Zookeeper和Redis实现分布式锁的可靠性分析
Posted 雪山上的蒲公英
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper和Redis实现分布式锁的可靠性分析相关的知识,希望对你有一定的参考价值。
在分布式系统中,为保证同一时间只有一个客户端可以对共享资源进行操作,需要对共享资源加锁来实现,常见有三种方式:
- 基于数据库实现分布式锁
- 基于 Redis 实现分布式锁
- 基于 Zookeeper 实现分布式锁
高并发下数据库锁性能太差,本文不做探究。仅针对Redis 和 Zookeeper 实现的分布式锁进行分析。
实现一个分布式锁应该具备的特性:
- 高可用、高性能的获取锁与释放锁
- 在分布式系统环境下,一个方法或者变量同一时间只能被一个线程操作
- 具备锁失效机制,网络中断或宕机无法释放锁时,锁必须被删除,防止死锁
- 具备阻塞锁特性,即没有获取到锁,则继续等待获取锁
- 具备非阻塞锁特性,即没有获取到锁,则直接返回获取锁失败
- 具备可重入特性,一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法,而无需重新获得锁
先上结论,Redis在锁时间限制和缓存一致性存在一定问题,Zookeeper在可靠性上强于Redis,只是效率相对较低,开发人员需要根据实际需求进行技术选型。
单机情况下:
1. Redis单机实现分布式锁
1.1 Redis加锁
//SET resource_name my_random_value NX PX 30000 String result = jedis.set(key, value, "NX", "PX", 30000); if ("OK".equals(result)) { return true; //代表获取到锁 } return false;
加锁就一行代码:jedis.set(String key, String value, String nxxx, String expx, int time),这个set()方法一共有五个形参:
-
第一个为key,使用key来当锁,因为key是唯一的。
-
第二个为value,是由客户端生成的一个随机字符串,相当于是客户端持有锁的标志。用于标识加锁和解锁必须是同一个客户端。
-
第三个为nxxx,传的是NX,意思是SET IF NOT EXIST,即当key不存在时,进行set操作;若key已经存在,则不做任何操作。
-
第四个为expx,传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
-
第五个为time,与第四个参数相呼应,代表key的过期时间,如上30000表示这个锁有一个30秒的自动过期时间。
1.2 Redis解锁
解锁时,为了防止客户端1获得的锁,被客户端2给释放,需要采用的Lua脚本来释放锁:
final Long RELEASE_SUCCESS = 1L; //采用Lua脚本来释放锁 String script = "if redis.call(\'get\', KEYS[1]) == ARGV[1] then return redis.call(\'del\', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId)); if (RELEASE_SUCCESS.equals(result)) { return true; } return false;
在执行这段Lua脚本的时候,KEYS[1]的值为 key,ARGV[1]的值为 value。原理就是先获取锁对应的value值,保证和客户端传进去的value值相等,这样就能避免自己的锁被其他人释放。另外,采取Lua脚本操作保证了原子性。如果不是原子性操作,则有了下述情况出现:
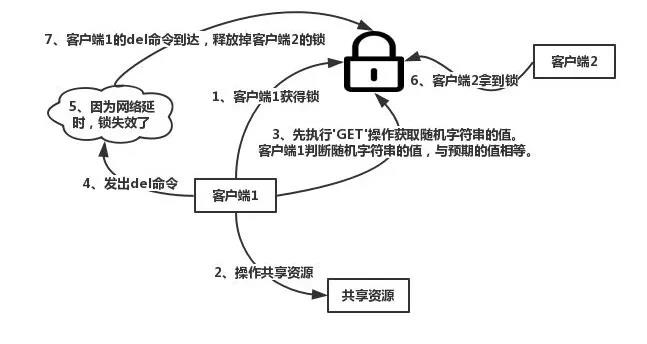
1.3 Redis加锁过期时间设置问题
理想情况是客户端Redis加锁后,完成一系列业务操作,顺利在锁过期时间前释放掉锁,这个分布式锁的设置是有效的。但是如果客户端在操作共享资源的过程中,因为长期阻塞的原因,导致锁过期,那么接下来访问共享资源就变得不再安全。
2. Zookeeper单机实现分布式锁
2.1 Curator实现Zookeeper加解锁
使用 Apache 开源的curator 可实现 Zookeeper 分布式锁。
可以通过调用 InterProcessLock接口提供的几个方法来实现加锁、解锁。
/** * 获取锁、阻塞等待、可重入 */ public void acquire() throws Exception; /** * 获取锁、阻塞等待、可重入、超时则获取失败 */ public boolean acquire(long time, TimeUnit unit) throws Exception; /** * 释放锁 */ public void release() throws Exception; /** * Returns true if the mutex is acquired by a thread in this JVM */ boolean isAcquiredInThisProcess();
2.2 Zookeeper加锁实现原理
Zookeeper的分布式锁原理是利用了临时节点(EPHEMERAL)的特性。其实现原理:
- 创建一个锁目录lock
- 线程A获取锁会在lock目录下,创建临时顺序节点
- 获取锁目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁
- 线程B创建临时节点并获取所有兄弟节点,判断自己不是最小节点,设置监听(watcher)比自己次小的节点(只关注比自己次小的节点是为了防止发生“羊群效应”)
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是最小的节点,获得锁
由于节点的临时属性,如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这样就避免了设置过期时间的问题。
2.3 GC停顿导致临时节点释放问题
但是使用临时节点又会存在另一个问题:Zookeeper如果长时间检测不到客户端的心跳的时候(Session时间),就会认为Session过期了,那么这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。

如上图所示,客户端1发生GC停顿的时候,Zookeeper检测不到心跳,也是有可能出现多个客户端同时操作共享资源的情形。当然,你可以说,我们可以通过JVM调优,避免GC停顿出现。但是注意了,我们所做的一切,只能尽可能避免多个客户端操作共享资源,无法完全消除。
集群情况下:
3. Redis集群下分布式锁存在问题
3.1 集群Master宕机导致锁丢失
为了Redis的高可用,一般都会给Redis的节点挂一个slave,然后采用哨兵模式进行主备切换。但由于Redis的主从复制(replication)是异步的,这可能会出现在数据同步过程中,master宕机,slave来不及同步数据就被选为master,从而数据丢失。具体流程如下所示:
-
(1)客户端1从Master获取了锁。
-
(2)Master宕机了,存储锁的key还没有来得及同步到Slave上。
-
(3)Slave升级为Master。
-
(4)客户端1的锁丢失,客户端2从新的Master获取到了对应同一个资源的锁。
3.2 Redlock算法
为了应对这个情形, Redis作者antirez基于分布式环境下提出了一种更高级的分布式锁的实现方式:Redlock。
antirez提出的redlock算法大概是这样的:
在Redis的分布式环境中,我们假设有N个Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。我们确保将在N个实例上使用与在Redis单实例下相同方法获取和释放锁。现在我们假设有5个Redis master节点(官方文档里将N设置成5,其实大等于3就行),同时我们需要在5台服务器上面运行这些Redis实例,这样保证他们不会同时都宕掉。
为了取到锁,客户端应该执行以下操作:
-
(1)获取当前Unix时间,以毫秒为单位。
-
(2)依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁。当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
-
(3)客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
-
(4)如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
-
(5)如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
redisson已经有对redlock算法封装,如下是调用代码示例:
Config config = new Config(); config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") .setMasterName("masterName") .setPassword("password").setDatabase(0); RedissonClient redissonClient = Redisson.create(config); // 还可以getFairLock(), getReadWriteLock() RLock redLock = redissonClient.getLock("REDLOCK_KEY"); boolean isLock; try { isLock = redLock.tryLock(); // 500ms拿不到锁, 就认为获取锁失败。10000ms即10s是锁失效时间。 isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); if (isLock) { //TODO if get lock success, do something; } } catch (Exception e) { } finally { // 无论如何, 最后都要解锁 redLock.unlock(); }
3.3 Redlock未完全解决问题
Redlock算法细想一下还存在下面的问题:
节点崩溃重启,会出现多个客户端持有锁
