Hadoop 综合揭秘——MapReduce 编程实例(详细介绍 CombinePartitionerWritableComparableWritableComparator 使用方式)
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 综合揭秘——MapReduce 编程实例(详细介绍 CombinePartitionerWritableComparableWritableComparator 使用方式)相关的知识,希望对你有一定的参考价值。
前言
本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine、Partitioner、WritableComparator等组件对数据进行排序筛选聚合分组的功能。
由于文章是针对开发人员所编写的,在阅读本文前,文章假设读者已经对Hadoop的工作原理、安装过程有一定的了解,因此对Hadoop的安装就不多作说明。请确保源代码运行在Hadoop 2.x以上版本,并以伪分布形式安装以方便进行调试(单机版会对 Partitioner 功能进行限制)。
文章主要利用例子介绍如何利用 MapReduce 模仿 SQL 关系数据库进行SELECT、WHERE、GROUP、JOIN 等操作,并对 GroupingComparator、SortComparator 等功能进行说明。
希望本篇文章能对各位的学习研究有所帮助,当中有所错漏的地方敬请点评。
目录
五、WritableComparatable 自定义键值说明
一、MapReduce 工作原理简介
对Hadoop有兴趣的朋友相信对Hadoop的主要工作原理已经有一定的认识,在讲解MapReduce的程序开发前,本文先针对Mapper、Reducer、Partitioner、Combiner、Suhffle、Sort的工作原理作简单的介绍,以帮助各位更好地了解后面的内容。
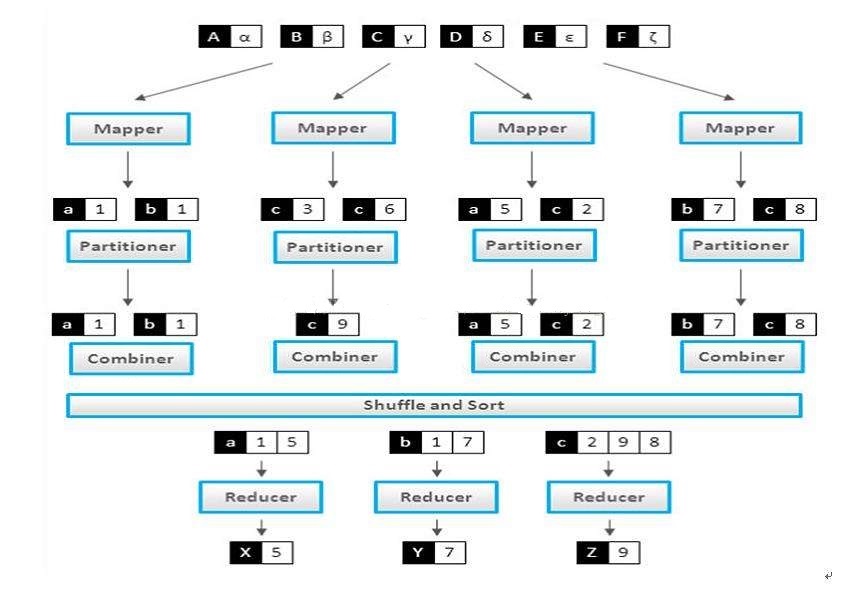
图 1.1
1.1 Mapper 阶段
当系统对数据进行分片后,每个输入分片会分配到一个Mapper任务来处理,默认情况下系统会以HDFS的一个块大小64M作为分片大小,当然也可以通过配置文件设置块的大小。随后Mapper节点输出的数据将保存到一个缓冲区中(缓冲区的大小默认为512M,可通过mapreduce.task.io.sort.mb属性进行修改),缓冲区越大排序效率越高。当该缓冲区快要溢出时(缓冲区默认大小为80%,可通过mapreduce.map.sort.spill.percent属性进行修改),系统会启动一个后台线程,将数据传输到会到本地的一个文件当中。
1.2 Partitioner 阶段
在Mapper完成 KEY/VALUE 格式的数据操作后,Partitioner 将会被调用,由于真实环境中 Hadoop 可能会包含几十个甚至上百个Reducer ,Partitioner 的主要作用就是根据自定义方式确定数据将被传输到哪一个Reducer进行处理。
1.3 Combiner 阶段
如果系统定义了Combiner,在经过 Partitioner 排序处理后将会进行 Combiner处理。我们可以把 Combiner 看作为一个小型的 Reducer ,由于数据从 Mapper 通过网络传送到 Reducer ,资源开销很大,Combiner 目的就是在数据传送到Reducer前作出初步聚集处理,减少服务器的压力。如果数据量太大,还可以把 mapred.compress.map.out 设置为 true,就可以将数据进行压缩。(关于数据压缩的内容已经超越本文的讨论范围,以后会有独立的篇章针对数据压缩进行专题讨论,敬请期待)
1.4 Shuffle 阶段
在 Shuffle 阶段,每个 Reducer 会启动 5 个线程(可通过 mapreduce.reduce.shuffle.parallelcopies 进行设置)通过HTTP协议获取Mapper传送过来的数据。每次数据发送到 Reducer 前,都会根据键先进行排序。开发人员也可通过自定义的 SortComparator 进行数据排序,也是根据 GroupComparator 按照数据的其他特性进行分组处理,下面章节将会详细举例介绍。对数据进行混洗、排序完成后,将传送到对应的Reducer进行处理。
1.5 Reducer 阶段
当 Mapper 实例完成输入的数据超过设定值后(可通过mapreduce.job.reduce.slowstart.completedmaps 进行设置), Reducer 就会开始执行。Reducer 会接收到不同 Mapper 任务传来已经过排序的数据,并通过Iterable 接口进行处理。在 Partitioner 阶段,系统已定义哪些数据将由个 Reducer 进行管理。当 Reducer 检测到 KEY 时发生变化时,系统就会按照已定的规则生成一个新的 Reducer 对数据进行处理。
