatabase admin -d app -c vast --type=csv -f id,name -o /home/mongod/backup/vast_csv.dat
2、导入工具mongoimport
Mongodb中的mongoimport工具可以把一个特定格式文件中的内容导入到指定的collection中。该工具可以导入JSON格式数据,也可以导入CSV格式数据。具体使用如下所示:
$ mongoimport --help
参数说明:
-h:指明数据库宿主机的IP
-u:指明数据库的用户名
-p:指明数据库的密码
-d:指明数据库的名字
-c:指明collection的名字
-f:指明要导入那些列
-j, --numInsertionWorkers=<number> number of insert operations to run concurrently (defaults to 1)
//并行
先删除vast中的数据,并验证
app> db.vast.remove({})
然后再导入上面导出的vasts.dat文件中的内容
$ mongoimport -h 192.168.1.21:30000 -uroot -pguo --authenticationDatabase admin -d app -c vast vasts.json
上面演示的是导入JSON格式的文件中的内容,如果要导入CSV格式文件中的内容,则需要通过--type参数指定导入格式,具体如下所示:
先删除数据
app> db.vast.remove({})
再导入之前导出的vast_csv.dat文件
$ mongoimport -h 192.168.1.21:30000 -uroot -pguo --authenticationDatabase admin -d app -c vast --type=csv --headerline --file vast_csv.dat
-headerline:指明第一行是列名,不需要导入。
补:导入CSV文件P_T_HISTXN_20160616.csv(csv文件中没有列明,fields指定列明)
$ tail -5 P_T_HISTXN_20160616.csv
"2015-07-01 00:00:00","154221","11000255653101","2015-07-01 00:00:00","0523753","EB0523753","PAZF00","07010032044026","0305","EB052",,"0305","平安银行北京中关村支行","0305","11000255653101","北京万佳立信科技发展有限公司",,"招商银行股份有限公司北京上地支行","308100005416","6226090110740251","徐雨阳","200000","1","0","RMB",,"D","PAZ15","3090","借款","554345.5","0","WEB","BPAY-UPP",,,"B","ZFA","0000","00000002","Y",,,"2015-07-01 00:00:00","554345.5","554345.5","Y","1",,,,,"WEB","网银","EB","0","Y",,,,"0","0","1","11",,,,"13","11000255653101","N"
"2015-07-01 00:00:00","092012","11000256450102","2015-07-01 00:00:00","0159509","EB0159509","PAZF00","07010031074886","9998","EB015",,,"中国农业银行常州分行营业部","103304061015","6228480419360850277","徐卫","0338","平安银行南京河西支行","9998","11000256450102","江苏宁谊文化实业有限公司","35000","0","0","RMB",,"C","PAZ14","3090","书款","28389004.82","0","Z14",,,,"B","ZFA","0000","00000001","Y",,,"2015-07-01 00:00:00","28389004.82","28389004.82","N","1",,,,,"Z14",,"EB","0",,,,,"0","0","1","11",,,,"17","11000256450102","N"
"2015-07-01 00:00:00","101255","11000256450102","2015-07-01 00:00:00","0224494","EB0224494","PABOCP","07011232352900","0338","EB022",,"0338","平安银行南京河西支行","0338","11000256450102","江苏宁谊文化实业有限公司",,,"000000000000",,"南京银城物业服务有限公司第一分公司","31053","0","0","RMB",,"D","PAZ02","3090",,"28357951.82","0","106542 B08",,,,"B","ZFA","0000","00000002","Y",,,"2015-07-01 00:00:00","28357951.82","28357951.82","Y","1",,,,,"B08","影像票交提回","EB","0",,,"2001","30106542","0","0","0","11",,,,"17","11000256450102","N"
"2015-07-01 00:00:00","102924","11000256450102","2015-07-01 00:00:00","0245050","EB0245050","PAZF00","07010031223297","9998","EB024",,,"中国建设银行湖北省分行","105521000012","42001258139059005570","武汉市汉阳区万科育才幼儿园","0338","平安银行南京河西支行","9998","11000256450102","江苏宁谊文化实业有限公司","14040","0","0","RMB",,"C","PAZ12","3090","货款","28371991.82","0","Z12","BPAY-UPP",,,"B","ZFA","0000","00000003","Y",,,"2015-07-01 00:00:00","28371991.82","28371991.82","N","1",,,,,"Z12",,"EB","0","Y",,,,"0","0","1","11",,,,"17","11000256450102","N"
