智能营销总部:大数据与海量数据的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能营销总部:大数据与海量数据的区别相关的知识,希望对你有一定的参考价值。
Spring中的数据访问,JdbcTemplate使用及源码分析
前言
本系列文章为事务专栏分析文章,整个事务分析专题将按下面这张图完成
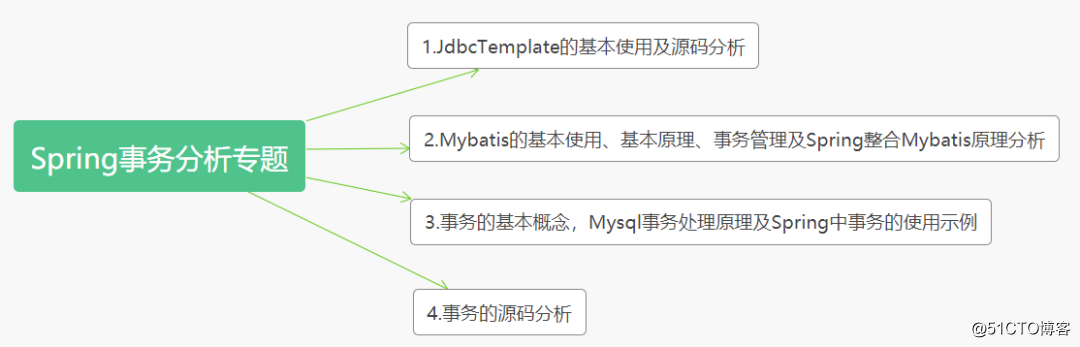
对源码分析前,我希望先介绍一下Spring中数据访问的相关内容,然后层层递进到事物的源码分析,主要分为两个部分
- JdbcTemplate使用及源码分析
- Mybatis的基本使用及Spring对Mybatis的整合
本文将要介绍的是第一点。
JdbcTemplate使用示例
public class DmzService {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
/**
* 查询
* @param id 根据id查询
* @return 对应idd的user对象
*/
public User getUserById(int id) {
return jdbcTemplate
.queryForObject("select * from `user` where id = ?", new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setAge(rs.getInt("age"));
user.setName(rs.getString("name"));
return user;
}
}, id);
}
public int saveUser(User user){
return jdbcTemplate.update("insert into user values(?,?,?)",
new Object[]{user.getId(),user.getName(),user.getAge()});
}
}public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext("tx.xml");
DmzService dmzService = cc.getBean(DmzService.class);
User userById = dmzService.getUserById(1);
System.out.println("查询的数据为:" + userById);
userById.setId(userById.getId() + 1);
int i = dmzService.saveUser(userById);
System.out.println("插入了" + i + "条数据");
}
}数据库中目前只有一条数据:
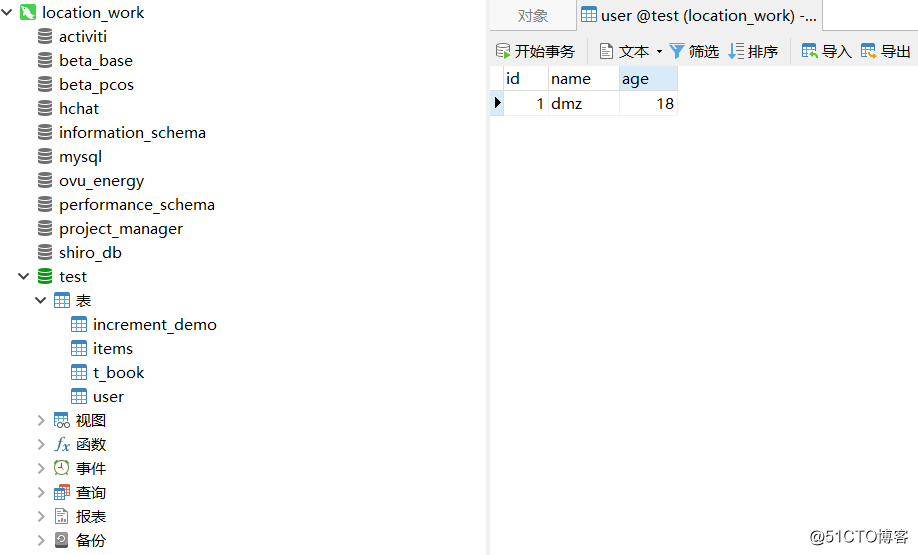
image-20200708153438245
配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="org.springframework.jdbc.datasource.DriverManagerDataSource" id="dataSource">
<property name="password" value="123"/>
<property name="username" value="root"/>
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://localhost:3306/test?serverTimezone=UTC"/>
</bean>
<bean id="dmzService" class="com.dmz.spring.tx.service.DmzService">
<property name="dataSource" ref="dataSource"/>
</bean>
</beans>程序允许结果:
查询的数据为:User{id=1, name=‘dmz‘, age=18}
插入了1条数据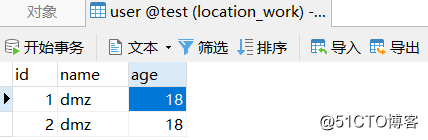
运行后数据库中确实插入了一条数据
对于JdbcTemplate的简单使用,建议大家还是要有一定熟悉,虽然我现在在项目中不会直接使用JdbcTemplate的API。本文关于使用不做过多介绍,主要目的是分析它底层的源码
JdbcTemplate源码分析
我们直接以其queryForObject方法为入口,对应源码如下:
queryForObject方法分析
public <T> T queryForObject(String sql, RowMapper<T> rowMapper, @Nullable Object... args) throws DataAccessException {
// 核心在这个query方法中
List<T> results = query(sql, args, new RowMapperResultSetExtractor<>(rowMapper, 1));
// 这个方法很简单,就是返回结果集中的数据
// 如果少于1条或者多余1条都报错
return DataAccessUtils.nullableSingleResult(results);
}query方法分析
// 第一步,对传入的参数进行封装,将参数封装成ArgumentPreparedStatementSetter
public <T> T query(String sql, @Nullable Object[] args, ResultSetExtractor<T> rse) throws DataAccessException {
return query(sql, newArgPreparedStatementSetter(args), rse);