如果 Reducer 端接受的数据量较小,数据则可直接存储在内存缓冲区中,方便后面的数据输出(缓冲区大小可通过mapred.job.shuffle.input.buffer.percent 进行设置)
如果数据量超过了该缓冲区大小的一定比例(可以通过 mapred.job.shuffle.merge.percent 进行设置),数据将会被合并后写到磁盘中。
二、MapReduce 开发实例
上一章节讲解了 MapReduce 的主要流程,下面将以几个简单的例子模仿 SQL 关系数据库向大家介绍一下 MapReduce 的开发过程。
HDFS常用命令 (此处只介绍几个常用命令,详细内容可在网上查找)
- 创建目录 hdfs dfs -mkdir -p 【Path】
- 复制文件 hdfs dfs -copyFromLocal 【InputPath】【OutputPath】
- 查看目录 hdfs dfs -ls 【Path】
- 运行JAR hadoop jar 【Jar名称】 【Main类全名称】 【InputPath】 【OutputPath】
2.1 使用 SELECT 获取数据
应用场景:假设在 hdfs 文件夹 / input / 20180509 路径的 *.dat 类型文件中存放在着大量不同型号的 iPhone 手机当天在不同地区的销售记录,系统想对这些记录进行统计,计算出不同型号手机的销售总数。
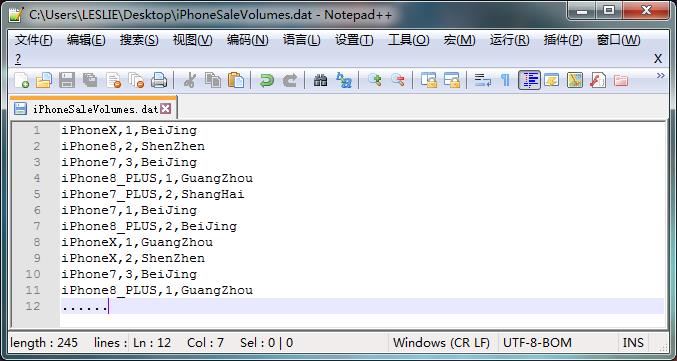
计算时,在Mapper中获取每一行的信息,并把iPhone名称作为Key插入,把数据作为Value插入到Context当中。
当Reducer接收到相同Key数据后,再作统一处理。
注意 : 当前例子当中 Mapper 的输入 Key 为 LongWritable 长类型
在此过程中要注意几点: 例子中 SaleManager 继承了 org.apache.hadoop.conf.Configured 类并实现了 org.apache.hadoop.util.Tool 接口的 public static int run(Configuration conf,Tool tool, String[] args) 方法,MapReduce的相关操作都在run里面实现。由于 Configured 已经实现了 getConf() 与setConfig() 方法,创建Job时相关的配置信息就可通过getConf()方法读入。
系统可以通过以下方法注册Mapper及Reducer处理类
Job.setMapperClass(MyMapper.class);
Job.setReducerClass(MyReducer.class);
在整个运算过程当中,数据会经过筛选与计算,所以Mapper的读入信息K1,V1与Reducer的输出信息K3,V3不一定是同一格式。
org.apache.hadoop.mapreduce.Mapper<K1,V1,K2,V2>
org.apache.hadoop.mapreduce.Reducer<K2,V2,K3,V3>
当Mapper的输出的键值类型与Reduces输出的键值类型相同时,系统可以通过下面方法设置转出数据的格式
Job.setOutputKeyClass(K);
Job.setOutputValueClass(V);
当Mapper的输出的键值类型与Reduces输出的键值类型不相同时,系统则需要通过下面方法设置Mapper转出格式
Job.setMapOutputKeyClass(K);
Job.setMapOutputValueClass(V);
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString(); 9 this.count=Integer.valueOf(data[1].toString()); 10 this.area=data[2].toString(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class SaleManager extends Configured implements Tool{ 27 public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 28 public void map(LongWritable key,Text value,Context context) 29 throws