"2015-07-01 00:00:00","103918","11000256450102","2015-07-01 00:00:00","0256580","EB0256580","PAZF00","07010031248738","9998","EB025",,,"中国农业银行常州分行营业部","103304061015","6228480419360850277"
$ mongoimport -h 192.168.1.21:30000 -uroot -pguo --authenticationDatabase admin --db=test --collection=tx --numInsertionWorkers=4 --type=csv --fields=TDT,TTM,ACC,ADT,TRC,F6,F7,F8,F9,F10,F11,F12,F13,F14,F15,F16,F17,F18,F19,F20,F21,AMT,F23,F24,CCY,F26,F27,F28,F29,F30,F31,F32,F33,F34,F35,F36,F37,F38,F39,SEQ,F41,F42,F43,F44,F45,F46,F47,F48,F49,F50,F51,F52,F53,F54,F55,F56,F57,F58,F59,F60,F61,F62,F63,F64,F65,F66,F67,F68,F69,F70 --file=P_T_HISTXN_20160616.csv
2016-06-16T00:19:43.756+0800 connected to: 192.168.1.24:27017
2016-06-16T00:19:46.725+0800 [##############..........] test.tx 15.0 MB/24.0 MB (62.5%)
2016-06-16T00:19:49.728+0800 [######################..] test.tx 22.4 MB/24.0 MB (93.2%)
2016-06-16T00:19:50.305+0800 [########################] test.tx 24.0 MB/24.0 MB (100.0%)
2016-06-16T00:19:50.305+0800 imported 44727 documents
test> db.tx.findOne()
{
"_id" : ObjectId("576180231e9233e8fdee74c5"),
"TDT" : "2015-07-01 00:00:00",
"TTM" : 172553,
"ACC" : NumberLong("12100050740"),
"ADT" : "2015-07-01 00:00:00",
"TRC" : 634024,
"F6" : "EB0634024",
"F7" : "WB0755",
"F8" : NumberLong("42150701183758"),
"F9" : 852,
"F10" : "EB063",
"F11" : "",
"F12" : "",
"F13" : "平安银行深圳西丽支行",
"F14" : 852,
"F15" : NumberLong("11002902626101"),
"F16" : "深圳市新星轻合金材料股份有限公司",
"F17" : 2101,
"F18" : "平安银行深圳分行营业部",
"F19" : 852,
"F20" : NumberLong("12100050740"),
"F21" : "深圳市建筑工程股份有限公司",
"AMT" : 33000,
"F23" : 0,
"F24" : 0,
"CCY" : "RMB",
"F26" : "",
"F27" : "C",
"F28" : "WBNFE",
"F29" : 1380,
"F30" : "工程款",
"F31" : 6397008.2,
"F32" : 0,
"F33" : "WEB",
"F34" : "ZH",
"F35" : "",
"F36" : "",
"F37" : "B",
"F38" : "CCT",
"F39" : 0,
"SEQ" : 4,
"F41" : "Y",
"F42" : "",
"F43" : "",
"F44" : "2015-07-01 00:00:00",
"F45" : 6397008.2,
"F46" : 6397008.2,
"F47" : "Y",
"F48" : 1,
"F49" : "",
"F50" : "",
"F51" : "",
"F52" : "",
"F53" : "WEB",
"F54" : "网银",
"F55" : "EB",
"F56" : 0,
"F57" : "",
"F58" : "",
"F59" : "",
"F60" : "",
"F61" : 0,
"F62" : 0,
"F63" : 1,
"F64" : 11,
"F65" : "",
"F66" : "",
"F67" : "",
"F68" : 11,
"F69" : NumberLong("12100050740"),
"F70" : "N"
}
mysql导出csv:
select * from test_info
into outfile ‘/tmp/test.csv‘
fields terminated by ‘,‘ ------字段间以,号分隔
optionally enclosed by ‘"‘ ------字段用"号括起
escaped by ‘"‘ ------字段中使用的转义符为"
lines terminated by ‘ ‘; ------行以 结束
mysql导入csv:
load data infile ‘/tmp/test.csv‘
into table test_info
fields terminated by ‘,‘
optionally enclosed by ‘"‘
escaped by ‘"‘
lines terminated by ‘ ‘;
数据迁移思考:
同版本的迁移:5.6----->5.6
例如银行数据迁移
要申请多少停机时间,整体不要超过30分钟
业务不能访问的是哪
1、业务割接的时间(一般不会超过10分钟)
割接时最后那部分binlog的恢复时间(涉及到原服务器的业务停止)
应用ip的切换
2、失败回退时间
应用ip的切换
1、备份时间---------有些情况下要拿出去,比如热备情况。但要考虑存储引擎
2、恢复时间
