Linux 常用命令(要求全而精)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 常用命令(要求全而精)相关的知识,希望对你有一定的参考价值。
懂的人请回答 不要Ctrl+v 谢谢
1、linux分区--在linux里面所有的设备、任何东西,在linux看来都是文件。
--文件在它看来,有两种形式:
第一种是字符型(键盘输入、打印机);
第二种是二进制型(硬盘、光驱、U盘)
--linux中所有硬件
--手动分区
--A、至少有两个分区
/ 根分区
SWAP 交换分区(物理内存大小的两倍)
--B、个人桌面分区
/
/boot 128MB is enough
/usr
SWAP
/tmp(用于光盘刻录)
2、linux目录说明
--/dev/xxyN
--xx (分区所在设备类型:hd--IDE硬盘 sd--SCSI硬盘)
--y (标明分区所在设备
例如:/dev/hda 第一个IDE硬盘 或 /dev/hdb 第二个IDE硬盘 或 /dev/sdb 第二个SCSI硬盘)
--N (数字代表分区:1-4--主分区或扩展分区;逻辑分区从5开始!
例如:/dev/hda3 第一个IDE硬盘上的第三个主分区或扩展分区
/dev/sdb6 第二个SCSI硬盘上的第二个逻辑分区)
3、linux目录结构
/ 根目录,最高级别
/bin 系统基本命令存放目录(/usr/bin)
/boot linux的内核及引导系统程序文件存放目录(如:vmlinuz、initrd.img)
一般情况下,GRUB或LILO系统引导管理也位于这个目录
/dev 设备文件存储目录,如声卡、光驱...
/ect 存放系统设置文件(如用户账号密码、服务器配置文件等)
/home 普通用户家目录,默认存放目录
/lib 库文件存放目录
/lost+found 在ext2或ext3文件系统中,当系统以外崩溃或机器意外关机,而产生一些文件碎片放在这里。
当系统启动的过程中,fsck工具会检查这里,并修复已经损坏的文件系统。
有事喜用发生问题,有很多的文件被移到这个目录中,可能会用手工的方式来修复,或者移文件到原来的位置上。
/media 即插即用型存储设备的挂载点自动在这个目录下创建。
如USB盘系统自动挂在后,会在这个目录下产生一个目录;
类似cdrom的目录
/mnt 存放挂载存储设备的挂载目录,如cdrom等目录
/opt 表示可选的意思,有些软件包也会被安装在此,也就是自定义软件包,
比如OpenOffice,或者一些我们自己编译的软件包,也可安装此处。
/proc 操作系统运行时,进程(正在运行的程序)信息及内核信息(比如CPU、硬盘分区、内存信息等)存放在此。
/proc目录是伪装的文件系统proc的挂载目录,proc并不是真正的文件系统
/root linux超级权限用户root的家目录
/sbin 大多是涉及系统管理的命令的存放,只有超级权限用户root才可执行命令存放,普通用户无权限执行此目录下的命令
与 /usr/sbin; /usr/X11R6/sbin; usr/local/sbin 目录相似
(sbin,只有root权限才能执行)
/tmp 临时文件目录,有时用户运行程序的时候,会产生临时文件。
/var/tmp目录和此目录相似
/usr 系统存放程序的目录,如命令、帮助文件等。这个目录下有很多的文件和目录。
大部分Linux发行版提供的软件包都安装在此,涉及服务器的配置文件就安装在/ect中。
/usr/share/fonts 字体目录
/usr/share/man 或 /usr/share/doc 帮助目录
/usr/bin 或 /usr/local/bin 或 /usr/X11R6/bin 普通用户可执行文件目录
/usr/sbin 或 /usr/local/sbin 或 /usr/X11R6/sbin 超级权限用户root可执行命令存放目录
/usr/include 程序头文件存放目录
/var (vary)此目录经常变动
/var/log 用来存放系统日志
/var/www 用来定义Apache服务器站点存放
/var/lib 用来存放一些库文件,如mysql的,以及MySQL数据库的存放地。
4、基本命令
--查看帮助 *** --help *** --?
--查看详细帮助 man ***
--登录 login
--退出窗口 exit
--关机 shutdown
--重启 reboot
--初始化 init (run level -/etc/inittab),0-6看第六部分的g
--进入根目录 cd /
--回上层目录 cd ..