IOException,InterruptedException{ 30 String data=value.toString(); 31 Phone iPhone=new Phone(data); 32 //以iPhone型号作为Key,数量为作Value传入 33 context.write(new Text(iPhone.getType()), new IntWritable(iPhone.getCount())); 34 } 35 } 36 37 public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ 38 public void reduce(Text key,Iterable<IntWritable> values,Context context) 39 throws IOException,InterruptedException{ 40 int sum=0; 41 //对同一型号的iPhone数量进行统计 42 for(IntWritable val : values){ 43 sum+=val.get(); 44 } 45 context.write(key, new IntWritable(sum)); 46 } 47 } 48 49 public int run(String[] arg0) throws Exception { 50 // TODO 自动生成的方法存根 51 // TODO Auto-generated method stub 52 Job job=Job.getInstance(getConf()); 53 job.setJarByClass(SaleManager.class); 54 //注册Key/Value类型为Text 55 job.setOutputKeyClass(Text.class); 56 job.setOutputValueClass(IntWritable.class); 57 //注册Mapper及Reducer处理类 58 job.setMapperClass(MyMapper.class); 59 job.setReducerClass(MyReducer.class); 60 //输入输出数据格式化类型为TextInputFormat 61 job.setInputFormatClass(TextInputFormat.class); 62 job.setOutputFormatClass(TextOutputFormat.class); 63 //默认情况下Reducer数量为1个(可忽略) 64 job.setNumReduceTasks(1); 65 //获取命令参数 66 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 67 //设置读入文件路径 68 FileInputFormat.setInputPaths(job,new Path(args[0])); 69 //设置转出文件路径 70 FileOutputFormat.setOutputPath(job,new Path(args[1])); 71 boolean status=job.waitForCompletion(true); 72 if(status) 73 return 0; 74 else 75 return 1; 76 } 77 78 public static void main(String[] args) throws Exception{ 79 Configuration conf=new Configuration(); 80 ToolRunner.run(new SaleManager(), args); 81 } 82 }
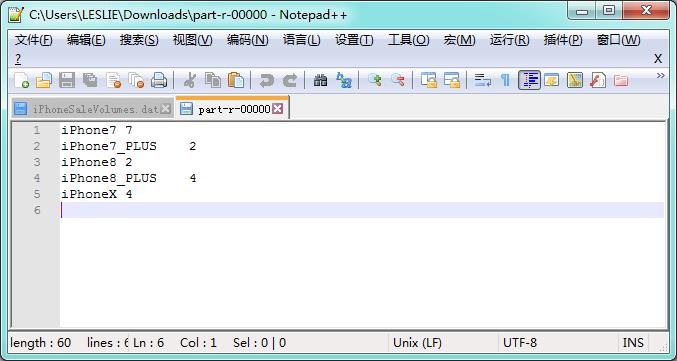
计算结果
2.2 使用 WHERE 对数据进行筛选
在计算过程中,并非所有的数据都适用于Reduce的计算,由于海量数据是通过网络传输的,所消耗的 I/O 资源巨大,所以可以尝试在Mapper过程中提前对数据进行筛选。以上面的数据为例,当前系统只需要计算输入参数地区的销售数据。此时只需要修改一下Mapper类,重写setup方法,通过Configuration类的 public String[] Configuration.getStrings(参数名,默认值) 方法获取命令输入的参数,再对数据进行筛选。
