python3_原生 LRU 缓存
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3_原生 LRU 缓存相关的知识,希望对你有一定的参考价值。
参考技术A 原生 LRU 缓存(最低 Python 版本为 3.2)目前,几乎所有层面上的软件和硬件中都需要缓存。Python 3 将 LRU(最近最少使用算法)缓存作为一个名为「lru_cache」的装饰器,使得对缓存的使用非常简单。
下面是一个简单的斐波那契函数,我们知道使用缓存将有助于该函数的计算,因为它会通过递归多次执行相同的工作。
现在,我们可以使用「lru_cache」来优化它(这种优化技术被称为「memoization」)。通过这种优化,我们将执行时间从几十秒降低到了几秒。
Python之使用LRU缓存策略进行缓存
一、Python 缓存
① 缓存作用
- 缓存是一种优化技术,可以在应用程序中使用它来将最近或经常使用的数据保存在内存中,通过这种方式来访问数据的速度比直接读取磁盘文件的高很多。
- 假设我们搭建了一个新闻聚合网站,类似于 Feedly,其获取不同来源的新闻然后聚合展示。当用户浏览新闻的时候,后台程序会将文章下载然后显示到用户屏幕上。如果不使用缓存技术的话,当用户多次切换浏览相同文章的时候,必须多次下载,效率低下且很不友好。
- 更好的做法就是在获取每篇文章之后,在本地进行内容的存储,比如存储在数据库中;然后,当用户下次打开同一篇文章的时候,后台程序可以从本地存储打开内容,而不是再次下载源文件,即这种技术称为缓存。
② 使用 Python 字典实现缓存
- 以新闻聚合网站为例,不必每次都去下载文章内容,而是先检查缓存数据中是否存在对应的内容,只有当没有时,才会让服务器下载文章。
- 如下的示例程序,就是使用 Python 字典实现缓存的,将文章的 URL 作为键,并将其内容作为值;执行之后,可以看到当第二次执行 get_article 函数的时候,直接就返回结果并没有让服务器下载:
import requests
cache = dict()
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def get_article(url):
print("Getting article...")
if url not in cache:
cache[url] = get_article_from_server(url)
return cache[url]
get_article("https://www.escapelife.site/love-python.html")
get_article("https://www.escapelife.site/love-python.html")
- 将此代码保存到一个 caching.py 文件中,安装 requests 库,然后运行脚本:
# 安装依赖
$ pip install requests
# 执行脚本
$ python python_caching.py
Getting article...
Fetching article from server...
Getting article...
- 尽管调用 get_article() 两次(第 17 行和第 18 行)字符串“Fetching article from server…”,但仍然只输出一次。发生这种情况的原因是,在第一次访问文章之后,将其 URL 和内容放入缓存字典中,第二次时代码不需要再次从服务器获取项目。
③ 使用字典来做缓存的弊端
- 上面这种缓存实现存在一个非常大的问题,那就是字典的内容将会无限增长,即大量用户连续浏览文章的时候,后台程序将不断向字典中塞入需要存储的内容,服务器内存被挤爆,最终导致应用程序崩溃。
- 要解决上述这个问题,就需要有一种策略来决定哪些文章应该留在内存中,哪些文章应该被删除掉,这些缓存策略其实是一些算法,它们用于管理缓存的信息,并选择丢弃哪些项以为新项腾出空间。
- 当然这里不必去实现管理缓存的算法,只需要使用不同的策略来从缓存中移除项,并防止其增长超过其最大大小。五种常见的缓存算法如下所示:
| 缓存策略 | 英文名称 | 淘汰条件 | 在什么时候最有用 |
|---|---|---|---|
| 先进先出算法(FIFO) | First-In/First-Out | 淘汰最旧的条目 | 较新的条目最有可能被重用 |
| 后进先出算法(LIFO) | Last-In/First-Out | 淘汰最新的条目 | 较旧的条目最有可能被重用 |
| 最近最少使用算法(LRU) | Least Recently Used | 淘汰最近使用最少的条目 | 最近使用的条目最有可能被重用 |
