性能优化利器:剖析MySQL 5.7新特征 sys schema
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能优化利器:剖析MySQL 5.7新特征 sys schema相关的知识,希望对你有一定的参考价值。
性能优化利器:剖析mysql 5.7新特征 sys schema
导读:很多团队在评估合适的时机切换到 MySQL 5.7,本文是李春在高可用架构群的分享,介绍 MySQL 5.7 新的性能分析利器。
 李春,现任沃趣科技 MySQL 负责人,高级 MySQL 数据库专家,从事 MySQL 开发和运维工作 8 年。在阿里巴巴担任 MySQL 数据库 leader 期间,主要负责应用架构的优化和部署,实现了阿里巴巴 3 亿 产品 从 Oracle 小型机到 64 台 MySQL 的平滑迁移。专注于研究 MySQL 复制、高可用、分布式和运维自动化相关领域。在大规模、分布式 MySQL 集群管理、调优、快速定位和解决问题方面有丰富经验。管理超过 1400 台 MySQL 服务器,近 3000 个实例。完成 MySQL 自动装机系统、阿里巴巴 MySQL 标准化文档和操作手册、MySQL 自动规范性检查系统、MySQL 自动信息采集系统等标准化文档和自动化运维工具。
李春,现任沃趣科技 MySQL 负责人,高级 MySQL 数据库专家,从事 MySQL 开发和运维工作 8 年。在阿里巴巴担任 MySQL 数据库 leader 期间,主要负责应用架构的优化和部署,实现了阿里巴巴 3 亿 产品 从 Oracle 小型机到 64 台 MySQL 的平滑迁移。专注于研究 MySQL 复制、高可用、分布式和运维自动化相关领域。在大规模、分布式 MySQL 集群管理、调优、快速定位和解决问题方面有丰富经验。管理超过 1400 台 MySQL 服务器,近 3000 个实例。完成 MySQL 自动装机系统、阿里巴巴 MySQL 标准化文档和操作手册、MySQL 自动规范性检查系统、MySQL 自动信息采集系统等标准化文档和自动化运维工具。
sys schema 由来
Performance schema 引入
Oracle 早就有了 v$ 等一系列方便诊断数据库性能的工具,MySQL DBA 只有羡慕嫉妒恨的份,但是 5.7 引入的 sys schema 缓解了这个问题,让我们可以通过 sys schema 一窥 MySQL 性能损耗,诊断 MySQL 的各种问题。
说到诊断 MySQL 性能问题,不得不提在 MySQL 5.5 引入的 performance_schema,最开始引入时,MySQL 的 performance_schema 性能消耗巨大,随着版本的更新和代码优化,5.7 的 performance_schema 对 MySQL 服务器额外的消耗越来越少,我们可以放心的打开 performance_shema 来收集 MySQL 数据库的性能损耗。Tarique Saleem 同学测试了一下 sys schema 对 CPU 和 IO的额外消耗,基本在 1% - 3% 之间,有兴趣的同学可以参考他的这篇 blog: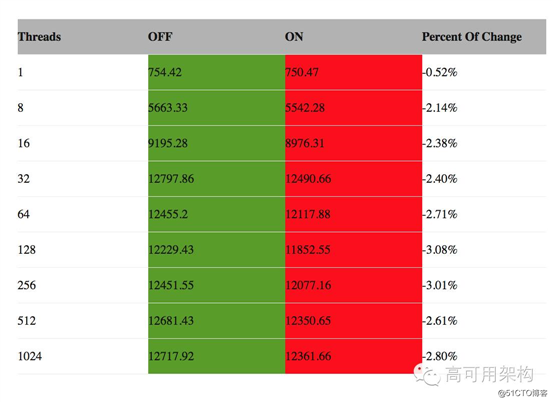
(CPU Bound, Sysbench Read Only Mode)
http://mysqlserverteam.com/performance-schema-great-power-comes-without-great-cost/
performance_schema 不仅由于他的性能消耗大著名,还由于其复杂难用而臭名昭著。5.7 上的 performance schema 已经有 87 张表了,每个表都是各种统计信息的罗列;另外,他的这些表和 information_schema 中的部分表也缠夹不清,让大家用得很不习惯。
sys schema VS performance schema VS information schema
现在 MySQL 在 5.7 又新增了sys schema,它和 performance_schema 和 information schema 到底是什么关系?
