分布式缓存锁-- Redis
Posted 鞋破露脚尖儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式缓存锁-- Redis相关的知识,希望对你有一定的参考价值。
现在Redis基本上没家公司都在使用,只是各自使用的场景不以,但Redis最出名的还是做为缓存服务器,提搞服务器的的吞吐量,下面我们来围绕这个作为缓存做一个总结
今天的目标其实是Redis的分布式锁,但索性全部理一理吧,正好最近在找工作
SpringBoot2.0后默认使用lettuce作为底层操作Redis的客户端,它使用Netty进行网络 通信,lettuce的bug会导致netty堆外内存的溢出,netty默认使用的内存为-Xms300m,但是我们不可能去无限的加大这个内存来防止这个异常的发生
解决方案:1:升级lettuce客户端,2:切换使用jedis
当我们整合Redis时,这里给大家解释一下,无论lettuce还是jedis都是RedisTemplate底层操作Redis的依赖,SpringBoot自动配置的,我们只需要加入任一依赖,RedisTemplate就会被装配成功
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> </dependency>
缓存穿透即是查询一个数据库不存在的数据,我们并没有将null存入缓存,导致所有请求都会去查询数据库,一般网站攻击会采用的一种方式击垮对方的数据库,导致服务瘫痪
方案:即使数据库没有数据,我们也将数据存入Redis,设置较短的过期时间即可,二三分钟
缓存雪崩指的是,大量的缓存同时到期失效,全部请求连接数据库,压垮数据库
方案:雪崩的原因在于缓存中大量的缓存短时间内全部到期,我们只需要不让他们同时到期即可防止雪崩的发生,比如我们可以在原有失效时间的基础上增加一个随机的值,比如1到5分钟随机,这样每一个缓存的生命周期就会不一样,同时到期的几率就很难发生
缓存击穿指的是,单个缓存在高并发请求下(热点数据),突然缓存到期失效,全部请求压垮数据库,
解决方案:当前场景下,我们只有加锁,只让一个线程去连接数据库查询数据,其余线程全部处于等待状态,连接数据库的线程查询到数据库后,并将结果缓存到Reids之中,其余等待的线程全部去Redis中获取数据,不让其全部连接数据库
我们都知道SpringBoot的Bean都是单列的,所以这里我们使用这一特点进行上锁
@Service public class CourseServiceImpl implements CourseService { @Autowired private CourseMapper courseMapper; //springboot自动配置的,直接注入到类中即可使用 @Autowired private RedisTemplate<Object, Object> redisTemplate; /**指定key的序列化方式,字符串的方式*/ private RedisSerializer keyRedisSerializer = new StringRedisSerializer(); /**指定value的序列化方式,字符串的方式*/ private RedisSerializer valueRedisSerializer = new Jackson2JsonRedisSerializer<Course>(Course.class); /** * 查询所有课程信息,带有缓存 * * @return */ public List<Course> getAllCourse() { //KEY 是按照字符串方式序列化,可读性较好 redisTemplate.setKeySerializer(keyRedisSerializer); //获取缓存数据 List<Course> courseList = (List<Course>)redisTemplate.opsForValue().get("allCourse"); //如果缓存数据为空,此时并发请求 if (null == courseList) { //1000个请求, 999个等,1个进入 synchronized (this) { //双重就在这儿双重,再次去缓存中取数据,999个等待的线程都会在这里拿到数据 courseList = (List<course>)redisTemplate.opsForValue().get("allCourse"); //只有第获得锁的请求才会走下面查询数据库的操作 if (null == courseList) { courseList = coursetMapper.getAllCourse(); redisTemplate.opsForValue().set("allCourse", courseList); System.out.println("请求的数据库后将数据存入缓存"); //如果查到数据后放入缓存后直接return,这样999个线程获得锁就会从缓存中得到数据 return courseList; } else { System.out.println("请求的缓存"); } } } else { System.out.println("请求的缓存"); } return courseList; } }
在单体应用下,上面的代码已经可以防止缓存击穿问题,但是如果我们的服务是分布式的,这样就会有多个Spring容器,就会有多个Bean实例,明显上述的本地锁就会造成一个服务锁自己的请求,显得不合理
原理:这里我们使用redis作为分布式锁的中间件,就利用setnx的不可重复性即可实现,设想,加入我的课程服务一共安排了10台机器,为了避免缓存击穿,我们需要这10台机器上的线程使用同一把锁,我们就使用Redis的setnx即可实现,setnx里面的数据时不可重复的,一个线程setnx进去后,其他线程就stnx不进去相同的值了,我们以谁setnx返回的布尔值为确定谁获得锁,
可能面对的问题:
死锁问题:锁是抢到了,如果在执行业务代码中抛出异常或者在释放锁之前网络等问题,造成没有删掉我们设置的锁值,导致锁一直未被释放,形成死锁,还有就是我们在获取锁、已经设置锁的过期时间应该是原子性,不然获取到锁,再去设置过期时间期间,发生问题,那也会造成死锁问题,这个redis的api已经解决了
解决方案:抢占锁时设置自动过期时间,原子操作
Boolean lock = redisTemplaet.opsForValue().setIfAbsent("lock","hello",300,TimeUnit.SECONDS);
服务超时问题:加入我们的程序代码比较耗时,耗时已经超过我们上锁的时间阀值,导致锁自动释放,更多请求获取到锁,然后耗时业务执行完毕,删除我们约定好的锁,相当于释放当前所有锁,此时锁已经失效,无法锁住
解决方案:之前我们都setIfAbsent("lock","hello",300,TimeUnit.SECONDS);lock的value固定为hello,是有问题的,就会造成上面那种情况,此时我们不用固定值,采用UUID生成随机值,在释放锁时,先查询当前lock的值,如果为当前我们预设的UUID,则删除,如果不是,说明锁已经过期,自动释放,解决方案如下所示
第一个就是加长锁的生命周期,起码得保证,生命时长超过业务耗时时长吧,但分布式中,服务调用之间耗时的不稳定性,导致我们这个时长的设置也不稳定,太长了吧,影响吞吐,太断了又自动释放,所以这不是一个好解决方案
第二个方案就是锁的自动续命策略,下面我们再详细说明,主要是Redisson的看门狗策略
删锁时机问题:和我们设置值且原子操作值的有效时间一个道理,当我们准备业务执行完毕准备删除锁的时候,先获取lock的值UUID,对比和我们的预先设置的UUID是否相同,如果相同再删除,如果再比较的过程中,该lock生命到期,自动删除,我们删除的lock其实是别人的UUID,这就要求,我们获取lock的值判断和删除lock的操作是原子性的
解决方案:Lua脚本解锁
Redis 使用单个 Lua 解释器去运行所有脚本,并且, Redis 也保证脚本会以原子性(atomic)的方式执行: 当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。
下面这个语句我做一个解释吧,
execute函数接受三个参数,一个lua脚本,一个删除key集合,一个删除key对应value的值