1 public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 2 private String area; 3 4 @Override 5 public void setup(Context context){ 6 this.area=context.getConfiguration().getStrings("area", "BeiJing")[0]; 7 } 8 9 public void map(LongWritable key,Text value,Context context) 10 throws IOException,InterruptedException{ 11 String data=value.toString(); 12 Phone iPhone=new Phone(data); 13 if(this.area.equals(iPhone.area)) 14 context.write(new Text(iPhone.getType()), new IntWritable(iPhone.getCount())); 15 } 16 }
执行命令 hadoop jar 【Jar名称】 【Main类全名称】-D 【参数名=参数值】 【InputPath】 【OutputPath】
例如:hadoop jar hadoopTest-0.2.jar sun.hadoopTest.SaleManager -D area=BeiJing /tmp/input/050901 /tmp/output/050901
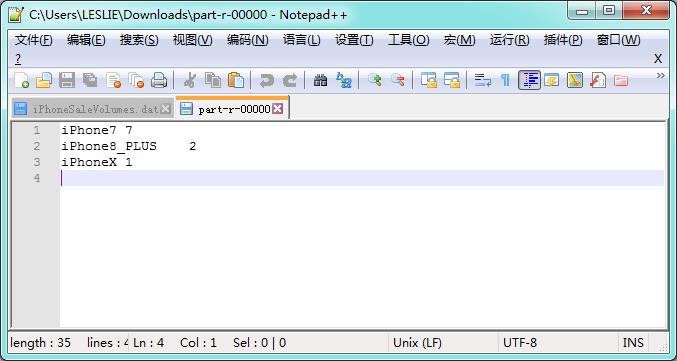
此时系统将选择 area 等于BeiJing 的数据进行统计
计算结果
三、利用 Partitioner 控制键值分配
3.1 深入分析 Partitioner
Partitioner 类在 org.apache.hadoop.mapreduce.Partitioner 中,通过 Job.setPartitionerClass(Class<? extends Partitioner> cls) 方法可绑定自定义的 Partitioner。若用户没有实现自定义Partitioner 时,系统将自动绑定 Hadoop 的默认类 org.apache.hadoop.mapreduce.lib.partiton.HashPartitioner 。Partitioner 包含一个主要方法是 int getPartition(K key,V value,int numReduceTasks) ,功能是控制将哪些键分配到哪个 Reducer。此方法的返回值是 Reducer 的索引值,若系统定义了4个Reducer,其返回值为0~3。numReduceTasks 侧是当前系统的 Reducer 数量,此数量可通过Job.setNumReduceTasks(int tasks) 进行设置,在伪分布环境下,其默认值为1。
注意:
在单机环境下,系统只会使用一个 Reducer,这将导致 Partitioner 缺乏意义,这也是在本文引言中强调要使用伪分布环境进行调试的原因 。
通过反编译查看 HashPartitioner ,可见系统是通过(key.hashCode() & Interger.MAX_VALUE )%numReduceTasks 方法,根据 KEY 的 HashCode 对 Reducer 数量求余方式,确定数据分配到哪一个 Reducer 进行处理的。但如果想根据用户自定义的逻辑把数据分配到对应 Reducer,单依靠 HashPartitioner 是无法实现的,此时侧需要自定义 Partitioner 。
1 public class HashPartitioner<K, V> extends Partitioner<K, V> { 2 3 public int getPartition(K key, V value, int numReduceTasks) { 4 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; 5 } 6 }
3.2 自定义 Partitioner
在例子当中,假设系统需要把北、上、广、深4个不同的地区的iPhone销售情况分别交付给不同 Reducer 进行统计处理。我们可以自定义一个 MyPartitioner, 通过 Job.setPartitionerClass( MyPartitioner.class ) 进行绑定。通过 Job.setNumReduceTasks(4) 设置4个Reducer 。以手机类型作为KEY,把销售数据与地区作为VALUE。在 int getPartition(K key,V value,int numReduceTasks) 方法中,根据 VALUE 值的不同返回不同的索引值。
