使用InfluxDB的连续查询解决聚合性能问题
Posted 大墨垂杨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用InfluxDB的连续查询解决聚合性能问题相关的知识,希望对你有一定的参考价值。
==背景==
数据库:我们的生产环境中有一个设备运行的数据库使用的是InfluxDB,这里面存储了所有设备上报上来的实时运行数据,数据量增速较快。
功能需求:产品有一个叫趋势分析的功能,用来按照不同的算子(mean、max等),不同的时间段(1分钟、30分钟)等对数据进行聚合。
==版本==
1.7.1、单机版
==问题==
经过压力测试之后,发现当聚合时间选择1分钟、5分钟等细粒度的时间的是偶,聚合的速度非常的慢。
概括一句话:基于原始数据进行实时聚合,不合理
==解决思路==
InfluxDB提供了连续查询的高级功能,尝试在每天凌晨的时候将数据聚合好,
官方文档:https://docs.influxdata.com/influxdb/v1.7/query_language/continuous_queries/
强烈建议把官方文档从头到尾浏览一遍,是学习一门技术最好的入门方法。
==初次尝试==
1、创建存储聚合结果的数据库
create database rexel_analysis
2、为数据库创建保存策略
设置数据留存时间为1年(365天)。
create retention policy one_year on rexel_analysis duration 365d replication 1 default
3、创建数据库权限
出于安全考虑,为数据库做了ACL权限。
GRANT read ON rexel_analysis TO devread
GRANT write ON rexel_analysis TO devwrite
GRANT all ON rexel_analysis TO devall
4、创建一个连续查询
CREATE CONTINUOUS QUERY cq_mean_1m ON rexel_private BEGIN SELECT mean(*) INTO rexel_analysis.one_year.data_up_1m FROM rexel_private.one_year.device_data_up GROUP BY time(1m) END
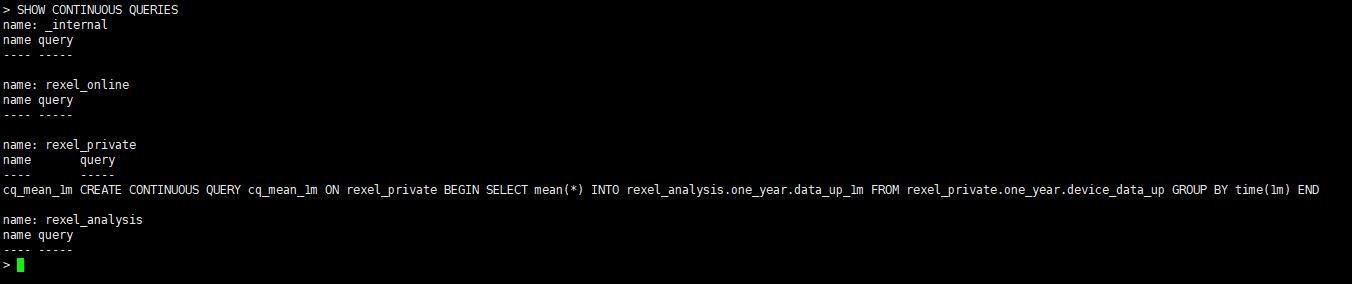
5、查看已有连续查询
SHOW CONTINUOUS QUERIES
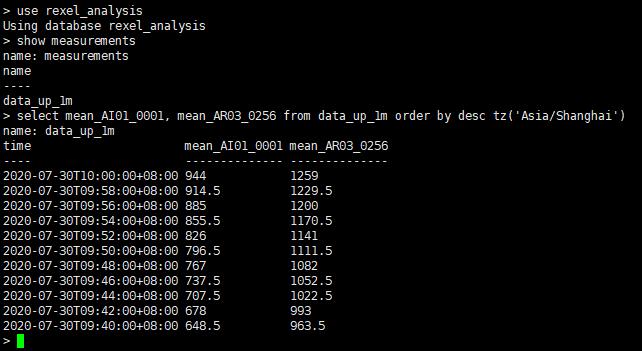
6、查看连续查询的计算结果
从结果上可以看到,连续查询按照我预设的每分钟执行1次,并将结果插入到了另一个数据库中。
use rexel_analysis show measurements select mean_AI01_0001, mean_AR03_0256 from data_up_1m order by desc tz(\'Asia/Shanghai\')
7、删除连续查询
DROP CONTINUOUS QUERY cq_mean_1m ON rexel_private
8、修改连续查询
根据官网的介绍,创建CQ之后,无法进行更改,如果需要更改需要drop掉之后重新create。
9、查询连续查询的日志
待补充
==初次尝试体验==
以上是初次尝试InfluxDB的连续查询的过程,有几个体验:
【好的体验】
1、可以看到连续查询会按照指定的时间计划对数据进行聚合,并将结果保存到指定的地方,是一个很好的解决性能的思路。
2、表中的字段有好几千个,使用带有通配符(*)的函数和INTO查询的反向引用语法,可以自动对数据库中所有度量和数字字段中的数据进行降采样。
【不好的体验】
1、每次连续查询时间间隔很短(时间间隔 = now() - group by time())
2、查询结果的字段别名比较恶心,比如原来字段叫AI01_0001,因为计算的是mean,结果库中的字段名就变为了mean_AI01_0001。
==配置采样频率与时间范围==
连续查询提供了高级语法:RESAMPLE EVERY FOR
CREATE CONTINUOUS QUERY <cq_name> ON <database_name> [RESAMPLE [EVERY <interval>] [FOR <interval>]] BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement> FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>] END
RESAMPLE EVERY :采样执行频次。如RESAMPLE EVERY 30m:表示30分钟执行一次。
RESAMPLE FOR :采样时间范围。如RESAMPLE FOR 60m:时间范围 = now() - for间隔(60m)。
RESAMPLE EVERY 30m FOR 60m:表示每30分钟执行一次60分钟内的数据计算。
注意:
如果此时在<cq_query>中使用了GROUP BY time duration,那么FOR定义的duration必须大于或者等于GROUP BY指定的time duration,不然就会报错。
反过来,如果EVERY定义的duration 大于GROUP BY指定的time duration,那么执行将按照EVERY定义的duration来执行。
例如:如果GROUP BY time(5m)且EVERY间隔为10m,则CQ每十分钟执行一次
==语句样例==
每1分钟执行1次平均值计算,时间范围1分钟 CREATE CONTINUOUS QUERY cq_mean_1m ON rexel_private BEGIN SELECT mean(*) INTO rexel_analysis.one_year.data_up_1m FROM rexel_private.one_year.device_data_up GROUP BY time(1m) END 每1分钟执行1次平均值计算,时间范围1天 CREATE CONTINUOUS QUERY cq_mean_1m ON rexel_private RESAMPLE FOR 1d BEGIN SELECT mean(*) INTO rexel_analysis.one_year.data_up_1m FROM rexel_private.one_year.device_data_up GROUP BY time(1m) END
==项目实践==
经过上面一番体验之后,对连续查询已经有了基本的了解,那么实际中如何使用呢?
我们的场景:
1、可选的时间组(共8个):1分钟、5分钟、30分钟、1小时、6小时、12小时、1天、1周
2、可选的聚合模式(共8个):最老值(last)、最新值(first)、最大值(max)、最小值(min)、平均值(mean)、中间值(median)、极差值(spread)、累加值(sum)
3、时间范围:最多3个月

那么,连续查询策略该如何设计呢?
【方案一】
按照时间组和聚合模式的排列组合创建查询策略。如下图所示,这种方案一共需要创建64个连续查询,感觉有些啰嗦。

【方案二】
按照和时间组创建查询策略。如下图所以,每一行的查询策略是一样的,各个聚合方法的结果放在同一张表中。
这样减少了连续查询的数量,维护也方便了很多。

表中的数据大概是这个样子的
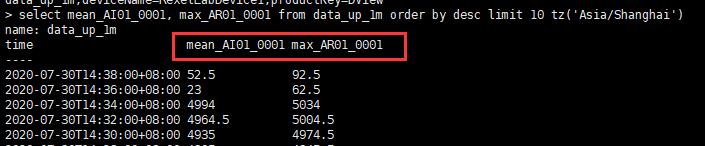
【方案三】
将方案二工具化,在mysql中创建一个关于influxdb连续查询的字典表,根据这个表来自动创建连续查询。(思想:让机器做的更多)