Lua脚本的唯一实现类DefaultRedisScript,泛型指定为删除成功或者失败返回的类型
脚本字符串,执行脚本之后的返回数据类型,删除的话,成功是1,失败为0
这个得根据命令执行的返回值确定,Integer会包类型转换异常,切换时Long正常
调用execute函数时,会将key:lock,写入到脚本中KEYS[1],会将value:uuid,写入到脚本ARGV[1]
//官方给的lua脚本String script = "if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end" //删除锁 Long lock = redisTemplate.execute(new DefaultRedisScript<Long>(script,Long.class),Araays.asList("lock"),uuid);
SpringBoot集成更多详细信息: Go Redisson
<!--以后使用redisson作为所有分布式锁,分布式对象等功能的框架--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version> </dependency>
/** * @Description redisson的程序化配置 * @Author Ninja * @Date 2020/7/25 **/ @Configuration public class RedissonConfig { @Bean(destroyMethod="shutdown") public RedissonClient redisson(){ Config config = new Config(); // config.useClusterServers().addNodeAddress("192.168.29.130:6379","192.168.29.140:6379") //当前为单机模式 config.useSingleServer().setAddress("redis://192.168.29.130:6379"); config.useSingleServer().setPassword("123456"); return Redisson.create(config); } }
@Autowired private RedissonClient redissonClient;
基于Redis的Redisson分布式可重入锁RLoc,Java对象实现了java.util.concurrent.locks.Lock接口
RLock lock = redisson.getLock("my_lock"); // 上锁,阻塞式等待 lock.lock();
上述代码中,我们上锁,并没有指定锁的失效时间,默认是30秒,Redisson内部提供了一个监控锁的看门狗,当我们的业务耗时较长超过锁的生命周期时,看门狗会我们的锁续命,这一点可以在redis的客户端中刷新看生命周期观察得到,所以这就不会出现:因为业务耗时过长,导致锁的自动释放带来的问题,而且就算我们不主动解锁,Redisson也会在我们线程执行之后30S内自动释放该锁,这里就不会出现死锁问题
如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
// 加锁以后10秒钟自动解锁 // 无需调用unlock方法手动解锁 lock.lock(10, TimeUnit.SECONDS); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); if (res) { try { ... } finally { //解锁 lock.unlock(); } }
Redisson同时还为分布式锁提供了异步执行的相关方法:
RLock lock = redisson.getLock("anyLock"); lock.lockAsync(); lock.lockAsync(10, TimeUnit.SECONDS); Future<Boolean> res = lock.tryLockAsync(100, 10, TimeUnit.SECONDS);