3、预迁移测试----应用测试服务器,测试迁移数据
windows Linux 上迁移
不能用物理的备份,只能用逻辑
使用mysqldump
采用逻辑备份工具,只要考虑用字符集
5.3 mongodump和mongorestore基本使用
2.1--备份test库
$ mongodump -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -o /mongodb/backup/
2.2--备份test库下的vast集合
$ mongodump -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -c vast -o /mongodb/backup/
2.3 --压缩备份
$ mongodump -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -o /mongodb/backup/ --gzip
$ mongodump -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -c vast -o /mongodb/backup/ --gzip
2.4--恢复test库
$ mongorestore -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test /home/mongod/backup/test/
2.5--恢复test库下的vast集合
$ mongorestore -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -c vast /home/mongod/backup/test/vast.bson
2.6 --drop表示恢复的时候把之前的集合drop掉
$ mongorestore -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test --drop /home/mongod/backup/test/
$ mongorestore -h 10.0.0.52:30000 -uroot -proot --authenticationDatabase admin -d test -c vast --drop /home/mongod/backup/test/vast.bson
5.4 mongodump和mongorestore高级企业应用(--oplog)
在replica set中oplog是一个定容集合(capped collection),它的默认大小是磁盘空间的5%(可以通过--oplogSizeMB参数修改),
位于local库的db.oplog.rs,有兴趣可以看看里面到底有些什么内容。
其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作。
当空间用完时新记录自动覆盖最老的记录。
其覆盖范围被称作oplog时间窗口。需要注意的是,因为oplog是一个定容集合,
所以时间窗口能覆盖的范围会因为你单位时间内的更新次数不同而变化。
想要查看当前的oplog时间窗口预计值,可以使用以下命令:
my_repl:PRIMARY> rs.printReplicationInfo()
configured oplog size: 2048MB -集合大小
log length start to end: 33secs (0.01hrs) 预计窗口覆盖时间
oplog first event time: Fri Dec 01 2017 11:32:27 GMT+0800 (CST)
oplog last event time: Fri Dec 01 2017 11:33:00 GMT+0800 (CST)
now: Fri Dec 01 2017 11:36:23 GMT+0800 (CST)
my_repl:PRIMARY>
查询oplpg内容
my_repl:PRIMARY> use local
switched to db local
my_repl:PRIMARY> db.oplog.rs.find().pretty();
{
"ts" : Timestamp(1512099147, 1),
"h" : NumberLong("-812771544285961575"),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : {
"msg" : "initiating set"
}
}
{
"ts" : Timestamp(1512099158, 1),
"t" : NumberLong(1),
"h" : NumberLong("-4824629711242644273"),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : {
"msg" : "new primary"
}
}
{
"ts" : Timestamp(1512099180, 1),
"t" : NumberLong(1),
"h" : NumberLong("-4053817390792614389"),
"v" : 2,
"op" : "c",
"ns" : "test.$cmd",
"o" : {
"create" : "movies"
}
}
{
"ts" : Timestamp(1512099180, 2),
"t" : NumberLong(1),
"h" : NumberLong("4875797116718103379"),
"v" : 2,
"op" : "i",
"ns" : "test.movies",
"o" : {
"_id" : ObjectId("5a20cd6cdbfd6f9352558b97"),
"title" : "Jaws",
"year" : 1975,
"imdb_rating" : 8.1
}
}
{
"ts" : Timestamp(1512099180, 3),
"t" : NumberLong(1),
"h" : NumberLong("3087947678349584987"),
"v" : 2,
"op" : "i",
"ns" : "test.movies",
"o" : {
"_id" : ObjectId("5a20cd6cdbfd6f9352558b98"),
"title" : "Batman",
"year" : 1989,
"imdb_rating" : 7.6
}
}
5.5 oplog企业级应用
(1)实现热备,在备份时使用--oplog选项