| 最近最多使用算法(MRU) | Most Recently Used | 淘汰最近使用最多的条目 | 最近不用的条目最有可能被重用 |
| 最近最少命中算法(LFU) | Least Frequently Used | 淘汰最不经常访问的条目 | 命中率很高的条目更有可能被重用 |
- 看了上述五种缓存算法,是不是看到 LRU 和 LFU 的时候有点懵,主要是通过中文对应的解释很难理解其真实的含义,看看英文的话就不难理解了。LRU 和 LFU 算法的不同之处在于:
-
- LRU 基于访问时间的淘汰规则,根据数据的历史访问记录来进行淘汰数据,如果数据最近被访问过,那么将来被访问的几率也更高;
-
- LFU 基于访问次数的淘汰规则,根据数据的历史访问频率来淘汰数据,如果数据过去被访问多次,那么将来被访问的频率也更高;
- 比如,以十分钟为一个节点,每分钟进行一次页面调度,当所需的页面走向为 2 1 2 4 2 3 4 时,且调页面 4 时会发生缺页中断;若按 LRU 算法的话,应换页面 1(十分钟内页面 1 最久未被使用),但按 LFU 算法的话,应换页面 3(十分钟内页面 3 只使用一次)。
二、深入理解 LRU 算法
① 查看 LRU 缓存的特点
- 使用 LRU 策略实现的缓存是按照使用顺序进行排序的,每次访问条目时,LRU 算法就会将其移到缓存的顶部。通过这种方式,算法可以通过查看列表的底部,快速识别出最长时间未使用的条目。
- 如下所示,用户从网络上请求第一篇文章的 LRU 策略存储记录:
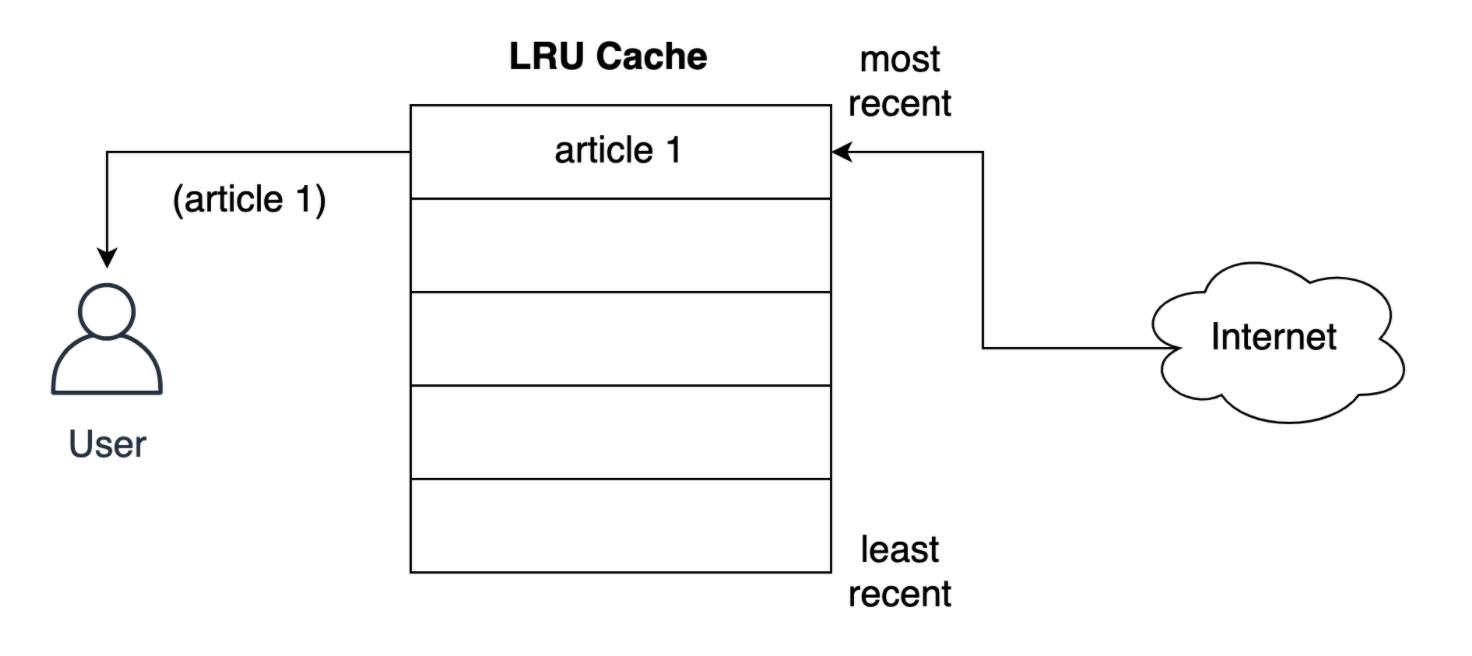
- 在将文章提供给用户之前,缓存如何将其存储在最近的槽中?如下所示,用户请求第二篇文章时发生的情况,第二篇文章存储到最上层的位置,即第二篇文章采用了最近的位置,将第一篇文章推到列表下方:
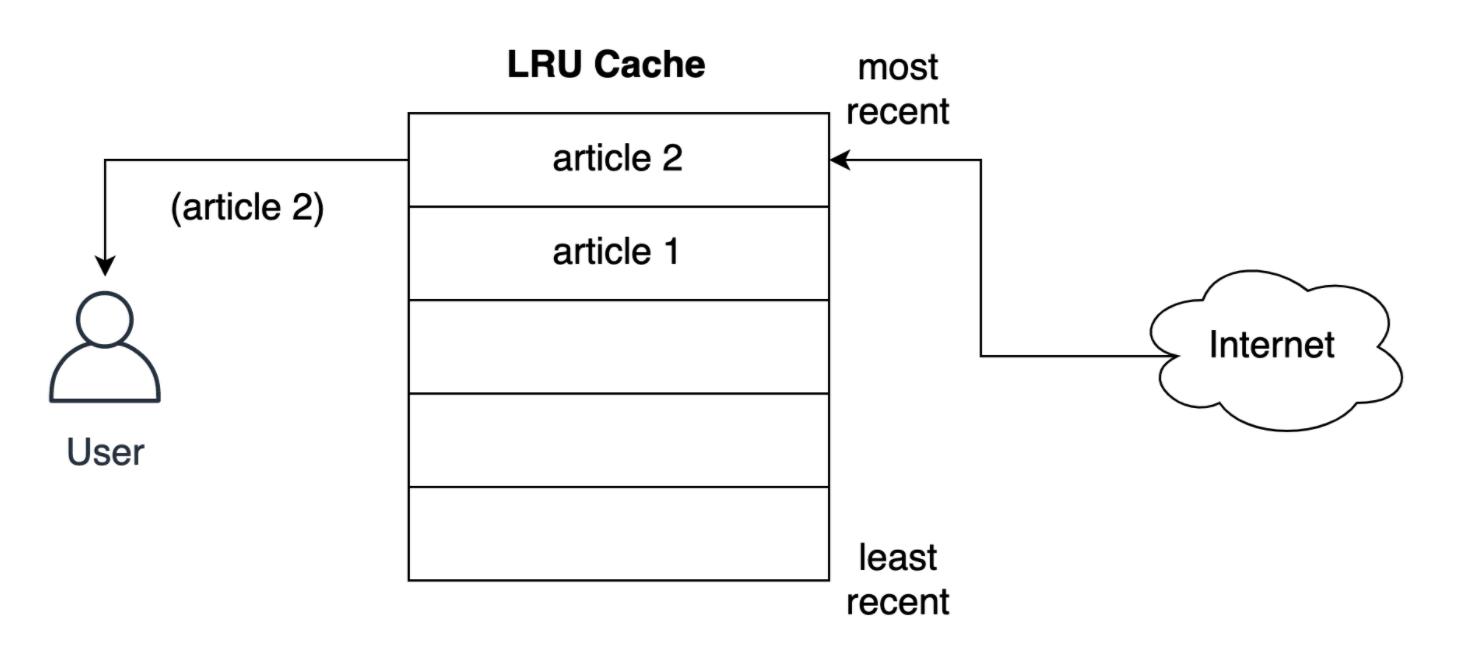
- LRU 策略假定使用的对象越新,将来使用该对象的可能性就越大,因此它尝试将该对象保留在缓存中的时间最长,即如果发生条目淘汰的话,会优先淘汰第一篇文档的缓存存储记录。
② 查看 LRU 缓存的结构
- 在 Python 中实现 LRU 缓存的一种方法就是使用双向链表(doubly linked list)和哈希映射(hash map),双向链表的头元素将指向最近使用的条目,而其尾部将指向最近使用最少的条目。LRU 缓存实现逻辑结构如下:
