Hadoop全分布模式启动集群
Posted 头痛不头痛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop全分布模式启动集群相关的知识,希望对你有一定的参考价值。
一、 初始化工作:
1. 准备三台机器
| hostanme | IP | 用途 |
| master | 192.168.0.10 | namenode |
| node1 | 192.168.0.11 | datenode |
| node2 | 192.168.0.12 | datenode |
在三台机器上做下面的动作
2. 编辑/etc/hosts
192.168.0.10 master 192.168.0.11 node1 192.168.0.12 node2
3. 创建用户hadoop,及数据存储目录
useradd hadoop echo hadoop|passwd --stdin hadoop mkdir /hadoop mkdir /var/log/hadoop mkdir /var/run/hadoop chown -R hadoop:hadoop /hadoop chown -R hadoop:hadoop /var/log/hadoop /var/run/hadoop
4. 建立节点之间的免密访问hadoop用户
master节点执行
su - hadoop ssh-keygen ssh-copy-id hadoop@node1 ssh-copy-id hadoop@node2
同样在node1和node2执行,后面的主机名需要做相应的修改
如果master也作为了datenode,写在了works文件里,则需要把自身设置免密访问
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
5. 安装JAVA运行环境,得到如下效果
[hadoop@node2 ~]$ java -version java version "1.8.0_181" Java(TM) SE Runtime Environment (build 1.8.0_181-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode) [hadoop@node2 ~]$ echo $JAVA_HOME /usr/java/jdk1.8.0_181
6. 安装需要的依赖
yum -y install pdsh
二、安装并配置Hadoop
在Master节点下执行下面的步骤:
1. 下载hadoop
wget -P /usr/local/src https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
2. 解压到/opt下,并指定属主
在root用户下执行
tar xvf hadoop-3.3.0.tar.gz -C /opt
chown -R hadoop:hadoop /opt/hadoop-3.3.0/
3. 配置hadoop
在hadoop用户下编辑
/opt/hadoop-3.3/etc/hadoop/hadoop-env.sh:
export JAVA_HOME=/usr/java/jdk1.8.0_181
export HADOOP_LOG_DIR=/var/log/hadoop
export HADOOP_PID_DIR=/var/run/hadoop
/opt/hadoop-3.3.0/etc/hadoop/workers:
node1
node2
master
/opt/hadoop-3.3/etc/hadoop/core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
/opt/hadoop-3.3.0/etc/hadoop/mapred-site.xml:
<configuration> <property> <!-- 历史服务器端地址 --> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <!-- 历史服务器web端地址 --> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
/opt/hadoop-3.3.0/etc/hadoop/yarn-site.xml:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> <discription>每个节点可用内存,单位MB,默认8182MB</discription> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
4. 复制/opt/hadoop-3.3.0到node1和node2
scp -r /opt/hadoop-3.3.0 root@node1:/opt
scp -r /opt/hadoop-3.3.0 root@node1:/opt
5. 配置hadoop环境变量
在root用户下编辑/etc/profile.d/hadoop.sh
export HADOOP_HOME=/opt/hadoop-3.3.0 export PATH=$PATH:/$HADOOP_HOME/bin
复制到node1和node2
scp /etc/profile.d/hadoop.sh root@node1:/etc/profile.d/ scp /etc/profile.d/hadoop.sh root@node2:/etc/profile.d/
6. 格式化文件系统
在haddop用户下运行
hdfs namenode -format
7. 启动NameNode守护程序和DataNode守护程序
[hadoop@master hadoop-3.3.0]$ ./sbin/start-dfs.sh Starting namenodes on [master] Starting datanodes Starting secondary namenodes [master]
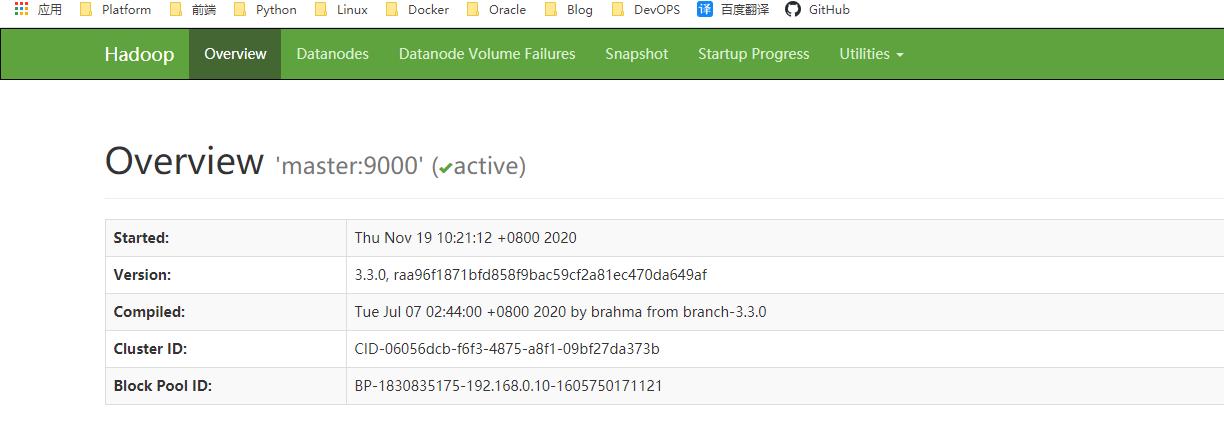
查看web界面
- NameNode http://192.168.0.10:9870
8. 启动ResourceManager守护程序和NodeManager守护程序
[hadoop@master hadoop-3.3.0]$ ./sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers
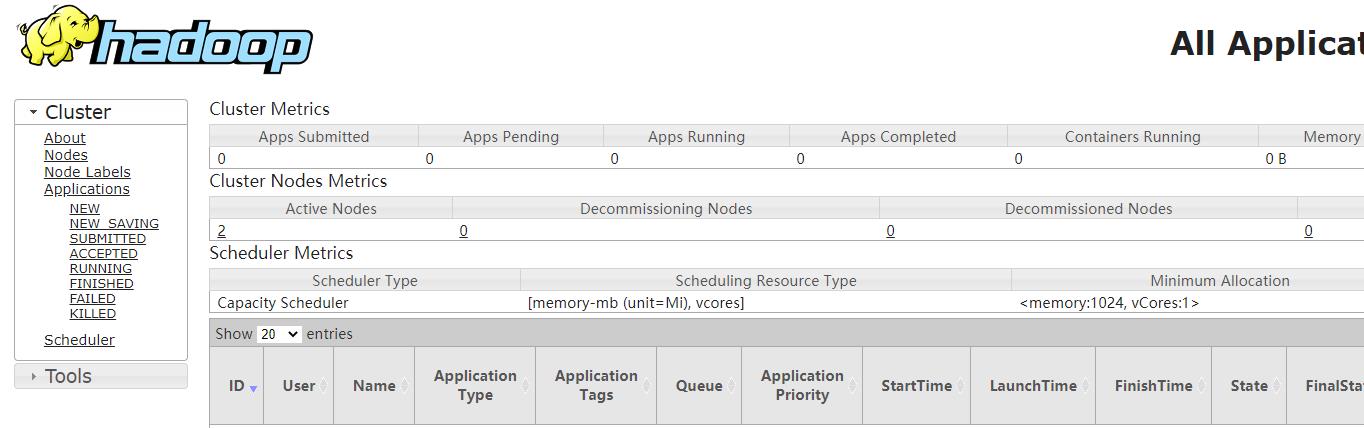
浏览Web界面以找到ResourceManager;默认情况下,它在以下位置可用:
- ResourceManager- http://192.168.0.10:8088
9. 启动MapReduce JobHistory Server
[hadoop@master hadoop-3.3.0]$ ./bin/mapred --daemon start historyserver
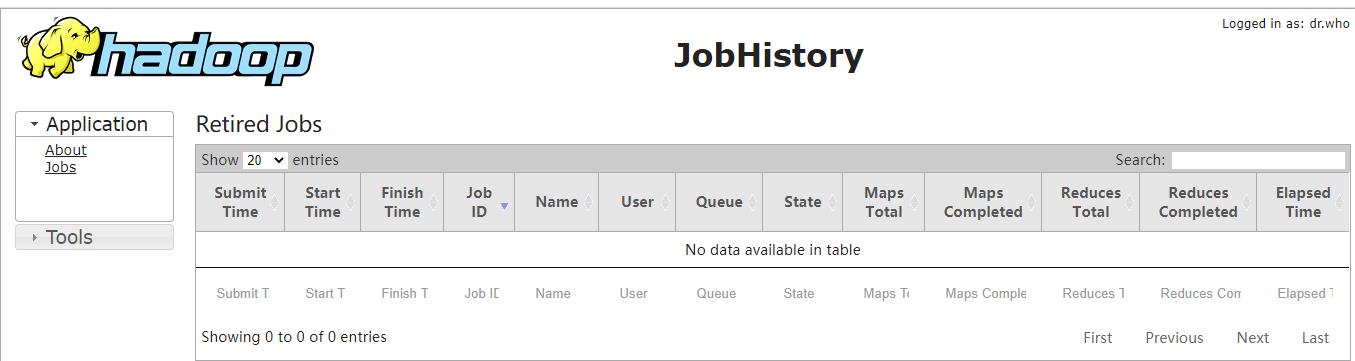
浏览web界面
- historyserver:http://192.168.0.10:19888/
三 在本地运行MapReduce作业
1. 设置执行MapReduce作业所需的HDFS目录:
hdfs dfs -mkdir /user hdfs dfs -mkdir /user/hadoop
2. 将本地的输入文件上传到HDFS目录
[hadoop@master hadoop-3.3.0]$ hdfs dfs -mkdir input [hadoop@master hadoop-3.3.0]$ hdfs dfs -put etc/hadoop/*xml input
3. 查看上传到HDFS的文件