注:为了演示效果我们在备份过程,模拟数据插入
use test
for(var i = 0; i < 1000000; i++) {
db.foo.insert({a: i});
}
备份
mongodump --host 127.0.0.1 --port 27018 --oplog -o /mongodb/bak
作用介绍:--oplog 会记录备份过程中的数据变化。会以oplog.bson保存下来
恢复
mongorestore -h 127.0.0.1 --port 27018 --oplogReplay /mongodb/bak
实例5-1 环境模拟
环境模拟:
1、插入100000行数据,在插入时进行备份
2、误删除一条数据
插入完成之后进行全备然后误删除一条数据
my_repl:PRIMARY> for(var i = 0; i < 1000000; i++) {
... db.foo.insert({a: i});
... }
全备
mongodump --host 127.0.0.1 --port 29018 --oplog -o /mongodb/backup/
use test
db.foo.remove({a:0});
备份
[[email protected] mongodb]$ mongodump --port 29018 --oplog -o /mongodb/backup/
2017-12-01T11:52:52.283+0800 writing test.foo to
2017-12-01T11:52:52.284+0800 writing test.movies to
2017-12-01T11:52:52.313+0800 done dumping test.movies (2 documents)
2017-12-01T11:52:52.475+0800 done dumping test.foo (5425 documents)
2017-12-01T11:52:52.475+0800 writing captured oplog to
2017-12-01T11:52:52.806+0800 dumped 181 oplog entries
[[email protected] mongodb]$
恢复
bsondump oplog.bson | grep ""op":"d"" | head
{"b":true,"h":{"$numberLong":"5331406427126597755"},"ns":"test.foo","o":{"_id":{"$oid":"5602cdf1befd4a4bfb4d149b"}},"op":"d","ts":{"$timestamp":{"t":1443024507,"i":1}},"v":2}
mongorestore -h 127.0.0.1 --port 27018 --oplogReplay --oplogLimit "1511221787:1102" /mongodb/bak/local
第6章 MongoDB监控及优化简介
6.1 MongoDB集群监控重要性
为什么要监控?
监控及时获得应用的运行状态信息,在问题出现时及时发现。
--被动监控、主动监控
--没有监控(不能及时掌握线上应用状况、问题不能及时发现)
监控什么?
?
机器资源
--CPU、内存、磁盘I/O
应用程序(MongoDB)
--进程监控(ps-aux)
--错误日志监控
6.2 MongoDB集群监控方式
db.serverStatus()
--查看实例运行状态(内存使用、锁、用户连接等信息)
--通过比对前后快照进行性能分析
my_repl:PRIMARY> db.serverStatus()
{
"host" : "db02:29018",
"advisoryHostFQDNs" : [ ],
"version" : "3.2.8",
"process" : "mongod",
"pid" : NumberLong(3466),
"uptime" : 20104,
"uptimeMillis" : NumberLong(20103897),
"uptimeEstimate" : 18693,
"localTime" : ISODate("2017-12-01T09:04:48.695Z"),
"asserts" : {
"regular" : 0,
"warning" : 0,
"msg" : 0,
"user" : 0,
"rollovers" : 0
},
"connections" : {
"current" : 10,
"available" : 52418,
"totalCreated" : NumberLong(38)
},
"extra_info" : {
"note" : "fields vary by platform",
"heap_usage_bytes" : 478786944,
//db.serverStatus()重要指标:
?"connections"
?"activeClients"
?"locks"
?"opcounters"
?"opcountersRepl"
?"storageEngine" :查看数据库的存储引擎
?"mem"
my_repl:PRIMARY> db.serverStatus().connections;
{ "current" : 10, "available" : 52418, "totalCreated" : NumberLong(38) }
my_repl:PRIMARY>
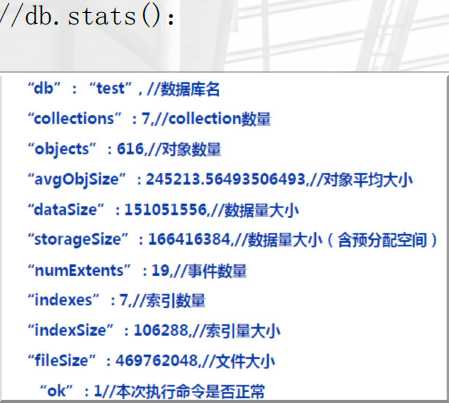
db.stats()
--查看当前数据库状态。
6.2.1 mongostat
--实时数据库状态,读写、加锁、索引命中、缺页中断、读写等待队列等情况。
--每秒刷新一次状态值,并能提供良好的可读性,通过这些参数可以观察到MongoDB系统整体性能情况。
[[email protected] backup]$ mongostat -h 10.0.0.52:29018 --authenticationDatabase admin
insert query update delete getmore command % dirty % used flushes vsize res qr|qw ar|aw netIn netOut conn set repl time
*0 *0 *0 *0 0 3|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 401b 19k 11 my_repl PRI 2017-12-01T17:09:39+08:00