建表语句及数据如下:
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for influx_cq_dict -- ---------------------------- DROP TABLE IF EXISTS `influx_cq_dict`; CREATE TABLE `influx_cq_dict` ( `cq_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'连续查询的名称\', `from_database` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'源数据库\', `from_retention_policy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'源存储策略\', `from_measurement` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'源表名\', `to_database` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'目标数据库\', `to_retention_policy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'目标存储策略\', `to_measurement` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'目标表名\', `for_interval` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'时间间隔\', `every` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT \'执行频率\', `field` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'查询字段\', `func` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'聚合功能\', `group_by_time` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'GROUP BY指定的time duration\', `fill` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT \'空白填充方式\', `is_delete` varchar(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT \'0\' COMMENT \'是否删除 0,未删除;1:删除\', PRIMARY KEY (`cq_name`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 146 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = \'InfluxDB连续查询字典表\' ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of influx_cq_dict -- ---------------------------- INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_12h\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_12h\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'12h\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_1d\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_1d\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'1d\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_1h\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_1h\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'1h\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_1m\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_1m\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'1m\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_1w\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_1w\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'1w\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_30m\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_30m\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'30m\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_5m\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_5m\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'5m\', \'none\', \'0\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_5m_test\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_5m_test\', \'1h\', \'5m\', \'AI01_0001,AI01_0002\', \'last,first,max,min,mean,median,spread,sum\', \'5m\', \'none\', \'1\'); INSERT INTO `influx_cq_dict` VALUES (\'cq_device_data_up_6h\', \'rexel_online\', \'one_year\', \'device_data_up\', \'rexel_online_analysis\', \'one_year\', \'device_data_up_6h\', \'1d\', \'1d\', \'*\', \'last,first,max,min,mean,median,spread,sum\', \'6h\', \'none\', \'0\'); SET FOREIGN_KEY_CHECKS = 1;
