问题
上传文件到Hadoop异常,报错信息如下:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /home/input/qn_log.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.

解决
1、查看问题节点的进程情况:
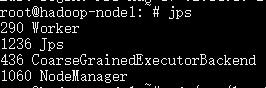
DataNode进程没有启动
2、查看Hadoop datanode.log信息
2018-08-17 05:48:58,076 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/usr/local/hadoop2.7/dfs/data/
java.io.IOException: Incompatible clusterIDs in /usr/local/hadoop2.7/dfs/data: namenode clusterID = CID-e1a65f22-f0f6-4423-8c2b-03edd2f30766; datanode clusterID = CID-647259e5-0250-4676-8327-a09f8ccd38a7
报错的信息为,namenode clusterID 与 datanode clusterID 不一致!
分别为:
namenode clusterID = CID-e1a65f22-f0f6-4423-8c2b-03edd2f30766
datanode clusterID = CID-647259e5-0250-4676-8327-a09f8ccd38a7
回想了下,出现这个问题的原因:在于我在重启Docker容器之后,对HDFS重新做了格式化,导致版本不一致。
3、解决:
方法:将DataNode的版本,修改到与NameNode一致
(1)修改dfs/data/current/VERSION文件中,将clusterID的值,改为与namenode的clusterID的值
(2)重启集群,注意, 勿执行namenode格式化,如下:
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
再查一下节点进程
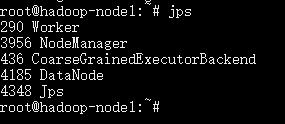
DataNode进程启动起来了!
再试一下上传,也OK了