--相对路径 cd dev
--绝对路径 cd /dev
--查用户名 whoami
--查当前目录 pwd
--列出当前目录内容 ls
-l(树详细显示目录内容)
-m(横列显示目录内容,是屏幕长度显示)
-a(列出全部文件,包括隐藏文件)
-S(以文档大小排序)
--创建目录 mkdir dname
--删除目录 rmdir dname
rm -r *** -(递归删除该目录下所有内容,询问每个准备删除的文件)
rm -rf ***-(强制删除该目录下所有内容,不询问)
--创建空白文件 touch ***
(ps:从技术的角度来讲,linux的文件后缀名没有任何意义)
--复制 cp
cp -r **1 **2 (复制1到2中)
--移动 mv
mv -t **1 **2 (把2移动到1中)
--编辑文本 vi [文件名]
--查看文本 cat 由第一行开始显示文本内容
tac 从最后一行显示,可以看出 tac 是 cat 的倒着写
more 一页一页的显示文档内容
less 与 more 类似,可以往前翻页
head 只看头几行
-N(数字,可根据行数显示)
tail 只看后几行
-N(数字,可根据行数显示)
nl 显示的时候,顺序输出行号
od 以二进制位的方式读取档案内容
--查找文本 find [路径][查找类型][搜索文件名]
如查找rc.local find /etc -name *.local
--查找命令信息及其位置 whereis 命令
如 whereis ls
--查看环境变量 echo $SHELL
如 echo $PATH (分大小写:分隔符是:,windows是echo %path%;)
--链接 ln
如 ln joe.txt a (硬链接,如同复制一个新文件,joe.txt删除后,a还存在)
a是链接的名称,a和joe.txt同步,然后a的内容和joe.txt一样
joe.txt改变,a也跟着变
如 ln -s joe.txt b (软链接,如同创建一个快捷方式,joe.txt删除后,b不存在)
--wc 统计指定文本文件的行数、字数、字符数
--grep(很常用) 在指定的文本文件中查找指定的字符串
grep 字符串 文件名
--col 见管道..
--------------------
----信息显示命令----
--------------------
--date 显示和设置日期
--stat 显示指定文件的相关信息
--who、w 显示在线登录用户
--whoami 显示用户自己的身份
--id 显示当前用户的id信息
--hostname 显示主机名称
--uname 显示操作系统信息
--dmesg 显示系统启动信息
--du 显示指定的文件(目录)已使用的磁盘空间
--df 显示文件系统磁盘空间的使用情况
--free 显示当前内存和交换空间的使用情况
--fdisk -l 显示磁盘信息
--locale 显示当前语言环境
5、挂载点(mount 设备目录 挂载目录)
--访问设备 (那设备当成一个文件,和另外一个文件夹进行绑定)
--例如挂载光驱:步骤 [cd /mnt]---[mkdir cdr]---[mount /dev/cdrom /mnt/cdr]---[cd cdr]--OK!直接访问光驱内容
--卸载挂载设备(umount /dev/cdrom)--注意必须先退出挂载目录,否则出现"device is busy"错误.
6、startup-shutdown(linux启动流程)
--A、boot sequence(important) linux启动过程
a. load bios(hardware information)
b. read MBR's config to find out the OS
(MBR--Master Boot Record,硬盘第一个物理扇区,柱面0、磁头0、扇区1,包含主引导程序和硬盘分区表)
c. load the kernel of the OS
(加载为kernel核心的OS)
d. init process starts...
(启动linux第一个进程init)
e. execute /etc/rc.d/sysinit
(执行系统最重要的配置文件,后台启用进程)
(rc.d--run command)
f. start other modules(stc/modules.conf)
(开启各种模块,如内存管理模块、硬盘管理模块)
g. execute the run level scripts
(系统启动是分层次的,根据情况执行,每个层次之间没关系)
0 - 系统停机状态
1 - 单用户工作状态 root
2 - 多用户状态(没有NFS)
3 - 多用户状态(有NFS)
NFS - Network File System 网络文件系统,联网系统
4 - 系统未使用,留给用户
5 - 图形界面
6 - 系统正常关闭并重新启动
如:cd /etc -- 有rc0.d、rc1.d、rc2.d、rc3.d、rc4.d、rc5.d等多个文件夹,保存着各个层次执行的进程文件
h. execute /etc/rc.d/rc.local (重要)
(保存其它进程脚本,如tomcat自动启动,要修改此配置文件)
i. execute /bin/login
(登录界面)
j. shell started...