[hadoop@master hadoop-3.3.0]$ hdfs dfs -ls /user/hadoop/input Found 10 items -rw-r--r-- 1 hadoop supergroup 9213 2020-11-19 11:09 /user/hadoop/input/capacity-scheduler.xml -rw-r--r-- 1 hadoop supergroup 1056 2020-11-19 11:09 /user/hadoop/input/core-site.xml -rw-r--r-- 1 hadoop supergroup 11765 2020-11-19 11:09 /user/hadoop/input/hadoop-policy.xml -rw-r--r-- 1 hadoop supergroup 683 2020-11-19 11:09 /user/hadoop/input/hdfs-rbf-site.xml -rw-r--r-- 1 hadoop supergroup 1345 2020-11-19 11:09 /user/hadoop/input/hdfs-site.xml -rw-r--r-- 1 hadoop supergroup 620 2020-11-19 11:09 /user/hadoop/input/httpfs-site.xml -rw-r--r-- 1 hadoop supergroup 3518 2020-11-19 11:09 /user/hadoop/input/kms-acls.xml -rw-r--r-- 1 hadoop supergroup 682 2020-11-19 11:09 /user/hadoop/input/kms-site.xml -rw-r--r-- 1 hadoop supergroup 1388 2020-11-19 11:09 /user/hadoop/input/mapred-site.xml -rw-r--r-- 1 hadoop supergroup 3076 2020-11-19 11:09 /user/hadoop/input/yarn-site.xml
3. 利用示例的jar文件,过滤出input目录中的以dfs开头的单词
[hadoop@master hadoop-3.3.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output \'dfs[a-z.]+\'
4. 查看结果
直接在hdfs中查看
[hadoop@master hadoop-3.3.0]$ hdfs dfs -cat output/* 1 dfsadmin 1 dfs.replication 1 dfs.name.dir 1 dfs.data.dir
或者下载到本地查看
$ bin/hdfs dfs -get output output $ cat output/*
四、遇到的问题及解决
问题
node1和node2的datenode已经启动,但是在webui上看不到node1和node2
解决办法:
在node1和node2节点进行下面操作:
需要去修改hdfs-site.xml 中找到配置name和data的2个路径,然后删除标记部分

然后删除实际目录
rm -rf /hadoop/dfs/name
rm -rf /hadoop/dfs/data
修改core-site.xml,删除标记部分
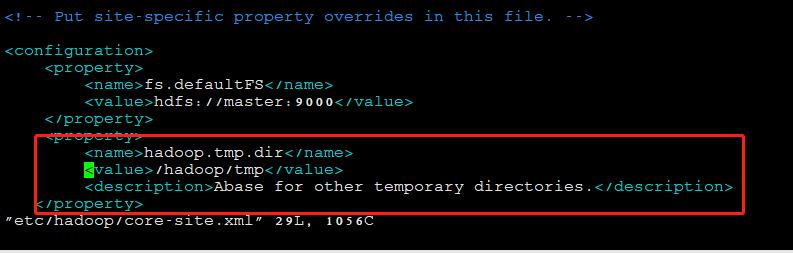
rm -rf /hadoop/tmp
参考:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
https://my.oschina.net/RyenAng/blog/4486155
以上是关于Hadoop全分布模式启动集群的主要内容,如果未能解决你的问题,请参考以下文章