实际案例告诉你为什么Oracle不建议使用varchar2来存时间数据
Posted lYong90
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实际案例告诉你为什么Oracle不建议使用varchar2来存时间数据相关的知识,希望对你有一定的参考价值。
问题现象
2015年9月客户系统中一条高逻辑读的SQL语句,在业务高峰期执行频率较高,导致系统逻辑读居高不下,同时带高了系统CPU,SQL语句主体部分如下
SELECT /* ^^*/ COUNT(DISTINCT ts_map.draftid) AS recordCount FROM usr.BillStateMap ts_map INNER JOIN usr.create ts_create ON ts_create.draftid = ts_map.draftid LEFT JOIN usr.search ts_search ON ts_create.draftid = ts_search.draftid LEFT JOIN usr.accept accept ON ts_create.draftid = accept.draftid LEFT JOIN usr.kfvistirecord ts_kfback ON ts_kfback.draftid = ts_create.draftid LEFT JOIN (SELECT DISTINCT .. .. .. . FROM usr.create_user t_user) ts_user ON ts_create.draftid = ts_user.creatinfoid WHERE 1 = 1 AND (ts_create.location = \'0579\' OR ts_user.location = \'0579\') AND ts_create.CREATETIME >= \'2015-06-23 00:00:00\' AND ts_create.CREATETIME <= \'2015-09-21 23:59:59\' AND ts_map.billstate = \'待报结\' ORDER BY ts_create.draftId DESC;

通过SQL语句的过滤谓词来确定SQL的过滤情况

通过执行计划可以看出SQL语句走的驱动表是usr.create,但通过过滤谓词检查的结果可以看出实际驱动表应该是usr.BillStateMap
进一步检查SQL语句相关表的索引(检查统计信息是最新收集的,排除统计信息不准的问题)

原因分析:
在此我们回顾下Oracle执行计划走NESTED LOOPS时的一些条件
1、过滤后的小表作为驱动表,大表作为被驱动表,表的大小由CBO评估后计算得到的。
2、被驱动表关联列需要有索引,这条SQL的关联列是DRAFTID,
通过上述索引的查询可以排除第二个条件,两个表上关联列上均有索引,所以当前SQL语句走错驱动表应该是CBO计算过滤后返回行出现错误导致的
检查BILLSTATEMAP表的BILLSTATE是否存在直方图
SQL> SELECT OWNER, TABLE_NAME, COLUMN_NAME, HISTOGRAM 2 FROM DBA_TAB_COLUMNS 3 WHERE TABLE_NAME = \'BILLSTATEMAP\' 4 AND HISTOGRAM <> \'NONE\'; OWNER TABLE_NAME COLUMN_NAME HISTOGRAM -------------------- ------------------------------ ------------------------------ --------------- NETFORCE BILLSTATEMAP BILLSTATE FREQUENCY
可以看出虽然BILLSTATE字段上存在数据选择性不佳,切存在数据倾斜,但是该字段上存在直方图,并不会导致CBO在计算谓词过滤的时候出现错误,所以最终焦点确定在了create表上,为什么实际上create表过滤后有358760行,CBO任然选择他作为驱动表?
作为CBO的正常行为,通过计算后确定过滤后的行数少,即可作为驱动表, 基于成本计算来确定驱动表和被驱动表。 尝试使用hint来指定SQL语句的驱动表/*+ use_nl(ts_map,ts_create) leading(ts_map) */,得到执行计划如下
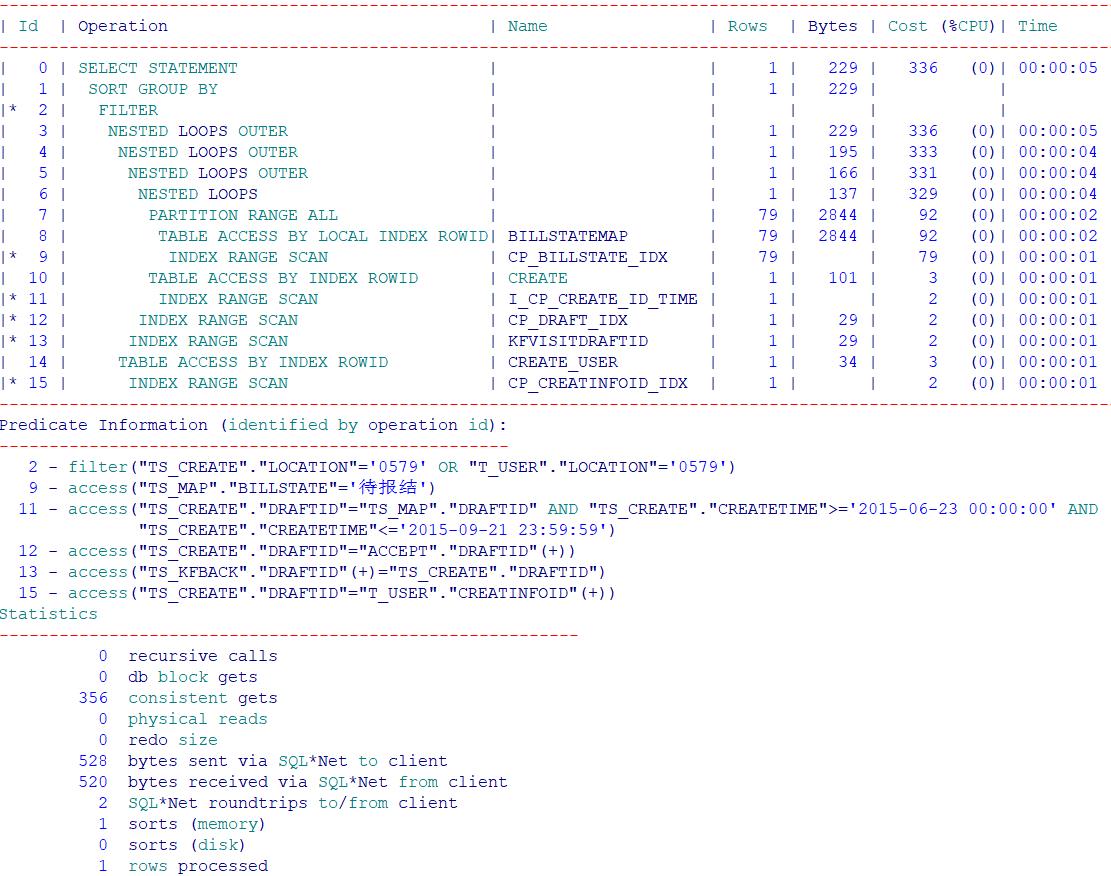
可以看出SQL的执行计划比较完美了,逻辑读大幅下降,再次看下create表在内存中的执行计划,可以发现E-Rows和A-Rows相差好几个数量级, E-Rows:代表着CBO评估的返回行数 A-Rows:代表SQL语句实际返回的行数
