Hadoop基础(二十二):Shuffle机制
Posted 秋华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop基础(二十二):Shuffle机制相关的知识,希望对你有一定的参考价值。
7 Combiner合并

(6)自定义Combiner实现步骤
(a)自定义一个Combiner继承Reducer,重写Reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 1 汇总操作 int count = 0; for(IntWritable v :values){ count += v.get(); } // 2 写出 context.write(key, new IntWritable(count)); } }
(b)在Job驱动类中设置:
job.setCombinerClass(WordcountCombiner.class);
8 Combiner合并案例实操
1.需求
统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。
(1)数据输入

(2)期望输出数据
期望:Combine输入数据多,输出时经过合并,输出数据降低。
2.需求分析

图4-15 Combiner的合并案例
3.案例实操-方案一
1)增加一个WordcountCombiner类继承Reducer


package com.atguigu.mr.combiner; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{ IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 1 汇总 int sum = 0; for(IntWritable value :values){ sum += value.get(); } v.set(sum); // 2 写出 context.write(key, v); } }
2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑 job.setCombinerClass(WordcountCombiner.class);
4.案例实操-方案二
1)将WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑 job.setCombinerClass(WordcountReducer.class);
运行程序,如图4-16,4-17所示
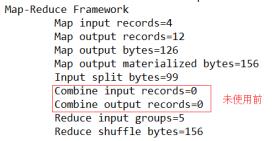
图4-16 未使用前

图4-17 使用后
以上是关于Hadoop基础(二十二):Shuffle机制的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop基础---shuffle机制(进一步理解Hadoop机制)
2021年大数据Hadoop(二十三):MapReduce的运行机制详解