Hadoop基础(四十九):压缩和存储
Posted 秋华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop基础(四十九):压缩和存储相关的知识,希望对你有一定的参考价值。
1 Hadoop 源码编译支持 Snappy 压缩
1.1 资源准备
1.CentOS 联网
配置 CentOS 能连接外网。Linux 虚拟机 ping www.baidu.com 是畅通的
注意:采用 root 角色编译,减少文件夹权限出现问题
2.jar 包准备(hadoop 源码、JDK8 、maven、protobuf)
(1)hadoop-2.7.2-src.tar.gz
(2)jdk-8u144-linux-x64.tar.gz
(3)snappy-1.1.3.tar.gz
(4)apache-maven-3.0.5-bin.tar.gz
(5)protobuf-2.5.0.tar.gz
1.2 jar 包安装
注意:所有操作必须在 root 用户下完成
1.JDK 解压、配置环境变量 JAVA_HOME 和 PATH,验证 java-version(如下都需要验证是否配置成功)
[root@hadoop101 software] # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/module/ [root@hadoop101 software]# vi /etc/profile #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin [root@hadoop101 software]#source /etc/profile
验证命令:java -version
2.Maven 解压、配置 MAVEN_HOME 和 PATH
[root@hadoop101 software]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/module/ [root@hadoop101 apache-maven-3.0.5]# vi /etc/profile #MAVEN_HOME export MAVEN_HOME=/opt/module/apache-maven-3.0.5 export PATH=$PATH:$MAVEN_HOME/bin [root@hadoop101 software]#source /etc/profile
验证命令:mvn -version
1.3 编译源码
1.准备编译环境
[root@hadoop101 software]# yum install svn [root@hadoop101 software]# yum install autoconf automake libtool cmake [root@hadoop101 software]# yum install ncurses-devel [root@hadoop101 software]# yum install openssl-devel [root@hadoop101 software]# yum install gcc*
2.编译安装 snappy
[root@hadoop101 software]# tar -zxvf snappy-1.1.3.tar.gz -C /opt/module/ [root@hadoop101 module]# cd snappy-1.1.3/ [root@hadoop101 snappy-1.1.3]# ./configure [root@hadoop101 snappy-1.1.3]# make [root@hadoop101 snappy-1.1.3]# make install # 查看 snappy 库文件 [root@hadoop101 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy
3.编译安装 protobuf
[root@hadoop101 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/ [root@hadoop101 module]# cd protobuf-2.5.0/ [root@hadoop101 protobuf-2.5.0]# ./configure [root@hadoop101 protobuf-2.5.0]# make [root@hadoop101 protobuf-2.5.0]# make install # 查看 protobuf 版本以测试是否安装成功 [root@hadoop101 protobuf-2.5.0]# protoc --version
4.编译 hadoop native
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2-src.tar.gz [root@hadoop101 software]# cd hadoop-2.7.2-src/ [root@hadoop101 software]# mvn clean package -DskipTests -Pdist,native -Dtar - Dsnappy.lib=/usr/local/lib -Dbundle.snappy
执行成功后,/opt/software/hadoop-2.7.2-src/hadoop-dist/target/hadoop-2.7.2.tar.gz 即为新
生成的支持 snappy 压缩的二进制安装包。
2 Hadoop 压缩配置
2.1 MR 支持的压缩编码
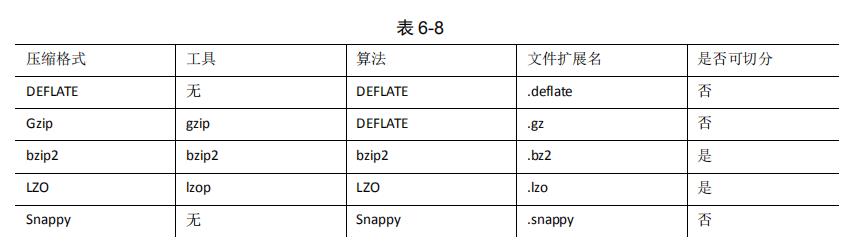
为了支持多种压缩/解压缩算法,Hadoop 引入了编码/解码器,如下表所示:


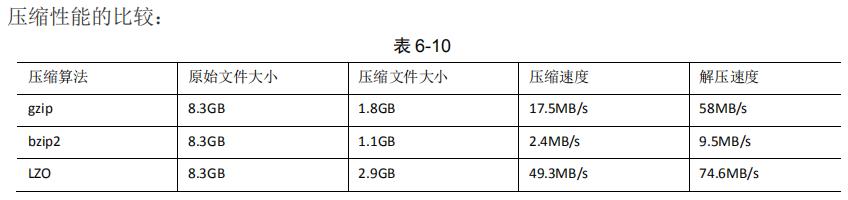
http://google.github.io/snappy/
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250MB/sec or more and decompresses at about 500 MB/sec or more.