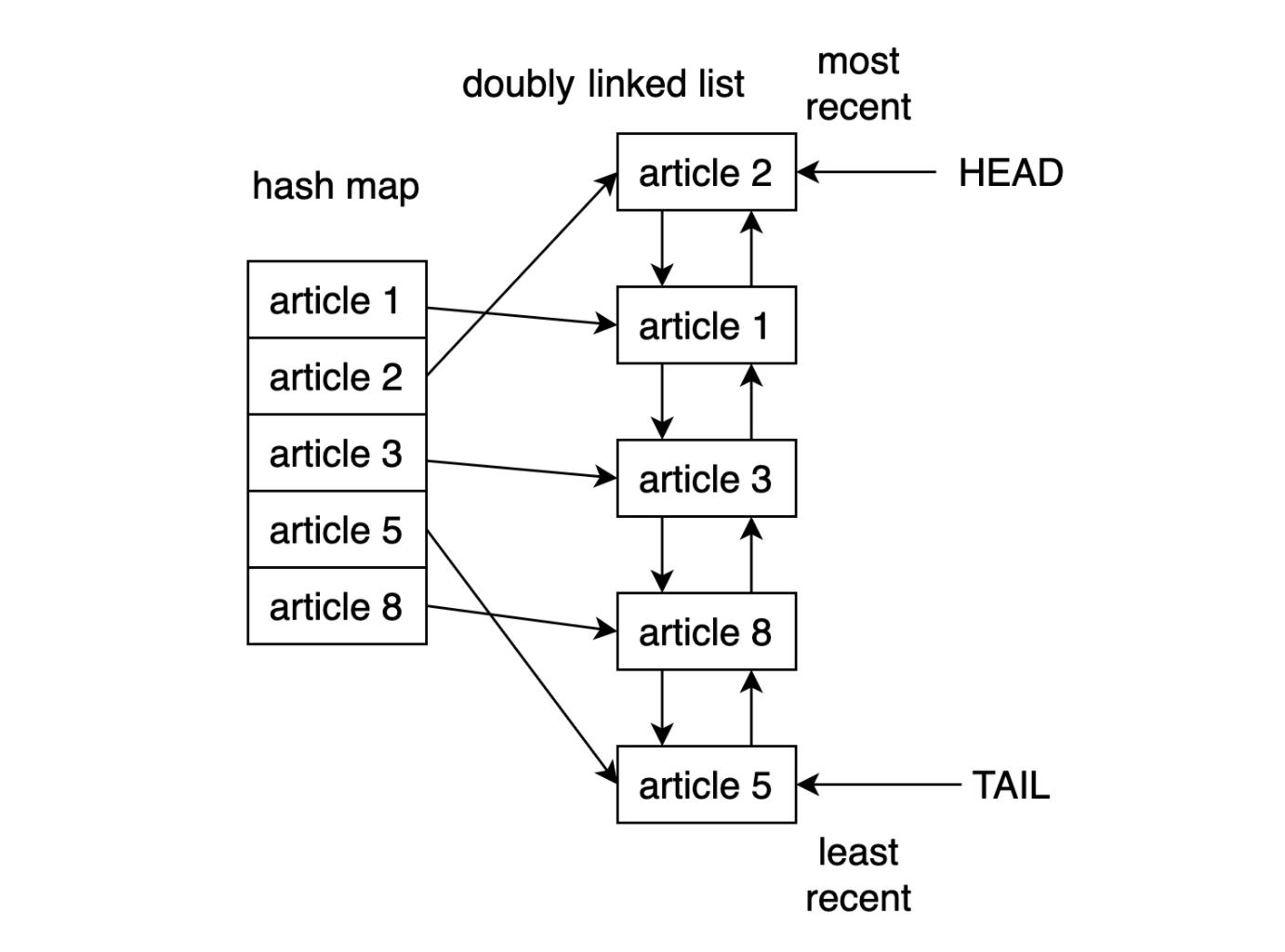
- 通过使用哈希映射,可以将每个条目映射到双链表中的特定位置,从而确保对缓存中的每个项的访问。这个策略非常快,访问最近最少使用的项和更新缓存的复杂度均为 O(1) 操作。
- 而从 Python3.2 版本开始,Python 新增 @lru_cache 这个装饰器用于实现 LRU 策略,从此可以使用这个装饰器来装饰函数并缓存其计算结果。
三、使用 lru_cache 装饰器
① @lru_cache 装饰器的实现原理
- 有很多方法可以实现应用程序的快速响应,而使用缓存就是一种非常常见的方法。如果能够正确使用缓存的话,可以使响应变得更快且减少计算资源的额外负载。
- 在 Python 中 functools 模块自带了 @lru_cache 这个装饰器来做缓存,其能够使用最近最少使用(LRU)策略来缓存函数的计算结果,这是一种简单但功能强大的技术:
-
- 实现 @lru_cache 装饰器;
-
- 了解 LRU 策略的工作运作原理;
-
- 使用 @lru_cache 装饰器来提高性能;
-
- 扩展 @lru_cache 装饰器的功能并使其在特定时间后过期。
- 就像先前实现的缓存方案一样,Python 中的 @lru_cache 装饰器存储也是使用字典来做为存储对象的,它将函数的执行结果缓存在字典的 key 里面,该 key 由对该函数的调用(包括函数的参数)组成,这就意味着这些函数的参数必须是可哈希的,装饰器才能正常工作。
② 斐波拉契数列
- 我们都应该知道斐波拉契数列的计算方式,常见的解决方式就是使用递归的思路:
-
- 0、1、1、2、3、5, 8、13、21、34 ……;
-
- 2 是上两项的和 ->(1+1);
-
- 3 是上两项的和 ->(1+2);
-
- 5 是上两项的和 ->(2+3)。
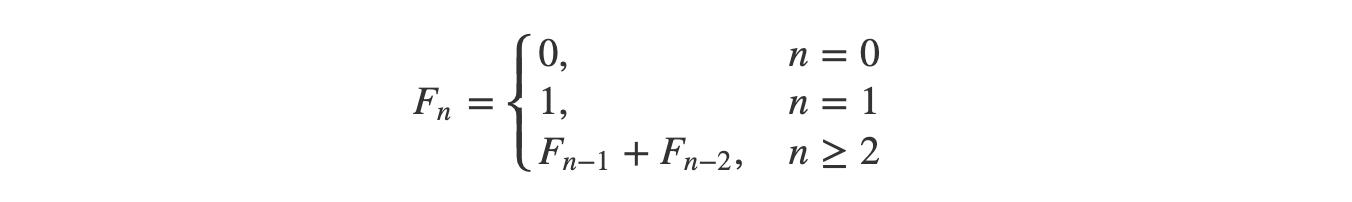
- 递归的计算简洁并且直观,但是由于存在大量重复计算,实际运行效率很低,并且会占用较多的内存。但是这里并不是需要关注的重点,只是来作为演示示例而已:
# 匿名函数
fib = lambda n: 1 if n <= 1 else fib(n-1) + fib(n-2)