*0 *0 *0 *0 0 1|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 79b 19k 11 my_repl PRI 2017-12-01T17:09:40+08:00
*0 *0 *0 *0 2 5|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 2k 20k 11 my_repl PRI 2017-12-01T17:09:41+08:00
*0 *0 *0 *0 0 1|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 79b 19k 11 my_repl PRI 2017-12-01T17:09:42+08:00
*0 *0 *0 *0 0 3|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 401b 19k 11 my_repl PRI 2017-12-01T17:09:43+08:00
*0 *0 *0 *0 0 1|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 79b 19k 11 my_repl PRI 2017-12-01T17:09:44+08:00
*0 *0 *0 *0 0 3|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 401b 19k 11 my_repl PRI 2017-12-01T17:09:45+08:00
*0 *0 *0 *0 2 3|0 0.0 39.0 0 1.3G 434.0M 0|0 0|0 1k 19k 11 my_repl PRI 2017-12-01T17:09:46+08:00
^C[[email protected] backup]$
//mongostat重要指标:
insert:每秒插入量
query:每秒查询量
update:每秒更新量
delete:每秒删除量
conn:当前连接数
qr|qw:客户端查询排队长度(读|写)
最好为0,如果有堆积,数据库处理慢。
ar|aw:活跃客户端数量(读|写)
time:当前时间
6.2.2 mongotop
--提供结合层的统计信息,默认每秒返回值。
[[email protected] backup]$ mongotop -h 10.0.0.52:29018 --authenticationDatabase admin
2017-12-01T17:13:01.865+0800 connected to: 10.0.0.52:29018
ns total read write 2017-12-01T17:13:03+08:00
local.oplog.rs 1ms 1ms 0ms
admin.system.roles 0ms 0ms 0ms
admin.system.version 0ms 0ms 0ms
local.me 0ms 0ms 0ms
local.replset.election 0ms 0ms 0ms
local.replset.minvalid 0ms 0ms 0ms
local.startup_log 0ms 0ms 0ms
local.system.replset 0ms 0ms 0ms
test.foo 0ms 0ms 0ms
test.movies 0ms 0ms 0ms
?ns:数据库命名空间,后者结合了数据库名称和集合。
?total:mongod在这个命令空间上花费的总时间。
?read:在这个命令空间上mongod执行读操作花费的时间。
?write:在这个命名空间上mongod进行写操作花费的时间。
6.2.3 db.currentOp()
?查看数据库当前执行什么操作。
?用于查看长时间运行进程。
?通过(执行时长、操作、锁、等待锁时长)等条件过滤。
my_repl:PRIMARY> db.currentOp()
{
"inprog" : [
{
"desc" : "conn27",
"threadId" : "140302511118080",
"connectionId" : 27,
"client" : "127.0.0.1:52153",
"active" : true,
"opid" : 6493513,
"secs_running" : 0,
"microsecs_running" : NumberLong(30576),
"op" : "command",
"ns" : "admin.$cmd",
"query" : {
"currentOp" : 1
},
"numYields" : 0,
"locks" : {
},
"waitingForLock" : false,
"lockStats" : {
}
},
{
"desc" : "conn22",
"threadId" : "1403020736
如果发现一个操作太长,把数
据库卡死的话,可以用这个命
令杀死他:
> db.killOp(608605)
6.2.4 db.setProfilingLevel()
--设置server级别慢日志。
{ "was" : 0, "slowms" : 100, "ok" : 1 }
my_repl:PRIMARY> db.getProfilingStatus()
{ "was" : 0, "slowms" : 100 }
my_repl:PRIMARY> db.setProfilingLevel(0,1000)
{ "was" : 0, "slowms" : 100, "ok" : 1 }
my_repl:PRIMARY>
1、打开profiling:0不保存,1保存慢查询日志,2保存所有查询日志
注意级别是对应当前的数据库,而阈值是全局的。
2、查看profiling状态
3、查看慢查询:system.profile
4、关闭profiling my_repl:PRIMARY> db.setProfilingLevel()
6.3 MongoDB集群性能优化方案
l 硬件。。。(内存、SSD)
l 收缩数据
l 增加新的机器、新的副本集
l 集群分片键选择
l chunk大小设置
l 预分片(预先分配存储空间)
1.5.2 存储引擎方面
WiredTiger是3.0以后的默认存储引擎,细粒度的并发控制和数据压缩提供了更高的性能和存储效率。3.0以前默认的MMAPv1也提高了性能。
在MongoDB复制集中可以组合多钟存储引擎,各个实例实现不同的应用需求。
1.5.3 其他优化建议
收缩数据
预分片
增加新的机器、新的副本集
集群分片键选择
chunk大小设置