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- (1)客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- (2)节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- (3)节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
为了应对节点重启引发的锁失效问题,redis的作者antirez提出了延迟重启的概念,即一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,等待的时间大于锁的有效时间。采用这种方式,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。这其实也是通过人为补偿措施,降低不一致发生的概率。
时间跳跃问题
- (1)假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- (2)客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- (3)节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- (4)客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- (5)客户端1和客户端2现在都认为自己持有了锁。
为了应对始终跳跃引发的锁失效问题,redis的作者antirez提出了应该禁止人为修改系统时间,使用一个不会进行“跳跃”式调整系统时钟的ntpd程序。这也是通过人为补偿措施,降低不一致发生的概率。
超时导致锁失效问题
RedLock算法并没有解决,操作共享资源超时,导致锁失效的问题。回忆一下RedLock算法的过程,如下图所示
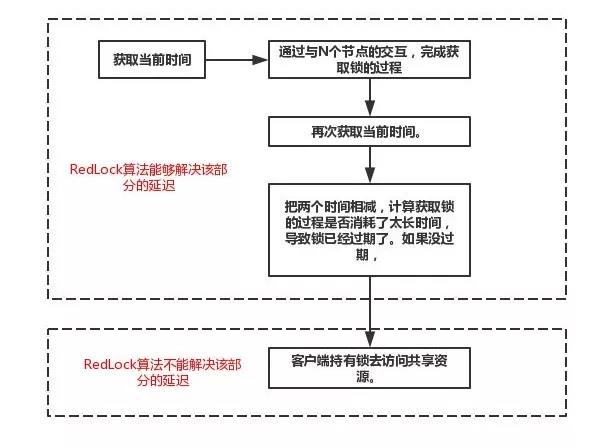
如图所示,我们将其分为上下两个部分。对于上半部分框图里的步骤来说,无论因为什么原因发生了延迟,RedLock算法都能处理,客户端不会拿到一个它认为有效,实际却失效的锁。然而,对于下半部分框图里的步骤来说,如果发生了延迟导致锁失效,都有可能使得客户端2拿到锁。因此,RedLock算法并没有解决该问题。
4. Zookeeper集群下分布式锁可靠性分析
4.1 Zookeeper的写数据的原理
Zookeeper在集群部署中,Zookeeper节点数量一般是奇数,且一定大等于3。下面是Zookeeper的写数据的原理:

那么写数据流程步骤如下:
- (1)在Client向Follwer发出一个写的请求
- (2)Follwer把请求发送给Leader
- (3)Leader接收到以后开始发起投票并通知Follwer进行投票
- (4)Follwer把投票结果发送给Leader,只要半数以上返回了ACK信息,就认为通过
- (5)Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给Leader,然后commit;
- (6)Follwer把请求结果返回给Client
还有一点,Zookeeper采取的是全局串行化操作。
4.2 集群模式下Zookeeper可靠性分析
下面列出Redis集群下分布式锁可能存在的问题,判断其在Zookeeper集群下是否会存在:
集群同步
- client给Follwer写数据,可是Follwer却宕机了,会出现数据不一致问题么?不可能,这种时候,client建立节点失败,根本获取不到锁。
- client给Follwer写数据,Follwer将请求转发给Leader,Leader宕机了,会出现不一致的问题么?不可能,这种时候,Zookeeper会选取新的leader,继续上面的提到的写流程。
总之,采用Zookeeper作为分布式锁,你要么就获取不到锁,一旦获取到了,必定节点的数据是一致的,不会出现redis那种异步同步导致数据丢失的问题。
时间跳跃问题
Zookeeper不依赖全局时间,不存在该问题。
超时导致锁失效问题
Zookeeper不依赖有效时间,不存在该问题。
5. 锁的其他特性比较
redis的读写性能比Zookeeper强太多,如果在高并发场景中,使用Zookeeper作为分布式锁,那么会出现获取锁失败的情况,存在性能瓶颈。
Zookeeper可以实现读写锁,Redis不行。
Zookeeper的watch机制,客户端试图创建znode的时候,发现它已经存在了,这时候创建失败,那么进入一种等待状态,当znode节点被删除的时候,Zookeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这套机制,redis无法实现
参考:
https://www.cnblogs.com/rjzheng/p/9310976.html
https://redis.io/topics/distlock
https://mp.weixin.qq.com/s/7ze2v9HQH07rvYoNpUTmzw
https://blog.csdn.net/fengxueersui/article/details/80139039
https://www.cnblogs.com/cjsblog/p/8367002.html
https://www.cnblogs.com/cjsblog/p/9831423.html
以上是关于Zookeeper和Redis实现分布式锁的可靠性分析的主要内容,如果未能解决你的问题,请参考以下文章