# 将时间复杂度降低到线性
fib = lambda n, a=1, b=1: a if n == 0 else fib(n-1, b, a+b)
# 保证了匿名函数的匿名性
fib = lambda n, fib: 1 if n <= 1 else fib(n-1, fib) + fib(n-2, fib)
③ 使用 @lru_cache 缓存输出结果
- 使用 @lru_cache 装饰器来缓存的话,可以将函数调用结果存储在内存中,以便再次请求时直接返回结果:
from functools import lru_cache
@lru_cache
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)
④ 限制 @lru_cache 装饰器大小
- Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,该属性定义了在缓存开始淘汰旧条目之前的最大条目数,默认情况下,maxsize 设置为 128。
- 如果将 maxsize 设置为 None 的话,则缓存将无限期增长,并且不会驱逐任何条目。
from functools import lru_cache
@lru_cache(maxsize=16)
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)
# 查看缓存列表
>>> print(steps_to.cache_info())
CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
⑤ 使用 @lru_cache 实现 LRU 缓存
- 就像在前面实现的缓存解决方案一样,@lru_cache 在底层使用一个字典,它将函数的结果缓存在一个键下,该键包含对函数的调用,包括提供的参数。这意味着这些参数必须是可哈希的,才能让 decorator 工作。
- 示例:玩楼梯:
-
- 想象一下,你想通过一次跳上一个、两个或三个楼梯来确定到达楼梯中的一个特定楼梯的所有不同方式,到第四个楼梯有多少条路?所有不同的组合如下所示:
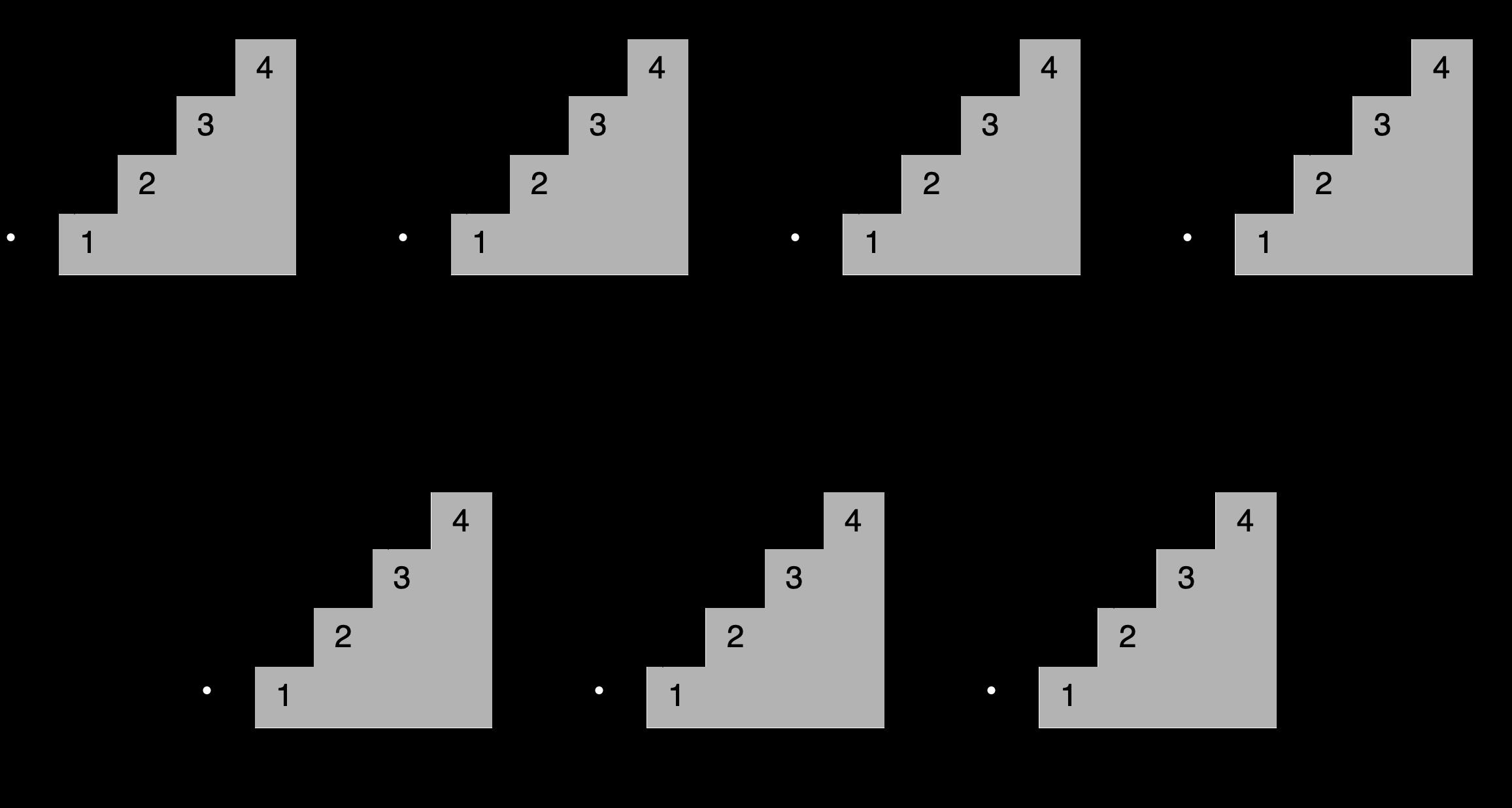
-
- 可以这样描述,为了到达当前的楼梯,你可以从下面的一个、两个或三个楼梯跳下去,将能够到达这些点的跳跃组合的数量相加,便能够获得到达当前位置的所有可能方法。