RLock对象完全符合Java的Lock规范。也就是说只有拥有锁的进程才能解锁,其他进程解锁则会抛出IllegalMonitorStateException错误。但是如果遇到需要其他进程也能解锁的情况,请使用分布式信号量Semaphore 对象.
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
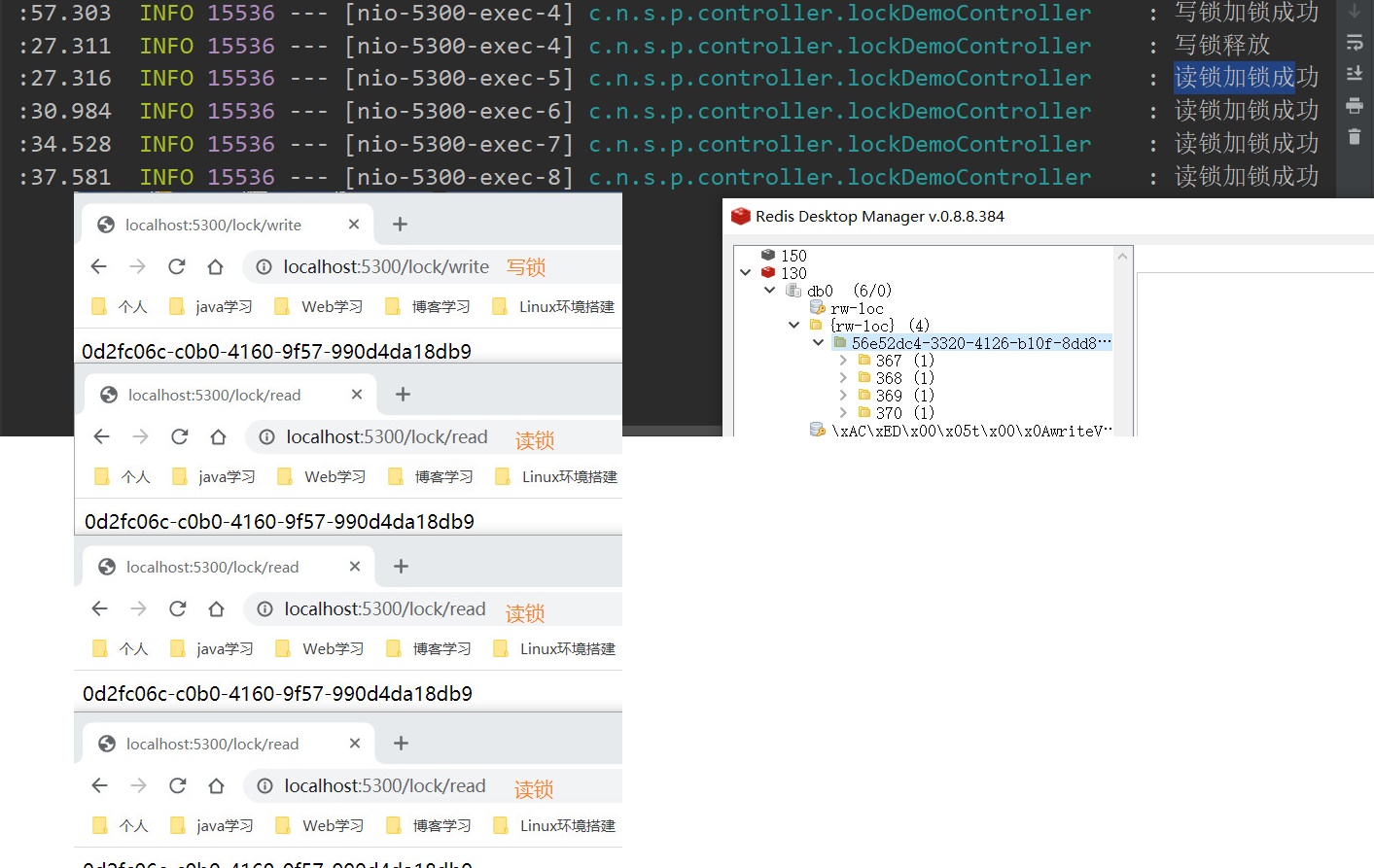
@GetMapping("/read") @ResponseBody public String redValue(){ String uuid = null; RReadWriteLock readLock = redissonClient.getReadWriteLock("rw-loc"); RLock lock = readLock.readLock(); lock.lock(); try { log.info("读锁加锁成功"); uuid = (String) redisTemplate.opsForValue().get("writeValue"); Thread.sleep(30000); } catch (Exception e) { e.printStackTrace(); }finally { lock.unlock(); log.info("读锁释放"); } return uuid; } @GetMapping("/write") @ResponseBody public String writeValue(){ RReadWriteLock writeLock = redissonClient.getReadWriteLock("rw-loc"); String uuid = null; RLock lock = writeLock.writeLock(); lock.lock(); try { log.info("写锁加锁成功"); uuid = UUID.randomUUID().toString(); redisTemplate.opsForValue().set("writeValue",uuid); Thread.sleep(30000); } catch (Exception e) { e.printStackTrace(); }finally { lock.unlock(); log.info("写锁释放"); } return uuid; }
可以发现
写锁是一个排他锁(互斥锁),二读锁是一个共享锁
只要有写锁的存在,就会发生互斥
写 + 写 : 阻塞方式
读 + 写 :写阻塞,等待读释放锁
写 + 读 :读阻塞,等待写锁释放
读 + 读 :相当于无锁,不是排他锁,全部上锁成功
就比如小学关校门吧,加入有五个班,当五个班都走了之后,才能关校门,下面我们用代码来掩饰一下
@GetMapping("/closedoor") @ResponseBody public String closeDoor() throws InterruptedException { RCountDownLatch door = redissonClient.getCountDownLatch("door"); door.trySetCount(5);//代表有五个班级,我必须收到五个班级的回应 log.info("放学铃声响起,等待五个班级学生离开校园"); door.await(); log.info("确认五个班级已经全部走完"); return "开始关闭校门,学生禁止出入"; } //模拟学生回家,id为班级号 @GetMapping("/gohome/{id}") @ResponseBody public String goHome(@PathVariable Integer id){ RCountDownLatch door = redissonClient.getCountDownLatch("door"); door.countDown(); //回应一下 log.info(id + "班的学生已经回家了"); return id + "班的学生已经回家了"; }
