redis中的hash
Posted 刘珲的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis中的hash相关的知识,希望对你有一定的参考价值。
Redis 哈希(Hash)
hash哈希被称为字典(dictionary),Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点保存了字典中的一个键值对。实际上,Redis数据库底层也是采用哈希表来存储键值对的。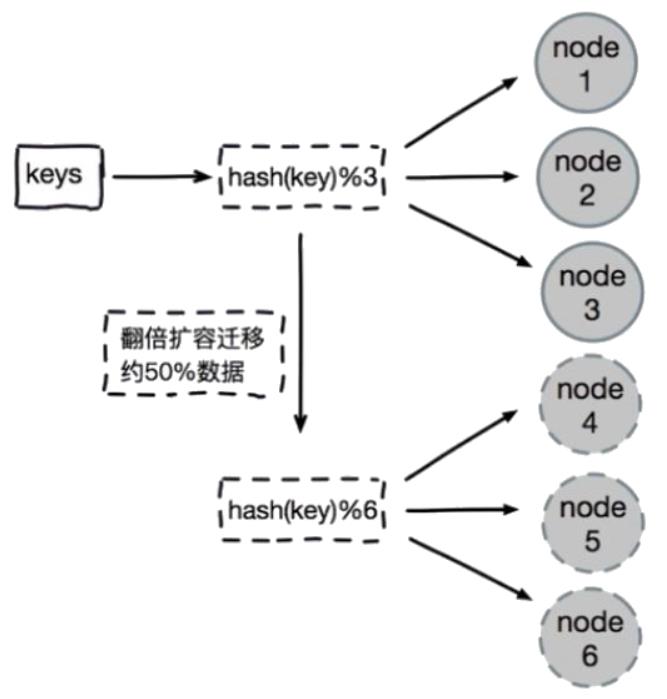
key-value键值对的键名key映射值相同时,系统会将这些键值value以单链表的形式保存,同时为了控制哈希表占用内存大小,Redis采用了双哈希表ht[2]结构,并逐步扩大哈希表容量的策略。注意,每对key-value在保存前会通过类似HASH(key) MOD N的方法计算出一个值,以确定在哈希表中所对应的位置。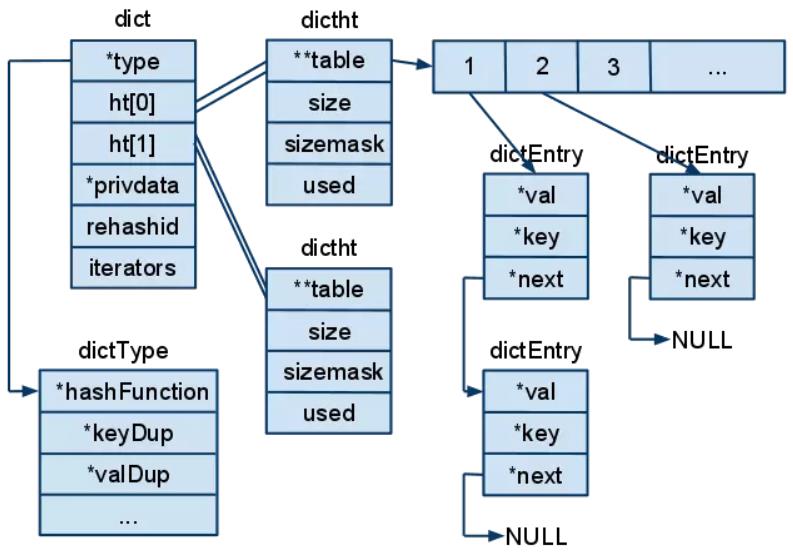
field则存储一条数据中的一个属性,字段值value是属性对应的值。每个哈希hash可存储2^32-1个键值对,约40多亿个。Redis中的哈希散列类型与Java中的HashMap相似,都是一组键值对的集合,并且支持单独对其中一个键进行增删改查操作。
为什么哈希更适合存储对象呢?
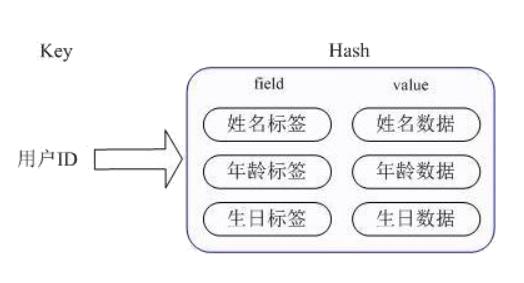
string字符串类型,进而将一个对象存储在hash类型中,这样会占用更少的内存并能更方便的存储整个对象。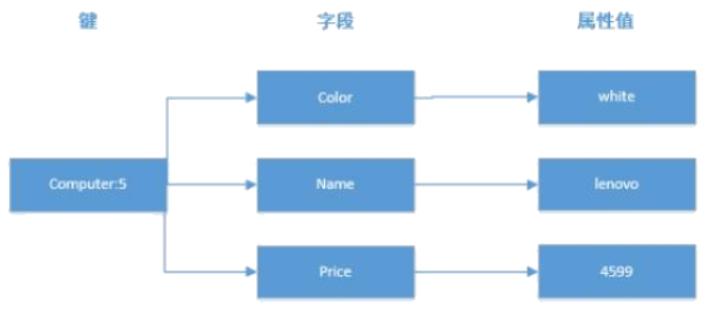
为什么使用哈希会更加节省内存呢?
Redis中的哈希散列是一个string类型的field和value的映射表,它的增删操作的复杂度平均为O(1)。为什么平均是O(1)呢?因为哈希的内部结构包含zipmap和hash两种。hash适合存储对象,相对于对象序列化存储为string字符串类型,将对象存储在hash哈希类型中会占用更少的内存。zipmap本身并不是hashtable,由于zip压缩后可以节省hash本身所需的元数据的开销。因此zipmap的增删改查的操作复杂度为O(n)。但是域字段field的数量不多,所以说平均是O(1)。那么,为什么会占用更好的内存呢?因为对象刚开始使用的是zipmap存储的。
在新建一个哈希的时候,使用的是zipmap又称为small hash存储的。这个zipmap实际上不是我们的哈希表。但是这个zipmap相比正常的哈希实现,节省很多哈希自身所需要的元数据的存储开销。尽管zipmap的增删改查和字段的数目相关,字段太多速度会更慢。因此不建议设置过多的字段。在Redis内部,如果字段过多或者存储的值太大超过限制后,Redis会自动将zipmap替换为正常的hash来实现。
在域字段field的数量在限制范围内,并且字段值value的长度大小系统限定的字节数,此时哈希类型是用zipmap存储的,所以会比较节省内存空间。
# 配置域字段最大个数限制
hash-max-zipmap-entries 512
# 配置字段值最大字节限制
hash-max-zipmap-value 64key会被压缩,否则将按照正常的哈希结构来存储。
hset key field value
- 将哈希表
key中的字段field的值设置为value,若key不存在则创建后赋值,若域field已存在则覆盖。 - Redis中
hset命令用于为哈希表中的字段赋值,如果哈希表不存在则创建并进行字段赋值,否则原字段值将被新字段值所覆盖。 - 若字段是哈希表中新建的字段且字段值设置成功则返回1,若哈希表中域字段已经存在且 旧值被新值覆盖成功则返回0。
$ redis-cli
127.0.0.1:6379> hset username "junchow"
(error) ERR wrong number of arguments for \'hset\' command
# 错误:set或map的size为0,一个没有值的set或map。
以上是关于redis中的hash的主要内容,如果未能解决你的问题,请参考以下文章