- Information_schema 定位基本是 MySQL 元数据信息,比如:TABLES 记录了 MySQL 有哪些表,COLUMNS 记录了各个表有哪些列 。
- performance_schema 记录了 MySQL 实时底层性能消耗情况,比如:events_waits_current 记录了 MySQL 各个线程当前在等待的 event。
虽然他们之间的这个定位区别并没有那么明显:比如,Information_schema 的 innodb_locks 就记录了 innodb 当前锁的信息,它并不是 MySQL 的元数据信息。sys schema 最开始是 MarkLeith 同学为了方便读取和诊断 MySQL 性能引入到 MySQL 的。所以 sys schema 定位应该是最清晰的:它包含一系列对象,这些对象能够辅助 DBA 和开发人员了解 performance schema 和 information_schema 采集的数据。
sys schema 包含了什么?
sys schema 包含一些对象,这些对象主要用于调优和故障分析。 包括:
- 将 performance schema 和 information schema 中的数据用更容易理解的方式来总结归纳出来的“视图”。
- 提供 performance schema 和 information schema 配置或者生成分析报告类似操作的“存储过程”
- sys schema 本身不采集和存储什么信息,它只是为程序或者用户提供一个更加方便的诊断系统性能和排除故障的“接口”。也就是说,查询 performance schema 和 information schema 配置和提供格式化服务的“存储函数” 。
- 避免用户在 information schema 和 performance schema 中写各种复杂的查询来获得到底谁锁了谁,每个线程消耗的内存是多少 ( 视图 memory_by_thread_by_current_bytes ),每个 SQL 执行了多少次,大致的执行时间是多少( 视图 statements_with_runtimes_in_95th_percentile )等,这些 sys schema 都直接帮你写好,你只需要直接查询就好了。
- 编写了一些现成的存储过程,方便你:直接使用 diagnostics() 存储过程创建用于诊断当前服务器状态的报告;使用 ps_trace_thread() 存储过程创建对应线程的图形化( .dot类型 )性能数据。
- 编写了一些现成的存储函数,方便你:直接使用 ps_thread_account() 存储函数获得发起这个线程的用户,使用 ps_thread_trx_info() 来获得某线程当前事务或者历史执行过的语句( JSON 格式返回 )。
当然,你也可以在 sys schema 下增加自己用于诊断 MySQL 性能的“视图”、“存储过程”和“存储函数”。
sys schema 举例
怎么利用 sys schema 来定位问题和诊断数据库性能?这里简单举一个 innodb 行锁的例子来说明。
模拟行锁
拿一个实际的场景来说 sys schema 能够辅助我们分析当前数据库上哪个 session 被锁住了,并且提供“清理”锁的语句。我们模拟一个表的某一行被锁住的情况,假设表创建语句如下:
CREATE TABLE
test2(idint(11) NOT NULL,namevarchar(16) DEFAULT NULL,ageint(11) DEFAULT NULL,sexint(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
有一条数据如下:
mysql > select * from test2;
+----+---------+------+------+
| id | name | age | sex |
+----+---------+------+------+
| 2 | pickup1 | 1 | 1 |
+----+---------+------+------+
我们分别在 session 1 和 session 2 上同时操作这条数据,这样的话必然对同一行记录相互有锁死的情况,然后我们通过 session 3 来查看 sys schema 里面的 innodb_lock_waits,确定到底是谁锁了谁,怎么解锁?操作步骤如下: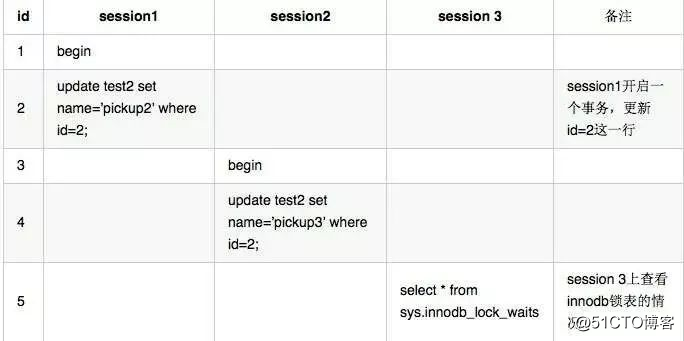
通过 sys.innodb_lock_waits 查看 innodb 锁表情况
对应的在 session 3上查看到的记录:
mysql > select * from sys.innodb_lock_waitsG
1. row
wait_started: 2016-05-04 01:04:38
wait_age: 00:00:02
wait_age_secs: 2
locked_table:test.test2
locked_index: PRIMARY
locked_type: RECORD
waiting_trx_id: 5382
waiting_trx_started: 2016-05-04 00:24:21
waiting_trx_age: 00:40:19
waiting_trx_rows_locked: 4
waiting_trx_rows_modified: 0
waiting_pid: 3
waiting_query: update test2 set name=‘pickup3‘ where id=2
waiting_lock_id: 5382:31:3:3
waiting_lock_mode: X
blocking_trx_id: 5381
blocking_pid: 2
blocking_query: NULL
blocking_lock_id: 5381:31:3:3
blocking_lock_mode: X
blocking_trx_started: 2016-05-04 00:23:49
blocking_trx_age: 00:40:51
blocking_trx_rows_locked: 1
blocking_trx_rows_modified: 1
sql_kill_blocking_query: KILL QUERY 2
sql_kill_blocking_connection: KILL 2