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString(); 9 this.count=Integer.valueOf(data[1].toString()); 10 this.area=data[2].toString(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class MyPatitional extends Partitioner<Text,Text> { 27 28 @Override 29 public int getPartition(Text arg0, Text arg1, int arg2) { 30 // TODO 自动生成的方法存根 31 String area=arg1.toString().split(",")[0]; 32 // 根据不同的地区返回不同的索引值 33 if(area.contentEquals("BeiJing")) 34 return 0; 35 if(area.contentEquals("GuangZhou")) 36 return 1; 37 if(area.contentEquals("ShenZhen")) 38 return 2; 39 if(area.contentEquals("ShangHai")) 40 return 3; 41 return 0; 42 } 43 } 44 45 public class SaleManager extends Configured implements Tool{ 46 public static class MyMapper extends Mapper<LongWritable,Text,Text,Text>{ 47 48 public void map(LongWritable key,Text value,Context context) 49 throws IOException,InterruptedException{ 50 String data=value.toString(); 51 Phone iPhone=new Phone(data); 52 context.write(new Text(iPhone.getType()), new Text(iPhone.getArea()+","+iPhone.getCount().toString())); 53 } 54 } 55 56 public static class MyReducer extends Reducer<Text,Text,Text,IntWritable>{ 57 58 public void reduce(Text key,Iterable<Text> values,Context context) 59 throws IOException,InterruptedException{ 60 int sum=0; 61 //对同一型号的iPhone数量进行统计 62 for(Text value : values){ 63 String count=value.toString().split(",")[1]; 64 sum+=Integer.valueOf(count).intValue(); 65 } 66 context.write(key, new IntWritable(sum)); 67 } 68 } 69 70 public int run(String[] arg0) throws Exception { 71 // TODO 自动生成的方法存根 72 // TODO Auto-generated method stub 73 Job job=Job.getInstance(getConf()); 74 job.setJarByClass(SaleManager.class); 75 //注册Key/Value类型为Text 76 job.setOutputKeyClass(Text.class); 77 job.setOutputValueClass(IntWritable.class); 78 //若Map的转出Key/Value不相同是需要分别注册 79 job.setMapOutputKeyClass(Text.class); 80 job.setMapOutputValueClass(Text.class); 81 //注册Mapper及Reducer处理类 82 job.setMapperClass(MyMapper.class); 83 job.setReducerClass(MyReducer.class); 84 //输入输出数据格式化类型为TextInputFormat 85 job.setInputFormatClass(TextInputFormat.class); 86 job.setOutputFormatClass(TextOutputFormat.class); 