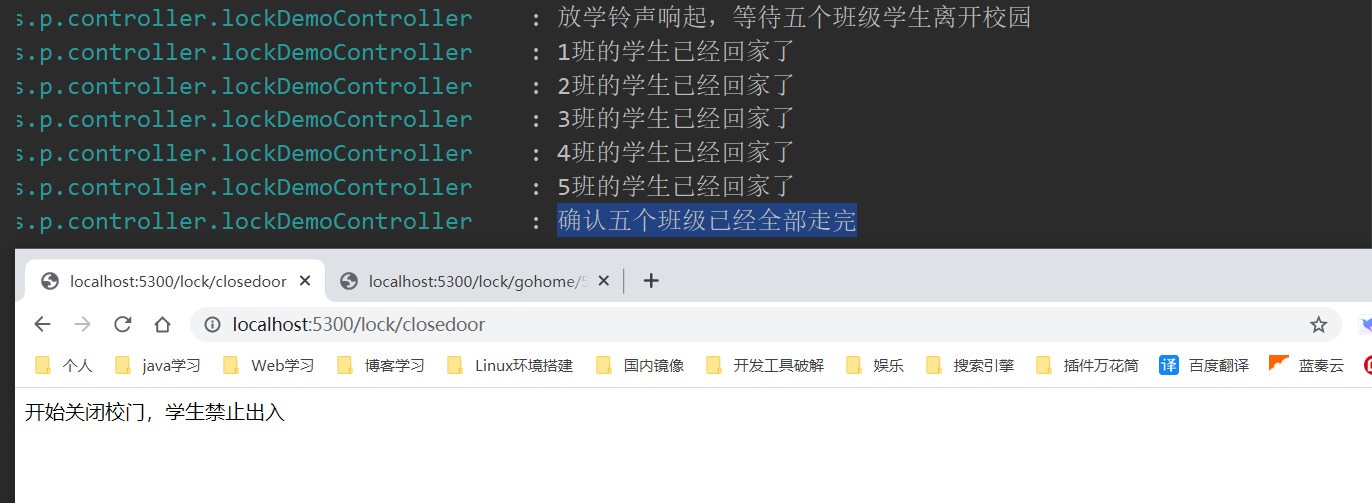
可以通过Redis的客户端观察到Reids内部有一个可以为door,有一个值Value被我们初始化为5,没当调用door.countDown();函数的时候,那个Value值就会减1操作,直到变为0时,闭锁释放,执行
我们用代码来模拟一个场景,一群乞丐等着小姑娘给他们做馒头吃,做一个就可以吃一个,没有做出来,就只有吃泥巴
@GetMapping("/build") @ResponseBody public String build(){ RSemaphore pack = redissonClient.getSemaphore("bread"); pack.release(); //做一个馒头,只做一个 return "OK"; } @GetMapping("/eat") @ResponseBody public String eat() throws InterruptedException { RSemaphore pack = redissonClient.getSemaphore("bread"); //获取一个馒头,没有馒头一直等着饿死算球 //pack.acquire(); //尝试获取馒头,不会堵塞,获取不到馒头就去挖泥巴吃 boolean flag = pack.tryAcquire(); return flag ? "馒头好香!!" : "还是继续吃泥巴吧!!"; }
我们可以先调用build接口,多做几个馒头,就会发现Redis中有个key为bread,值为我们访问接口的次数,也就是有几个馒头备货,然后调用下面的eat接口,可以发现redis中bread的值会递减,当捡到为0的时候,根据我们的api,要么处于堵塞,等待馒头做出来,要么获得布尔值,直接响应false
可以访问官网
先说两种方案,然后我们再总结一下大致上的解决方案
数据更新,写数据库,写缓存,也就是直接吧缓存读出来更新后再保存回去
两个请求模拟场景
A请求写入数据库,然后准备写入缓存的时候发生了卡顿
B请求写入数据库,然后写入缓存,此时卡顿的A请求继续完成写入缓存的操作,此时缓存中的数据为A请求带来的数据,产生了脏数据
脏数据的话,只是暂时的脏数据问题,在缓存过期或者数据稳定的时候会自动解决掉这个问题,会得到正确的数据
我们数据更新,写入数据库,然后把缓存删掉即可,下次查询更新缓存
三个线程模拟场景
A线程,写入数据库,删除缓存完成
B线程,写入数据库发生卡顿,
C线程,读取缓存,发现缓存没有,因为A线程写入后删掉了,然后C线程去连接数据库查询数据
如果运行比较顺利,他会读取A线程的老数据,并将其写入到缓存中
如果运行卡顿一点,此时B线程写入数据库成功,并将最新数据加载到缓存,但是C线程会将读取的老数据对B线程的最新缓存产生覆盖问题
无论是双写模式,还是失效模式,缓存数据都会有不一致问题,
我们放入缓存的数据本来就应该对实时性的要求不能太严格,对实时性要求超高的,我们建议还是直接查询数据库,对于实时性要求不是很高的,我们应该设置过期时间,以确保隔断时间能拿到最新的数据
通过加锁的方式保证并发读写,写写的时候按照阻塞的方式排队进行写,读取就无所谓啦,所以应该考虑考虑适当的运用上面我说过的分布式读写锁来控制并发读写带来的数据不一致问题,当然如果你的数据长期处于频繁写的状态,我们建议还是不要加缓存,或者缓存的生命周期短一点,可能随时都不是最新的数据,哈哈哈
相关依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency>
配置文件,其他配置,根据项目而定
spring
启动类开启注解功能,就可以使用注解完成缓存的操作了
//每一个需要缓存的数据,我们都来指定他存放的缓存区 //缓存的分区可以根据业务来划分,不是Redis的key哦 //默认key是自动生成的 //默认生命周期为-1,表示永远不过期 //存储的value值采用的是jdk的序列化机制,将序列化后的数据存入到redis //而且当我们访问这个接口的时候,会优先访问缓存。如果缓存中有数据,直接就返回了,而不是执行函数 @Cacheable("course") @GetMapping("/create") @ResponseBody public String cacheCreate() { System.out.println("模拟查询数据库"); return "Hello World"; }