}
// 第二步:对sql语句进行封装,将sql语句封装成SimplePreparedStatementCreator
public <T> T query(String sql, @Nullable PreparedStatementSetter pss, ResultSetExtractor<T> rse) throws DataAccessException {
return query(new SimplePreparedStatementCreator(sql), pss, rse);
}
public <T> T query(
PreparedStatementCreator psc, @Nullable final PreparedStatementSetter pss, final ResultSetExtractor<T> rse)
throws DataAccessException {
// query方法在完成对参数及sql语句的封装后,直接调用了execute方法
// execute方法是jdbcTemplate的基本API,不管是查询、更新还是保存
// 最终都会进入到这个方法中
return execute(psc, new PreparedStatementCallback<T>() {
@Override
@Nullable
public T doInPreparedStatement(PreparedStatement ps) throws SQLException {
ResultSet rs = null;
try {
if (pss != null) {
pss.setValues(ps);
}
rs = ps.executeQuery();
return rse.extractData(rs);
}
finally {
JdbcUtils.closeResultSet(rs);
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
}
});
}execute方法分析
// execute方法封装了一次数据库访问的基本操作
// 例如:获取连接,释放连接等
// 其定制化操作是通过传入的PreparedStatementCallback参数来实现的
public <T> T execute(PreparedStatementCreator psc, PreparedStatementCallback<T> action)
throws DataAccessException {
// 1.获取数据库连接
Connection con = DataSourceUtils.getConnection(obtainDataSource());
PreparedStatement ps = null;
try {
// 2.获取一个PreparedStatement,并应用用户设定的参数
ps = psc.createPreparedStatement(con);
applyStatementSettings(ps);
// 3.执行sql并返回结果
T result = action.doInPreparedStatement(ps);
// 4.处理警告
handleWarnings(ps);
return result;
}
catch (SQLException ex) {
// 出现异常的话,需要关闭数据库连接
if (psc instanceof ParameterDisposer) {
((ParameterDisposer) psc).cleanupParameters();
}
String sql = getSql(psc);
psc = null;
JdbcUtils.closeStatement(ps);
ps = null;
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw translateException("PreparedStatementCallback", sql, ex);
}
finally {
// 关闭资源
if (psc instanceof ParameterDisposer) {
((ParameterDisposer) psc).cleanupParameters();
}
JdbcUtils.closeStatement(ps);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}1、获取数据库连接
对应源码如下:
public static Connection getConnection(DataSource dataSource) throws CannotGetJdbcConnectionException {
// 这里省略了异常处理
// 直接调用了doGetConnection方法
return doGetConnection(dataSource);
}doGetConnection方法是最终获取连接的方法
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
// 如果使用了事务管理器来对事务进行管理(申明式事务跟编程式事务都依赖于事务管理器)
// 那么在开启事务时,Spring会提前绑定一个数据库连接到当前线程中
// 这里做的就是从当前线程中获取对应的连接池中的连接
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) {
// 记录当前这个连接被使用的次数,每次调用+1
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(fetchConnection(dataSource));
}
return conHolder.getConnection();