87 //设置Reduce数量为4个,伪分布式情况下不设置时默认为1 88 job.setNumReduceTasks(4); 89 //注册自定义Partitional类 90 job.setPartitionerClass(MyPatitional.class); 91 //获取命令参数 92 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 93 //设置读入文件路径 94 FileInputFormat.setInputPaths(job,new Path(args[0])); 95 //设置转出文件路径 96 FileOutputFormat.setOutputPath(job,new Path(args[1])); 97 boolean status=job.waitForCompletion(true); 98 if(status) 99 return 0; 100 else 101 return 1; 102 } 103 104 public static void main(String[] args) throws Exception{ 105 Configuration conf=new Configuration(); 106 ToolRunner.run(new SaleManager(), args); 107 } 108 }
计算结果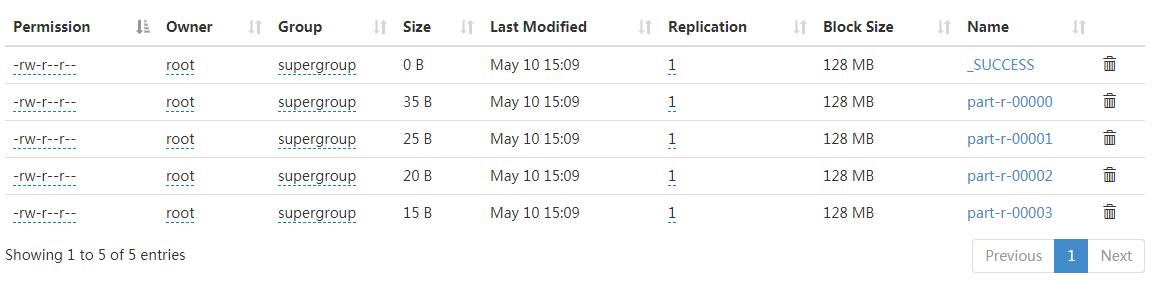
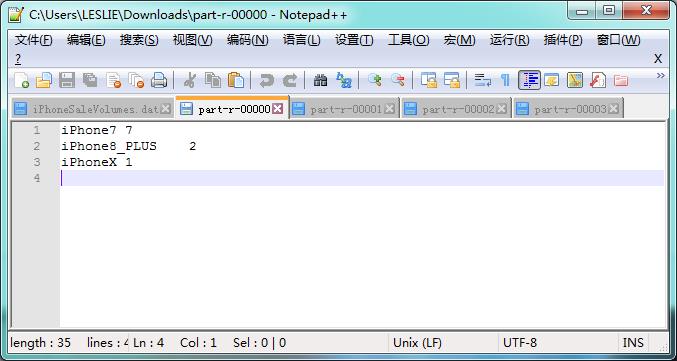
四、利用 Combiner 提高系统性能
在前面几节所描述的例子当中,我们都是把所有的数据完整发送到 Reducer 中再作统计。试想一下,在真实环境当中,iPhone 的销售记录数以千万计,如此巨大的数据需要在 Mapper/Reducer 当中进行传输,将会耗费多少的网络资源。这么多年来 iPhone 出品的机型不过十多个,系统能否先针对同类的机型在Mapper端作出初步的聚合计算,再把计算结果发送到 Reducer。如此一来,传到 Reducer 端的数据量将会大大减少,只要在适当的情形下使用将有利于系统的性能提升。
针对此类问题,Combiner 应运而生,我们可以把 Combiner 看作为一个小型的 Reducer ,它的目的就是在数据传送到Reducer前在Mapper中作出初步聚集处理,减少服务器之间的 I/O 数据传输压力。Combiner 也继承于Reducer,通过Job.setCombinerClass(Class<? extends Reducer> cls) 方法进行注册。
下面继续以第3节的例子作为参考,系统想要在同一个Reducer中计算所有地区不同型号手机的销售情况。我们可以把地区名作为KEY,把销售数量和手机类型转换成 MapWritable 作为 VALUE。当数据输入后,不是直接把数据传输到 Reducer ,而是通过Combiner 把Mapper中不同的型号手机的销售数量进行聚合计算,把5种型号手机的销售总数算好后传输给Reducer。在Reducer中再把来源于不同 Combiner 的数据进行求和,得出最后结果。
注意 :
MapWritable 是 系统自带的 Writable 集合类中的其中一个,它实现了 java.util.Map<Writable,Writable> 接口,以单字节充当类型数据的索引,常用于枚举集合的元素。
1 public class SaleManager extends Configured implements Tool{ 2 private static IntWritable TYPE=new IntWritable(0); 3 private static IntWritable VALUE=new IntWritable(1); 4 private static IntWritable IPHONE7=new IntWritable(2); 5 private static IntWritable IPHONE7_PLUS=new IntWritable(3); 6 private static IntWritable IPHONE8=new IntWritable(4); 7 private static IntWritable IPHONE8_PLUS=new IntWritable(5); 8 private static IntWritable IPHONEX=new IntWritable(6); 9 10 public static class MyMapper extends Mapper<LongWritable,Text,Text,MapWritable>{ 