-
- 例如到达第四个楼梯的组合数量将等于你到达第三、第二和第一个楼梯的不同方式的总数。如下所示,有七种不同的方法可以到达第四层楼梯:

-
- 注意给定阶梯的解是如何建立在较小子问题的答案之上的,在这种情况下,为了确定到达第四个楼梯的不同路径,可以将到达第三个楼梯的四种路径、到达第二个楼梯的两种路径以及到达第一个楼梯的一种路径相加。
-
- 这种方法称为递归,下面是一个实现这个递归的函数:
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(4))
-
- 将此代码保存到一个名为 stairs.py 的文件中,并使用以下命令运行它:
$ python stairs.py
7
-
- 太棒了,这个代码适用于 4 个楼梯,但是数一下要走多少步才能到达楼梯上更高的地方呢?将第 33 行中的楼梯数更改为 30,并重新运行脚本:
$ python stairs.py
53798080
-
- 可以看到结果超过 5300 万个组合,这可真的有点多。
- 时间代码:
-
- 当找到第 30 个楼梯的解决方案时,脚本花了相当多的时间来完成。要获得基线,可以度量代码运行的时间,要做到这一点,可以使用 Python 的 timeit module,在第 33 行之后添加以下代码:
setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: min(times)")
-
- 还需要在代码的顶部导入 timeit module:
from timeit import repeat
-
- 以下是对这些新增内容的逐行解释:
-
-
- 第 35 行导入 steps_to() 的名称,以便 time.com .repeat() 知道如何调用它;
-
-
-
- 第 36 行用希望到达的楼梯数(在本例中为 30)准备对函数的调用,这是将要执行和计时的语句;
-
-
-
- 第 37 行使用设置代码和语句调用 time.repeat(),这将调用该函数 10 次,返回每次执行所需的秒数;
-
-
-
- 第 38 行标识并打印返回的最短时间。
-
-
- 现在再次运行脚本:
$ python stairs.py
53798080
Minimum execution time: 40.014977024000004