这里我们可以看到 3 号线程( waiting_pid: 3 )在等待 2 号线程( blocking_pid: 2 )的 X 锁( blocking_lock_mode: X ),如果需要解锁,需要杀掉 2 号线程( sql_kill_blocking_connection: KILL 2 )。
innodb_lock_waits 本质
其实 sys schema 的 innodb_lock_waits 只是 information schema 的视图而已。
CREATE ALGORITHM = TEMPTABLE DEFINER =
mysql.sys@localhostSQL SECURITY INVOKER VIEWinnodb_lock_waitsAS
SELECTr.trx_wait_startedASwait_started,
TIMEDIFF(NOW(),r.trx_wait_started) ASwait_age,
TIMESTAMPDIFF(
SECOND,r.trx_wait_started,
NOW()) ASwait_age_secs,rl.lock_tableASlocked_table,rl.lock_indexASlocked_index,rl.lock_typeASlocked_type,r.trx_idASwaiting_trx_id,r.trx_startedASwaiting_trx_started,
TIMEDIFF(NOW(),r.trx_started) ASwaiting_trx_age,r.trx_rows_lockedASwaiting_trx_rows_locked,r.trx_rows_modifiedASwaiting_trx_rows_modified,r.trx_mysql_thread_idASwaiting_pid,sys.format_statement(r.trx_query) ASwaiting_query,rl.lock_idASwaiting_lock_id,rl.lock_modeASwaiting_lock_mode,b.trx_idASblocking_trx_id,b.trx_mysql_thread_idASblocking_pid,sys.format_statement(b.trx_query) ASblocking_query,bl.lock_idASblocking_lock_id,bl.lock_modeASblocking_lock_mode,b.trx_startedASblocking_trx_started,
TIMEDIFF(NOW(),b.trx_started) ASblocking_trx_age,b.trx_rows_lockedASblocking_trx_rows_locked,b.trx_rows_modifiedASblocking_trx_rows_modified,
CONCAT(
‘KILL QUERY ‘,b.trx_mysql_thread_id
) ASsql_kill_blocking_query,
CONCAT(‘KILL ‘,b.trx_mysql_thread_id) ASsql_kill_blocking_connection
FROM
(
(
(
(information_schema.innodb_lock_waitsw
JOINinformation_schema.innodb_trxbON((b.trx_id=w.blocking_trx_id))
)
JOINinformation_schema.innodb_trxrON(
(r.trx_id=w.requesting_trx_id)
)
)
JOINinformation_schema.innodb_locksblON(
(bl.lock_id=w.blocking_lock_id
)
)
)
JOINinformation_schema.innodb_locksrlON(
(rl.lock_id=w.requested_lock_id
)
)
)
ORDER BYr.trx_wait_started
innodb_lock_waits和x$innodb_lock_waits区别
有心的同学可能会注意到,sys schema 里面有 innodb_lock_waits 和 x$innodb_lock_waits。 其实 sys schema 的这些视图大部分都成对出现,其中一个的名字除了 x$ 前缀以外跟另外一个是一模一样的。例如,host_summmary_by_file_io 视图分析汇总的是根据主机汇总的文件 IO 情况,并将延迟从皮秒( picoseconds )转换成更加易读值( 带单位 )显示出来:
mysql> SELECT * FROM host_summary_by_file_io;
+------------+-------+------------+
| host | ios | io_latency |
+------------+-------+------------+
| localhost | 67570 | 5.38 s |
| background | 3468 | 4.18 s |
+------------+-------+------------+
而 x$host_summary_by_file_io 视图分析汇总的是同样的数据,但是显示的是未格式化过的皮秒( picosecond )延迟值
mysql> SELECT * FROM x$host_summary_by_file_io;
+------------+-------+---------------+
| host | ios | io_latency |
+------------+-------+---------------+
| localhost | 67574 | 5380678125144 |
| background | 3474 | 4758696829416 |
+------------+-------+---------------+
没有 x$ 前缀的视图是为了提供更加友好,对人更加易读的输出格式。带 x$ 前缀的视图显示了数据原始格式,它方便其他工具基于这些数据进行自己的处理。需要了解非 x$ 和 x$ 视图的不同点的进一步信息。
Q&A
提问:sys schema 只是在 performance_schema 和 information_schema 之上创建视图和存储过程?