SQL> SELECT COUNT(*) 2 FROM CREATE ts_create 3 WHERE ts_create.CREATETIME >= \'2015-06-23 00:00:00\' 4 AND ts_create.CREATETIME <= \'2015-09-21 23:59:59\'; COUNT(*) ---------- 358760 Elapsed: 00:00:00.31 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.31 | 19571 | | 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.31 | 19571 | |* 2 | TABLE ACCESS FULL| TAB_CREATE | 1 | 1 | 358K|00:00:00.25 | 19571 | -------------------------------------------------------------------------------------------
可以确定SQL语句走错驱动表根本原因是CBO评估出错误的返回行,导致驱动表走错,但是为什么会计算错误? 回顾下CBO在计算选择率的公式如下,在没有直方图统计信息足够新的情况下
"col BETWEEN val1 AND val2"的选择率计算如下 Sel = ((val2 - val1) / (high_value - low_value) + (2 / NDV)) * A4Nulls 注: high_value 代表过滤列col的最大值 low_value 代表过滤列col的最小值 NDV 代表数据列的非重复值数量,即distinct_key A4Nulls 代表该字段的非空率
CBO的rows是通过选择率计算出来的,所以选择率的计算直接影响着rows的结果
在统计信息准确的情况下,NDV、A4Nulls、high_value、low_value都是定值并且认为是准确的,在此条件下影响选择率的计算就只有val1和val2(即上述业务SQL在ts_create.CREATETIME上的过滤谓词)
AND ts_create.CREATETIME >= \'2015-06-23 00:00:00\'
AND ts_create.CREATETIME <= \'2015-09-21 23:59:59\'
在此回头查看SQL语句执行计划Predicate Information部分可以看出ts_create.CREATETIME字段上没有进行to_date隐式转换,也就是说ts_create.CREATETIME字段本身就是varchar2类型的,是否是由于varchar2类型的数据进行大小判断导致的呢? 做了如下实验: 创建相同数据的两张表TAB_CREATE1和TAB_CREATE2,字段CREATETIME数据类型分别为varchar2和date,相关表查询通过CREATETIME字段过滤后的执行计划如下
SQL> SELECT COUNT(*) 2 FROM TAB_CREATE1 ts_create 3 WHERE ts_create.CREATETIME >= \'2015-06-23 00:00:00\' 4 AND ts_create.CREATETIME <= \'2015-09-21 23:59:59\'; COUNT(*) ---------- 358760 -------varchar2类型的存放时间的情况下E-Rows和A-Rows相差好几个数量级 Elapsed: 00:00:00.31 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.31 | 19571 | | 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.31 | 19571 | |* 2 | TABLE ACCESS FULL| TAB_CREATE1| 1 | 1 | 358K|00:00:00.25 | 19571 | ------------------------------------------------------------------------------------------- ---date类型的存放时间的情况下E-Rows和A-Rows 在一个数量级了 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.27 | 19571 | | 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.27 | 19571 | |* 2 | TABLE ACCESS FULL| TAB_CREATE2| 1 | 156K| 358K|00:00:00.22 | 19571 | -------------------------------------------------------------------------------------------