}
Connection con = fetchConnection(dataSource);
// 如果开启了一个空事务(例如事务的传播级别设置为SUPPORTS时,就会开启一个空事务)
// 会激活同步,那么在这里需要将连接绑定到当前线程
if (TransactionSynchronizationManager.isSynchronizationActive()) {
try {
ConnectionHolder holderToUse = conHolder;
if (holderToUse == null) {
holderToUse = new ConnectionHolder(con);
}
else {
holderToUse.setConnection(con);
}
// 当前连接被使用的次数+1(能进入到这个方法,说明这个连接是刚刚从连接池中获取到)
// 当释放资源时,只有被使用的次数归为0时才放回到连接池中
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(
new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
catch (RuntimeException ex) {
// 出现异常时释放连接,如果开启了事务,不会真正调用close方法关闭连接
// 而是把当前连接的使用数-1
releaseConnection(con, dataSource);
throw ex;
}
}
return con;
}2、应用用户设定的参数
protected void applyStatementSettings(Statement stmt) throws SQLException {
int fetchSize = getFetchSize();
if (fetchSize != -1) {
stmt.setFetchSize(fetchSize);
}
int maxRows = getMaxRows();
if (maxRows != -1) {
stmt.setMaxRows(maxRows);
}
DataSourceUtils.applyTimeout(stmt, getDataSource(), getQueryTimeout());
}从上面代码可以看出,主要设立了两个参数
- fetchSize:该参数的设计目的主要是为了减少网络交互,当访问ResultSet的时候,如果它每次只从服务器读取一条数据,则会产生大量的开销,setFetchSize的含义在于,当调用rs.next时,它可以直接从内存中获取而不需要网络交互,提高了效率。这个设置可能会被某些JDBC驱动忽略,而且设置过大会造成内存上升
- setMaxRows,是将此Statement生成的所有ResultSet的最大返回行数限定为指定数,作用类似于limit。
3、执行Sql
没啥好说的,底层其实就是调用了jdbc的一系列API
4、处理警告
也没啥好说的,处理Statement中的警告信息
protected void handleWarnings(Statement stmt) throws SQLException {
if (isIgnoreWarnings()) {
if (logger.isDebugEnabled()) {
SQLWarning warningToLog = stmt.getWarnings();
while (warningToLog != null) {
logger.debug("SQLWarning ignored: SQL state ‘" + warningToLog.getSQLState() + "‘, error code ‘" +
warningToLog.getErrorCode() + "‘, message [" + warningToLog.getMessage() + "]");
warningToLog = warningToLog.getNextWarning();
}
}
}
else {
handleWarnings(stmt.getWarnings());
}
}5、关闭资源
最终会调用到DataSourceUtils的doReleaseConnection方法,源码如下:
public static void doReleaseConnection(@Nullable Connection con, @Nullable DataSource dataSource) throws SQLException {
if (con == null) {
return;
}
if (dataSource != null) {
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && connectionEquals(conHolder, con)) {
// 说明开启了事务,那么不会调用close方法,之后将连接的占用数减1
conHolder.released();
return;
}
}
// 调用close方法关闭连接
doCloseConnection(con, dataSource);
}总结
总的来说,这篇文章涉及到的内容都是比较简单的,通过这篇文章是希望让大家对Spring中的数据访问有一定了解,相当于热身吧,后面的文章难度会加大,下篇文章我们将介绍更高级的数据访问,myBatis的使用以及基本原理、事务管理以及它跟Spring的整合原理。
如果本文对你有帮助的话,记得点个赞吧!
我叫DMZ,一个在学习路上匍匐前行的小菜鸟!

Spring官网阅读笔记
Spring杂谈
JVM系列文章
Spring源码专题

程序员DMZ
点赞、转发、在看,多谢多谢!
钟意作者
以上是关于智能营销总部:大数据与海量数据的区别的主要内容,如果未能解决你的问题,请参考以下文章