2.2 压缩参数配置
要在 Hadoop 中启用压缩,可以配置如下参数(mapred-site.xml 文件中):
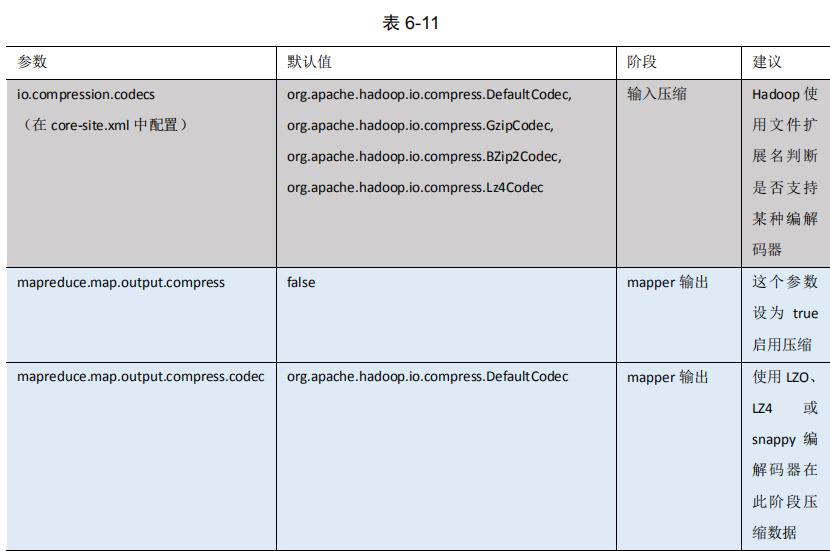
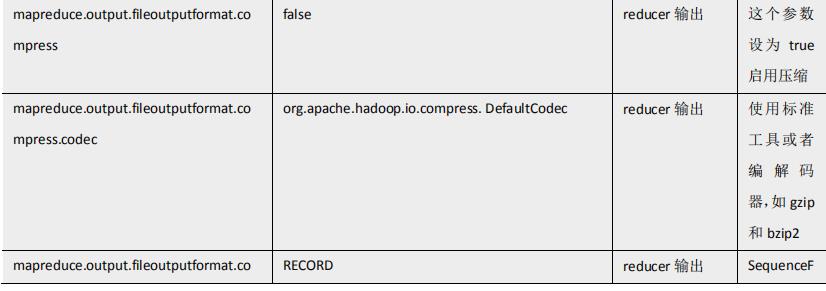

3 开启 Map 输出阶段压缩
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
案例实操:
1.开启 hive 中间传输数据压缩功能 hive (default)>set hive.exec.compress.intermediate=true; 2.开启 mapreduce 中 map 输出压缩功能 hive (default)>set mapreduce.map.output.compress=true; 3.设置 mapreduce 中 map 输出数据的压缩方式 hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; 4.执行查询语句 hive (default)> select count(ename) name from emp;
以上是关于Hadoop基础(四十九):压缩和存储的主要内容,如果未能解决你的问题,请参考以下文章