到这里问题就进一步明确了,是由于用varchar2类型存放数据导致的问题。 那么又有疑问了,Oracle在CBO是如何处理字符串大小比较的呢?其实没有那么复杂,CBO会先将varchar2数据转换统一转换为raw数据后再做大小比较
继续进行实验,生成测试数据
-----创建个测试表 create table tab_yong as select rownum as id, to_char(to_date(\'2015-01-01 00:00:00\',\'yyyy-mm-dd hh24:mi:ss\') + (rownum*133)/24/3600, \'yyyy-mm-dd hh24:mi:ss\') as c_date, (to_date(\'2015-01-01 00:00:00\',\'yyyy-mm-dd hh24:mi:ss\') + (rownum*133)/24/3600) as d_date, dbms_random.string(\'x\', 20) random_string from dual connect by level <= 1500000; -----收集表的统计信息 SQL> DECLARE 2 BEGIN 3 DBMS_STATS.GATHER_TABLE_STATS(ownname => \'YONG\', 4 tabname => \'TAB_YONG\', 5 estimate_percent => 100, 6 method_opt =>\'for all columns size repeat\', 7 no_invalidate => FALSE, cascade => TRUE, 8 degree => 16); 9 END; 10 / PL/SQL procedure successfully completed. Elapsed: 00:00:15.07
测试表统计信息如下
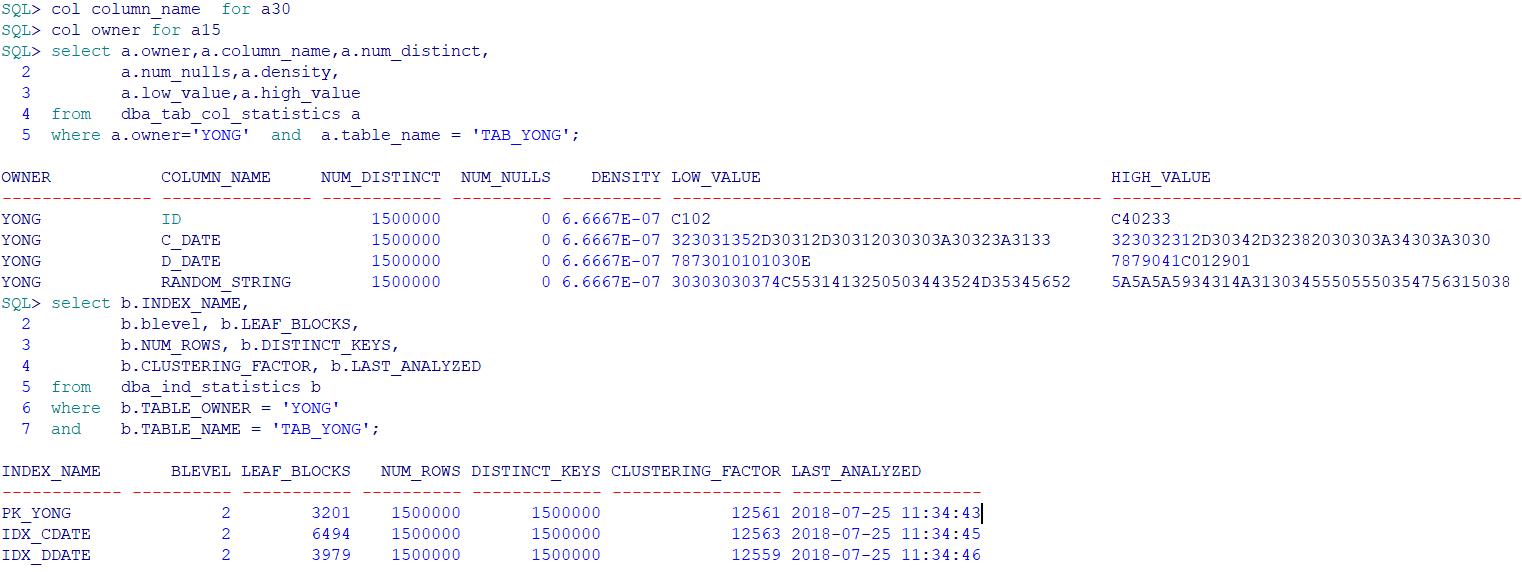
使用varchar2 字段的SQL语句执行计划
SQL> select * 2 from TAB_YONG b 3 where b.c_date >= \'2015-06-23 00:00:00\' 4 and b.c_date <= \'2015-09-21 23:59:59\'; 59116 rows selected. Elapsed: 00:00:00.53 Execution Plan ---------------------------------------------------------- Plan hash value: 4254277647 ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 54 | 4 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| TAB_YONG | 1 | 54 | 4 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | IDX_CDATE | 1 | | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("B"."C_DATE">=\'2015-06-23 00:00:00\' AND "B"."C_DATE"<=\'2015-09-21 23:59:59\')
使用date类型的SQL语句执行计划