==Java代码==
1、Controller类
package com.rexel.backstage.project.tool.init.controller; import com.rexel.backstage.project.tool.init.service.IInfluxCqDictService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import com.rexel.backstage.framework.web.controller.BaseController; import com.rexel.backstage.framework.web.domain.AjaxResult; /** * InfluxDB连续查询Controller * * @date 2020-07-30 */ @RestController @RequestMapping("/rexel/tool/influx/continuousQuery") public class InfluxCqDictController extends BaseController { private IInfluxCqDictService influxCqDictService; @Autowired public void setInfluxCqDictService(IInfluxCqDictService influxCqDictService) { this.influxCqDictService = influxCqDictService; } /** * 创建InfluxDB连续查询 */ @PostMapping("/refresh") public AjaxResult refresh(@RequestParam("type") String type) { return AjaxResult.success(influxCqDictService.refreshContinuousQuery(type)); } }
2、Service接口类
package com.rexel.backstage.project.tool.init.service; import com.alibaba.fastjson.JSONObject; /** * InfluxDB连续查询Service接口 * * @author admin * @date 2020-07-30 */ public interface IInfluxCqDictService { /** * 刷新InfluxDB连续查询 * * @param type create/drop * @return 结果 */ JSONObject refreshContinuousQuery(String type); }
3、Service实现类
package com.rexel.backstage.project.tool.init.service.impl; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import com.rexel.backstage.project.tool.init.domain.InfluxCqDict; import com.rexel.backstage.project.tool.init.mapper.InfluxCqDictMapper; import com.rexel.backstage.project.tool.init.service.IInfluxCqDictService; import com.rexel.influxdb.InfluxUtils; import com.rexel.influxdb.constans.InfluxSql; import java.util.ArrayList; import java.util.List; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; /** * InfluxDB连续查询Service业务层处理 * * @author admin * @date 2020-07-30 */ @Service @Slf4j public class InfluxCqDictServiceImpl implements IInfluxCqDictService { private InfluxUtils influxUtils = InfluxUtils.getInstance(); private InfluxCqDictMapper influxCqDictMapper; private List<InfluxCqDict> influxCqDictList; private final static String INIT = "init"; private final static String DROP = "drop"; private final static String CREATE = "create"; @Autowired public void setInfluxCqDictMapper(InfluxCqDictMapper influxCqDictMapper) { this.influxCqDictMapper = influxCqDictMapper; } /** * 刷新InfluxDB连续查询 * * @return 结果 */ @Override public JSONObject refreshContinuousQuery(String type) { influxCqDictList = influxCqDictMapper.selectInfluxCqDictList(); // 首次 if (INIT.toLowerCase().equals(type.toLowerCase())) { recreateDatabase(); dropAllCp(); createAllCp(); } // 删除 if (DROP.toLowerCase().equals(type.toLowerCase())) { dropAllCp(); } // 创建 if (CREATE.toLowerCase().equals(type.toLowerCase())) { dropAllCp(); createAllCp(); } return new JSONObject(); } /** * 获取源数据库列表 * * @return 列表 */ private List<String> getDatabaseFrom() { List<String> result = new ArrayList<>(); for(InfluxCqDict influxCqDict : influxCqDictList) { String database = influxCqDict.getFromDatabase(); if (!result.contains(database)) { result.add(database); } } return result; } /** * 获取目标数据库列表 * * @return 列表 */ private List<String> getDatabaseTo() { List<String> result = new ArrayList<>(); for(InfluxCqDict influxCqDict : influxCqDictList) { String database = influxCqDict.getToDatabase(); if (!result.contains(database)) { result.add(database); } } return result; } /** * 重新创建database */ private void recreateDatabase() { List<String> dbList = getDatabaseTo(); for(String database : dbList) { influxUtils.dropDatabase(database); influxUtils.createDatabase(database); influxUtils.createRetentionPolicy(database); } } /** * 删除所有连续查询 */ private void dropAllCp() { JSONArray jsonArray = influxUtils.getContinuousQueries(); List<String> dbList = getDatabaseFrom(); for(String database : dbList) { for (int i = 0; i < jsonArray.size(); i++) { JSONObject jsonObject = jsonArray.getJSONObject(i); influxUtils.dropContinuousQuery(jsonObject.getString("name"), database); } } } /** * 创建所有连续查询 */ private void createAllCp() { for(InfluxCqDict influxCqDict : influxCqDictList) { String createCqStr = makeOneCqStr(influxCqDict); influxUtils.createContinuousQuery(createCqStr); } } /** * 生成单个连续查询语句 * * @param influxCqDict InfluxCqDict * @return 连续查询语句 */ private String makeOneCqStr(InfluxCqDict influxCqDict) { String every = makeEvery(influxCqDict); String fields = makeFields(influxCqDict); String groupBy = makeGroupBy(influxCqDict); JSONObject paramJson = new JSONObject(); paramJson.put("cqName", influxCqDict.getCqName()); paramJson.put("onDatabase", influxCqDict.getFromDatabase()); paramJson.put("every", every); paramJson.put("forInterval", influxCqDict.getForInterval()); paramJson.put("fields", fields); paramJson.put("toDatabase", influxCqDict.getToDatabase()); paramJson.put("toRetentionPolicy", influxCqDict.getToRetentionPolicy()); paramJson.put("toMeasurement", influxCqDict.getToMeasurement()); paramJson.put("fromDatabase", influxCqDict.getFromDatabase()); paramJson.put("fromRetentionPolicy", influxCqDict.getFromRetentionPolicy()); paramJson.put("fromMeasurement", influxCqDict.getFromMeasurement()); paramJson.put("groupBy", groupBy); paramJson.put("fill", influxCqDict.getFill()); return InfluxUtils.formatSql(InfluxSql.CREATE_CONTINUOUS_QUERY, paramJson); } /** * 生成语句Field字段 * * @param influxCqDict InfluxCqDict * @return Field字段 */ private String makeFields(InfluxCqDict influxCqDict) { String[] fields = influxCqDict.getField().split(","); String[] funcs = influxCqDict.getFunc().split(","); StringBuilder sb = new StringBuilder(); for (String field : fields) { for (String func : funcs) { sb.append(func).append("(").append(field).append("),"); } } return sb.substring(0, sb.length() - 1); } /** * 生成GroupBy字段 * * @param influxCqDict InfluxCqDict * @return GroupBy字段 */ private String makeGroupBy(InfluxCqDict influxCqDict) { List<String> tagKeys = influxUtils.getMeasurementTagKeys( influxCqDict.getFromDatabase(), influxCqDict.getFromMeasurement()); StringBuilder sb = new StringBuilder(); sb.append("time(").append(influxCqDict.getGroupByTime()).append(")"); if (tagKeys.size() > 0) { sb.append(","); } for (String tagKey : tagKeys) { sb.append(tagKey).append(","); } return sb.substring(0, sb.length() - 1); } /** * 生成EVERY字段 * * @param influxCqDict InfluxCqDict * @return EVERY字段 */ private String makeEvery(InfluxCqDict influxCqDict) { String every = influxCqDict.getEvery(); if (every != null && !every.isEmpty()) { return " EVERY " + every; } return ""; } }
4、Domain类
package com.rexel.backstage.project.tool.init.domain; import lombok.Data; /** * InfluxDB以上是关于使用InfluxDB的连续查询解决聚合性能问题的主要内容,如果未能解决你的问题,请参考以下文章