mysql 14 覆盖索引+回表
Posted 鑫男
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 14 覆盖索引+回表相关的知识,希望对你有一定的参考价值。
覆盖索引概念:
举个栗子,假如有一张表:tableA
t(id PK, name KEY, sex, flag); 即id是聚集索引,name是普通索引。
分别执行2条SQL
SQL1 : select id,name from tableA where name=\'shenjian\'
SQL2 : select id,name,sex from tableA where name=\'shenjian\'
结果是 SQL1查询速度极快,比SQL快很多,数据越多差异越明显,那这是为什么? 就因为多了一列?
这要从InnoDB的实现说起,
InnoDB有两大类索引:
-
聚集索引(clustered index)
-
普通索引 也叫非聚集索引(secondary index)
一张表必然有1个聚集索引(一颗B+树,叶子节点放的数据)
而普通索引的话,是在普通索引这颗B+树上,InnoDB普通索引的叶子节点存储主键值。
这是上面列子的表的聚簇索引,和普通索引
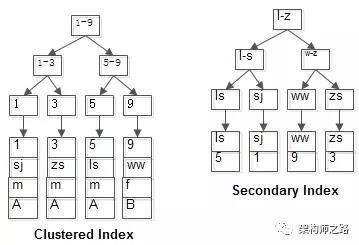
聚集索引图 非聚集索引(普通索引)图
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录(按页);
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
例如:
select * from t where name=\'lisi\' 是如何查找的呢
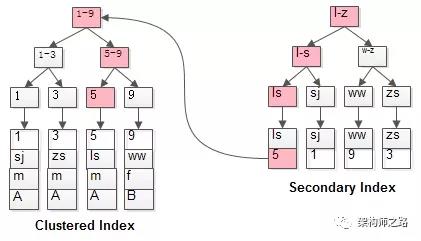
如粉红色路径,需要扫码两遍索引树:
(1)右边的树(普通索引),先通过普通索引定位到主键值id=5;
(2)在通过主键的值在聚集索引的树里定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
二、什么是索引覆盖****(Covering index)****?
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
覆盖索引其实是索引覆盖的意思,索引字段就已经囊括select查询的字段,即索引字段覆盖了需查询的字段。
三、如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
select id,name from user where name=\'shenjian\';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
作者:Harri2012
链接:https://www.jianshu.com/p/8991cbca3854
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于mysql 14 覆盖索引+回表的主要内容,如果未能解决你的问题,请参考以下文章