11 12 public void map(LongWritable key,Text value,Context context) 13 throws IOException,InterruptedException{ 14 String data=value.toString(); 15 Phone iPhone=new Phone(data); 16 context.write(new Text(iPhone.getArea()), getMapWritable(iPhone.getType(), iPhone.getCount())); 17 } 18 19 private MapWritable getMapWritable(String type,Integer count){ 20 Text _type=new Text(type); 21 Text _count=new Text(count.toString()); 22 MapWritable mapWritable=new MapWritable(); 23 mapWritable.put(TYPE,_type); 24 mapWritable.put(VALUE,_count); 25 return mapWritable; 26 } 27 } 28 29 public static class MyCombiner extends Reducer<Text,MapWritable,Text,MapWritable> { 30 public void reduce(Text key,Iterable<MapWritable> values,Context context) 31 throws IOException, InterruptedException{ 32 int iPhone7=0; 33 int iPhone7_PLUS=0; 34 int iPhone8=0; 35 int iPhone8_PLUS=0; 36 int iPhoneX=0; 37 //对同一个Mapper所处理的不同型号的手机数据进行初步统计 38 for(MapWritable value:values){ 39 String type=value.get(TYPE).toString(); 40 Integer count=Integer.valueOf(value.get(VALUE).toString()); 41 if(type.contentEquals("iPhone7")) 42 iPhone7+=count; 43 if(type.contentEquals("iPhone7_PLUS")) 44 iPhone7_PLUS+=count; 45 if(type.contentEquals("iPhone8")) 46 iPhone8+=count; 47 if(type.contentEquals("iPhone8_PLUS")) 48 iPhone8_PLUS+=count; 49 if(type.contentEquals("iPhoneX")) 50 iPhoneX+=count; 51 } 52 MapWritable mapWritable=new MapWritable(); 53 mapWritable.put(IPHONE7, new IntWritable(iPhone7)); 54 mapWritable.put(IPHONE7_PLUS, new IntWritable(iPhone7_PLUS)); 55 mapWritable.put(IPHONE8, new IntWritable(iPhone8)); 56 mapWritable.put(IPHONE8_PLUS, new IntWritable(iPhone8_PLUS)); 57 mapWritable.put(IPHONEX, new IntWritable(iPhoneX)); 58 context.write(key,mapWritable); 59 } 60 } 61 62 public static class MyReducer extends Reducer<Text,MapWritable,Text,Text>{ 63 public void reduce(Text key,Iterable<MapWritable> values,Context context) 64 throws IOException,Interrupted以上是关于Hadoop 综合揭秘——MapReduce 编程实例(详细介绍 CombinePartitionerWritableComparableWritableComparator 使用方式)的主要内容,如果未能解决你的问题,请参考以下文章