李春:对,sys schema 主要针对的其实是 iperformance schema,有部分 information schema 的表也会整理到 sys schema 中统一展现。
提问:运行 KILL 2 杀掉 2 线程?blocking_lock_mode: X 的 X 什么意思?
李春:blocking_lock_mode 的 X 是指 X 锁,exclusive 锁,排它锁,跟它对应的是 S 锁,共享锁。kill 2 是杀掉 2 号线程,这样可以将锁释放,让被锁的这个线程正常执行下去。
提问:可以放心的打开 performance_schema,为何不使用 performance_schema 再造一个 sys schema?
李春:performance schema 是 MySQL 采集数据库性能的存储空间。sys schema 其实只是对 performance schema 多个表 join 和整合。两者的定位有所不同,如果直接放在 performance schema 中,分不清哪些是基表,哪些是视图,会比较混淆。
提问:pt-query-digest 这些工具的有开始使用 sys schema 吗?
李春:没有,pt-query-digest 主要用于分析慢查和 tcpdump 的结果,跟 sys schema 的定位有部分重叠的地方,sys schema 会分析得更细,更内核,更偏底层一些,pt-query-digest 主要还是从慢查和 tcpdump 中抽取 SQL 来格式化展现。
提问:阿里这么多数据库实例,使用什么运维工具?分布式事务又是怎么解决的呢?
李春:阿里内部有非常多的运维工具,dbfree,idb 等,用于数据库资源池管理,数据库脱敏,开发测试库同步,数据库订正,表结构变更等。分布式事务主要通过业务上的修改去屏蔽掉,比如:电影买票并不是你选了座位和付款就必须在一个事务里面,抢票,选座,付款分别是自己的子事务,系统耦合性比较弱,相互通知解决问题。
提问:Oracle 有 v$,MySQL 有 x$ ?两个 $ 是完成相似功能的吗?
李春:MySQL 的 x$ 可以说是仿照 Oracle 的 v$ 来做的,但是目前离 Oracle 的那么强大的数据库诊断功能还有一些距离。
提问:数据库脱敏能否简单介绍下实现方式?
李春:开发测试人员无法访问线上数据库,需要通过一个专门的 idb 来访问,而 idb 系统每个字段都有密级定义,满足权限的才能被访问;这个系统页控制了用户是否可以访问某个表,可以访问数据表的行数,只有主管同意了,用户才能访问某个表的数据,并且加密数据是以*显示的。
相关阅读
(点击标题可直接阅读)
- MySQL 5.7 新特性大全和未来展望
- 为什么Uber宣布从Postgres切换到MySQL?
本文编辑王杰,技术原创文章欢迎通过公众号菜单「联系我们」进行投稿。投稿方向包括技术架构类文章、新技术及新实践等。通过的文章会在高可用架构公众号、微博、今日头条等多个媒体发表。投稿需同意相关文章在高可用架构首发。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

以上是关于性能优化利器:剖析MySQL 5.7新特征 sys schema的主要内容,如果未能解决你的问题,请参考以下文章
MySQL 5.7 sys.schema_redundant_indexes 优化案例