-
- 可以看到的秒数取决于特定硬件,在我的系统上,脚本花了 40 秒,这对于 30 级楼梯来说是相当慢的。
- 使用记忆来改进解决方案:
-
- 这种递归实现通过将其分解为相互构建的更小的步骤来解决这个问题,如下所示是一个树,其中每个节点表示对 steps_to() 的特定调用:
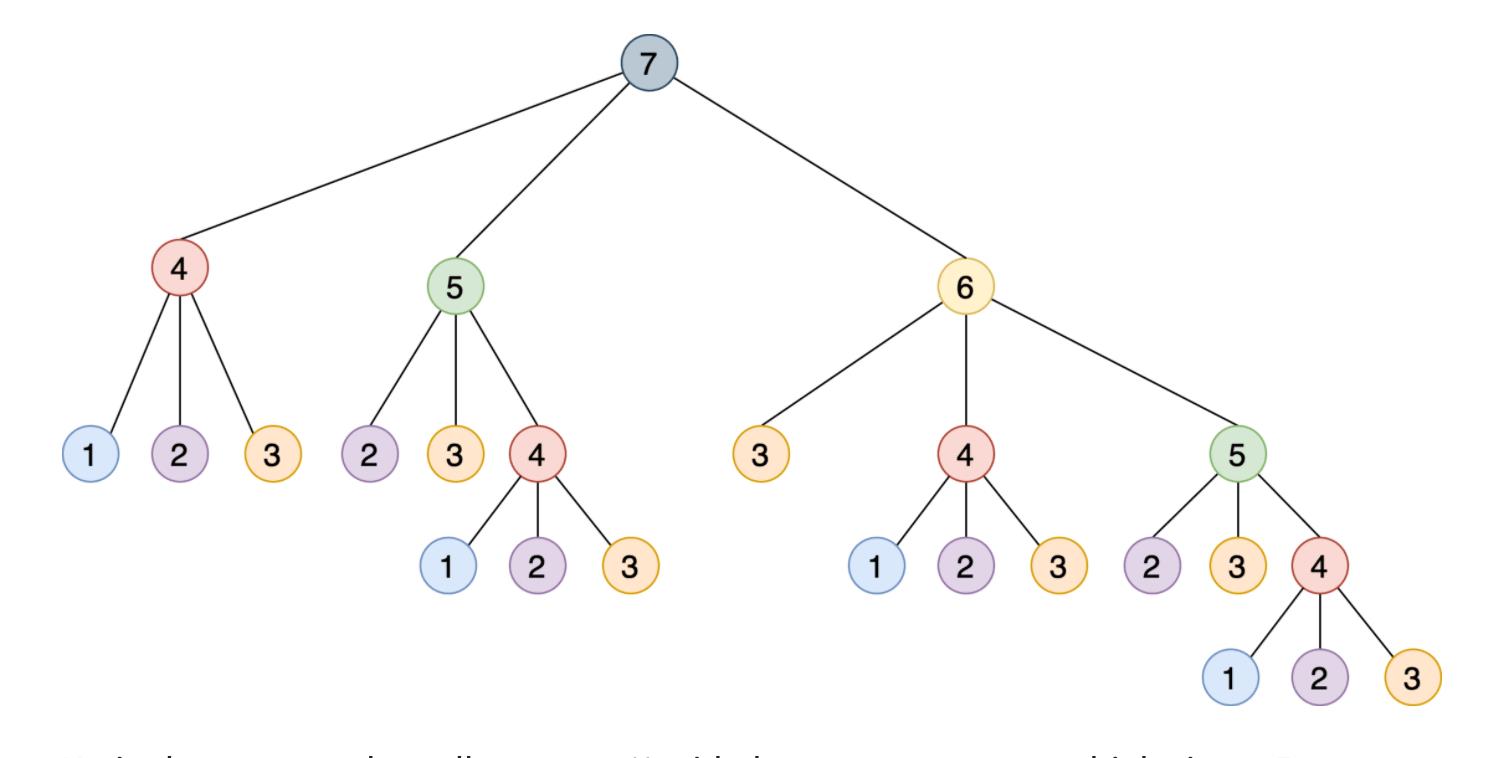
-
- 注意需要如何使用相同的参数多次调用 steps_to(),例如 steps_to(5) 计算两次,steps_to(4) 计算四次,steps_to(3) 计算七次,steps_to(2) 计算六次,多次调用同一个函数会增加不必要的计算周期,结果总是相同的。
-
- 为了解决这个问题,可以使用一种叫做记忆的技术,这种方法将函数的结果存储在内存中,然后在需要时引用它,从而确保函数不会为相同的输入运行多次,这个场景听起来像是使用 Python 的 @lru_cache 装饰器的绝佳机会。
-
- 只要做两个改变,就可以大大提高算法的运行时间:
-
-
- 从 functools module 导入 @lru_cache 装饰器;
-
-
-
- 使用 @lru_cache 装饰 steps_to()。
-
-
- 下面是两个更新后的脚本顶部的样子:
from functools import lru_cache
from timeit import repeat
@lru_cache
def steps_to(stair):
if stair == 1:
-
- 运行更新后的脚本产生如下结果:
$ python stairs.py
53798080
Minimum execution time: 7.999999999987184e-07
-
- 缓存函数的结果会将运行时从 40 秒降低到 0.0008 毫秒,这是一个了不起的进步。@lru_cache 装饰器存储了每个不同输入的 steps_to() 的结果,每次代码调用带有相同参数的函数时,它都直接从内存中返回正确的结果,而不是重新计算一遍答案,这解释了使用 @lru_cache 时性能的巨大提升。
⑥ 解包 @lru_cache 的功能
- 有了@lru_cache 装饰器,就可以将每个调用和应答存储在内存中,以便以后再次请求时进行访问,但是在内存耗尽之前,可以节省多少次调用呢?
- Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,它定义了在缓存开始清除旧条目之前的最大条目数,缺省情况下,maxsize 设置为 128,如果将 maxsize 设置为 None,那么缓存将无限增长,并且不会驱逐任何条目。如果在内存中存储大量不同的调用,这可能会成为一个问题。
- 如下是 @lru_cache 使用 maxsize 属性:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
- 在本例中,将缓存限制为最多 16 个条目,当一个新调用传入时,decorator 的实现将会从现有的 16 个条目中删除最近最少使用的条目,为新条目腾出位置。
- 要查看添加到代码中的新内容会发生什么,可以使用 @lru_cache 装饰器提供的 cache_info() 来检查命中和未命中的次数以及当前缓存的大小。为了清晰起见,删除乘以函数运行时的代码,以下是修改后的最终脚本:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(30))
print(steps_to.cache_info())
- 如果再次调用脚本,可以看到如下结果:
$ python stairs.py
53798080
CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
- 可以使用 cache_info() 返回的信息来了解缓存是如何执行的,并对其进行微调,以找到速度和存储之间的适当平衡。下面是 cache_info() 提供的属性的详细说明:
-
- hits=52 是 @lru_cache 直接从内存中返回的调用数,因为它们存在于缓存中;
-
- misses =30 是被计算的不是来自内存的调用数,因为试图找到到达第 30 级楼梯的台阶数,所以每次调用都在第一次调用时错过了缓存是有道理的;
-
- maxsize =16 是用装饰器的 maxsize 属性定义的缓存的大小;
-
- currsize =16 是当前缓存的大小,在本例中它表明缓存已满。
- 如果需要从缓存中删除所有条目,那么可以使用 @lru_cache 提供的 cache_clear()。
四、添加缓存过期
- 假设想要开发一个脚本来监视 Real Python 并在任何包含单词 Python 的文章中打印字符数。真正的 Python 提供了一个 Atom feed,因此可以使用 feedparser 库来解析提要,并使用请求库来加载本文的内容。
- 如下是监控脚本的实现:
import feedparser
import requests
import ssl
import time
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")
- 将此脚本保存到一个名为 monitor.py 的文件中,安装 feedparser 和请求库,然后运行该脚本,它将持续运行,直到在终端窗口中按 Ctrl+C 停止它:
$ pip install feedparser requests
$ python monitor.py
Checking feed...
Fetching article from server...
The Real Python Podcast – Episode #28: Using ... 29520
Fetching article from server...
Python Community Interview With David Amos 54256
Fetching article from server...
Working With Linked Lists in Python 37099
Fetching article from server...
Python Practice Problems: Get Ready for Your ... 164888
Fetching article from server...
The Real Python Podcast – Episode #27: Prepar... 30784
Checking feed...
Fetching article from server...
The Real Python Podcast – Episode #28: Using ... 29520
Fetching article from server...
Python Community Interview With David Amos 54256
Fetching article from server...
Working With Linked Lists in Python 37099
Fetching article from server...
Python Practice Problems: Get Ready for Your ... 164888
Fetching article from server...
The Real Python Podcast – Episode #27: Prepar... 30784
- 代码解释:
-
- 第 6 行和第 7 行:当 feedparser 试图访问通过 HTTPS 提供的内容时,这是一个解决方案;
-
- 第 16 行:monitor() 将无限循环;
-
- 第 18 行:使用 feedparser,代码从真正的 Python 加载并解析提要;
-
- 第 20 行:循环遍历列表中的前 5 个条目;
-
- 第 21 到 31 行:如果单词 python 是标题的一部分,那么代码将连同文章的长度一起打印它;
-
- 第 33 行:代码在继续之前休眠了 5 秒钟;
-
- 第 35 行:这一行通过将 Real Python 提要的 URL 传递给 monitor() 来启动监视过程。
- 每当脚本加载一篇文章时,“Fetching article from server…”的消息就会打印到控制台,如果让脚本运行足够长的时间,那么将看到这条消息是如何反复显示的,即使在加载相同的链接时也是如此。
- 这是一个很好的机会来缓存文章的内容,并避免每五秒钟访问一次网络,可以使用 @lru_cache 装饰器,但是如果文章的内容被更新,会发生什么呢?第一次访问文章时,装饰器将存储文章的内容,并在以后每次返回相同的数据;如果更新了帖子,那么监视器脚本将永远无法实现它,因为它将提取存储在缓存中的旧副本。要解决这个问题,可以将缓存条目设置为过期。
from functools import lru_cache, wraps
from datetime import datetime, timedelta
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
...
- 代码解释:
-
- 第 4 行:@timed_lru_cache 装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小;
-
- 第 6 行:代码用 lru_cache 装饰器包装了装饰函数,这允许使用 lru_cache 已经提供的缓存功能;
-
- 第 7 行和第 8 行:这两行用两个表示缓存生命周期和它将过期的实际日期的属性来修饰函数;
-
- 第 12 到 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了过期日期,如果是这种情况,那么它将清除缓存并重新计算生存期和过期日期。
- 请注意,当条目过期时,此装饰器如何清除与该函数关联的整个缓存,生存期适用于整个缓存,而不适用于单个项目,此策略的更复杂实现将根据条目的单个生存期将其逐出。
- 在程序中,如果想要实现不同缓存策略,可以查看 cachetools 这个库,该库提供了几个集合和修饰符,涵盖了一些最流行的缓存策略。
- 使用新装饰器缓存文章:
-
- 现在可以将新的 @timed_lru_cache 装饰器与监视器脚本一起使用,以防止每次访问时获取文章的内容。为了简单起见,把代码放在一个脚本中,可以得到以下结果:
import feedparser
import requests
import ssl
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry在 Python >= 3.2 中将缓存存储到文件 functools.lru_cache