该注解可以自动将函数的返回值,缓存起来,如果缓存中有值,是不会走方法的,直接返回
//自定义key key = "" :该函数的名字 // 自定义生命周期 在配置文件中配置,并将其写入配置类中 // 自定义序列化为json,也是通过配置类 //如果想自定义key,可以为: "\'keyName\'",默认是表达式取值,直接"keyName"不行 //解决缓存击穿问题,在Cacheable注解中,配置sync = true,获取时加锁,但只是本地锁,不是分布式锁 @Cacheable(value = "course" , key = "#root.method.name") @GetMapping("/custom") @ResponseBody public UserTest customKeyName() { System.out.println("模拟查询数据库"); UserTest user = new UserTest("张三", 23); return user; } 配置类如下所示 /** * @Description * @Author Ninja * @Date 2020/7/25 **/ @Configuration @EnableCaching //属性读入一个配置类,下面可以使用,读取的spring cache下面的属性 //我们只配置了生命周期,通过Redis客户端发现已经生效了,更多配置,直接在配置文件中配置即可 @EnableConfigurationProperties(CacheProperties.class) public class MyCacheConfig { //配置redis @Bean RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())); config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericFastJsonRedisSerializer())); CacheProperties.Redis redisProperties = cacheProperties.getRedis(); if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive()); } if (redisProperties.getKeyPrefix() != null) { config = config.prefixKeysWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) { config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) { config = config.disableKeyPrefix(); } return config; } }

该注解是失效模式,即当删除数据时,会根据分区和key,将缓存一起干掉,详细看下方代码
//自定义key key = "" :该函数的名字 // 自定义生命周期 在配置文件中配置,并将其写入配置类中 // 自定义序列化为json,也是通过配置类 //如果想自定义key,可以为: "\'keyName\'",默认是表达式取值,直接"keyName"不行 @Cacheable(value = "course" , key = "\'userTest1\'") @GetMapping("/custom1") @ResponseBody public UserTest userTest1() { System.out.println("模拟查询数据库"); UserTest user = new UserTest(1,"userTest1", 1); return user; } @Cacheable(value = "course" , key = "\'userTest2\'") @GetMapping("/custom2") @ResponseBody public UserTest userTest2() { System.out.println("模拟查询数据库"); UserTest user = new UserTest(2,"userTest2", 2); return user; } //CacheEvict 失效模式,修改时直接删除缓存 //注意分区和key是用来定位缓存中的数据的,一定要匹配好 //@CacheEvict有个属性 allentrise = false,该为true,表示删除该分区下所有缓存 @CacheEvict(value = "course" , key = "\'userTest1\'") @PutMapping("/update") @ResponseBody public String updateUser1() { System.out.println("执行了删除程序"); return "Ok"; } //加入一个操作会级联删除多个缓存 : @Caching注解 @Caching( evict = { @CacheEvict(value = "course" , key = "\'userTest1\'"), @CacheEvict(value = "course" , key = "\'userTest2\'") } ) @PutMapping("/updateAny") @ResponseBody public String updateAny() { System.out.println("模拟删除 : userTest1"); System.out.println("模拟删除 : userTest2"); return "Ok"; }
//CachePut 双写模式,当修改某个数据后,如果有返回(最新数据),将返回存入缓存 @CachePut(value = "course" , key = "\'userTest2\'") @PutMapping("/update2") @ResponseBody public UserTest updateUser2() { UserTest user = new UserTest(22,"userTest22", 22); return user; }
想要get到它的不足,首先就要看他是否解决我们面对的问题,我们的问题大部分区分为两个问题,一个是读面对的问题:缓存穿透、缓存击穿、缓存雪崩,另一个就是写的问题,面对的问题就是缓存数据和真实数据的不一致性,主要方案为读写锁使用、Canal中间件实现数据库一致性(有点像logstash)、如果读多写也多,那就只有直接拜访数据库了
-
缓存穿透:查询一个并不存在的数据,缓存失效,压垮数据库
cache-null-values: true #是否储存null值,开启后解决缓存穿透问题
-
缓存击穿:某个key失效时,高并发查询请求,压垮数据库
加锁?之前我们说到单体应用中的双重检测锁可以预防单体应用的缓存击穿问题,而分布式的缓存击穿问题,我们则要运用上面讲到过的分布式锁,可是在Spring Cache中,当我们的缓存为Redis时,RedisCache底层默认是没有任何加锁操作的,通过我们的配置在Cacheable注解中,sync = true,获取时加锁,没有其余任何的锁操作,而这个锁操作也是本地锁,并不是分布式锁,原理就是获取时获取加上一把本地锁,一个线程去获取数据,获取后将数据缓存起来,其他堵塞线程去访问缓存,相当于就是在本地配置了一个双重检测锁
-
缓存雪崩:大量key失效,高并发压垮数据库
错开缓存时间,只要保证不在短期集体失效即可
或者设置永不失效,但要做好数据一致性防护措施
常规数据:(读多写少,即时性、一致性要求不是很高的数据,Spring Cache完全可以胜任)
针对一些即时性和一致性要求高的,
-
要么配合缓存生命周期配置,
-
要么使用类似于logstash的中间件Canal
-
要么直接查询数据库
以上是关于分布式缓存锁-- Redis的主要内容,如果未能解决你的问题,请参考以下文章