SQL> select * 2 from TAB_YONG b 3 where b.d_date >= TO_DATE(\'2015-06-23 00:00:00\') 4 and b.d_date <= TO_DATE(\'2015-09-21 23:59:59\'); 59116 rows selected. Elapsed: 00:00:00.53 Execution Plan ---------------------------------------------------------- Plan hash value: 1934174936 ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 59118 | 3117K| 655 (1)| 00:00:08 | | 1 | TABLE ACCESS BY INDEX ROWID| TAB_YONG | 59118 | 3117K| 655 (1)| 00:00:08 | |* 2 | INDEX RANGE SCAN | IDX_DDATE | 59118 | | 159 (0)| 00:00:02 | ----------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("B"."D_DATE">=TO_DATE(\' 2015-06-23 00:00:00\', \'syyyy-mm-dd hh24:mi:ss\') AND "B"."D_DATE"<=TO_DATE(\' 2015-09-21 23:59:59\', \'syyyy-mm-dd hh24:mi:ss\'))
通过上述执行计划可以看出来,使用varchar2类型的CBO评估出来的rows是1行,而date评估出来的行数是59118行,与实际的59116行一致
转换也没有想象中的复杂,通过下面的函数就可以进行varchar2转换到raw,具体函数代码详见本文结尾
通过上述函数我们计算下问题SQL的时间过滤谓词值
SQL> col var_raw for a40 SQL> select get_internal_value(\'2015-06-23 00:00:00\') var_raw from dual; VAR_RAW ---------------------------------------- 260592297225015000000000000000000000 SQL> col var_raw for a40 SQL> select get_internal_value(\'2015-09-21 23:59:59\') var_raw from dual; VAR_RAW ---------------------------------------- 260592297225015000000000000000000000
计算结果可以看出两个值是相等的,也就是说CBO通过计算后认为下列的条件是等价的
AND ts_create.CREATETIME >= \'2015-06-23 00:00:00\' AND ts_create.CREATETIME <= \'2015-09-21 23:59:59\' CBO层面等价于下列条件 AND ts_create.CREATETIME = \'2015-09-21 23:59:59\'
而等值条件的选择率计算公式如下:
Sel = (1 / NDV) * A4Nulls
带入统计信息分别计算下两个选择率的值及E-rows
----等值情况下 Sel = (1 / NDV) * A4Nulls =(1/1500000) * (1500000-0)/1500000=1/1500000 rows=Sel * NumRows=1/1500000 * 1500000=1 注: NumRows =dba_tables.num_rows 表示全表的行数 -----实际between情况下 Sel = ((val2 - val1) / (high_value - low_value) + (2 / NDV)) * A4Nulls =((to_date(\'2015-09-21 23:59:59\', \'yyyy-mm-dd hh24:mi:ss\') - to_date(\'2015-06-23 00:00:00\', \'yyyy-mm-dd hh24:mi:ss\')) / (to_date(\'2021-04-28 00:40:00\', \'yyyy-mm-dd hh24:mi:ss\') - to_date(\'2015-01-01 00:02:13\', \'yyyy-mm-dd hh24:mi:ss\')) + (2 / 1500000)) * 1 =0.0394118809102899 rows=Sel * NumRows=0.0394118809102899 * 1500000=59117.8213654348≈59118 与上述执行计中CBO计算的一致
OK,到此问题就明朗了,Oracle在CBO计算varchar比较关系的时候会将varchar数据通过计算得出raw值,通过raw来进行比较计算,并依此来计算选择率。
以上是关于实际案例告诉你为什么Oracle不建议使用varchar2来存时间数据的主要内容,如果未能解决你的问题,请参考以下文章