7、vi 文本编辑器
--两种模式:命令模式 编辑模式
--vi [文件名]
(切换到编辑模式)
a append-光标后添加
i insert-光标前插入
o open-另起一行编辑
esc (切换回命令模式)
:w 存盘
:wq 存盘退出
:q 退出
:q! 不存盘退出
dd 删除其中一行
dw 删除一个单词
(sudo gedit 文本 常用linux下的文本编辑器,比vi好用)
8、用户设置
--切换用户(switch user) su username
小技巧:直接exit切换
--添加用户 useradd username [-g] [组名](分配到某个用户组)
(创建后会自动在/home目录下创建该新用户的文件夹,如/home/username)
--设置密码 passwd username
--cd /etc
--查看用户信息 more password
如新增的用户信息:username:x:500:500::/home/username:/bin/bash
第一个数字,代表用户组,当添加用户没有指定用户组时,系统会创建一个和用户ID一样的组ID;
第二个数字:用户ID号;
用户的目录是/home/username;
用户的SHELL是/bin/bash
(命令--->SHELL[解释命令]--->kenrel内核)
SHELL有多种类型,如csh、bash(常用)、bsh、ksh、sh(最原始)
--添加用户组 groupadd groupname
--查看用户组信息 more group
--删除用户组 groupdel groupname
--修改用户 usermod [-g] [组名] [用户名]
--删除用户 userdel username
然后把/home的文件夹删除了 rm -rf 文件夹
9、权限file privilege
--linux把文件的权限分成四种:r:read w:write x:execute -:none
如:-rw-r--r--
lrwxrwxrwx
drwxr-xr-x
drwxr-xr-x
第一个数字'-'代表文件,其余是文件夹,后9位分为3组,每组有四种权限设置rwx-
第一位表示文件所有者
第二位表示和所有者在同一用户组的用户
第三位表示不在同一用户组的用户权限
--设置权限 (随意应用,灵活组合!)
1、普通用法
--添加权限 [chmod +x 文件]
如:-rw-r--r-- ---> -rwxr-xr-x
--删除权限 [chmod -x 文件]
如:-rwxr-xr-x ---> -rw-r--r--
--给自己添加权限 [chmod ?+x 文件]
如此类推,组--g,其他人--o
如:chmod u+x -rw-r--r-- ---> -rwxr--r--
chmod g+x -rw-r--r-- ---> -rw-r-xr--
chmod o+x -rw-r--r-- ---> -rw-r--r-x
2、专业用法 chmod 755/777
--原理,八进制转二进制
如755,111 101 101, rwx r-x r-x
777,111 111 111, rwx rwx rwx
--修改所有者权限 chown (change owner)
如:chown 原来文件 file1 的所有者是 root,改成joe的
chown joe file1
10、管道(把上一个命令执行的结果交给下一个命令)
--使用方法:
命令1|命令2|命令3......|命令n
--使用举例
--$ls -Rl /etc | more
(如 ls -Rl /etc (在控制台模式下,无法返回前面过去的信息),因此需要管道执行该查询,实现分页的工作, ls -Rl /etc | more)
--$cat /etc/passwd | wc
(显示文件结果,再数数有多少行)
--$cat /etc/passwd | grep lrj
(显示文件结果,再查找包含lrj的行)
--#dmesg | grep eth0
(显示系统启动的信息,再查找包含eth0的行--真正含义,检查网卡执行信息是否正常)
--$man bash | col -b > bash.txt
语 法:col [-bfx][-l<缓冲区列数>]
补充说明:在许多UNIX说明文件里,都有RLF控制字符。当我们运用shell特殊字符">"和">>",把说明文件的内容输出成纯文本文件时,控制字符会变成乱码,col指令则能有效滤除这些控制字符。
参 数:
-b 过滤掉所有的控制字符,包括RLF和HRLF。
-f 滤除RLF字符,但允许将HRLF字符呈现出来。
-x 以多个空格字符来表示跳格字符。
-l<缓冲区列数> 预设的内存缓冲区有128列,您可以自行指定缓冲区的大小。
--$ls -l | grep "^d"
(用正则表达式筛选出目录列表中 头字母为'd' 的内容--目录)(^是正则表达式开头部分)
--$ls -l * | grep "^-" | wc -l
(列出目录列表中 头字符为'-'的内容--文件,并统计显示的行数wc -l)
11、其他命令
--wall(warning all) 通知所有人
a.命令替换
如 wall `date`、 cd 'pwd'、mkbootdisk $(uname -r)
b.重定向
重定向输出:
如 ls > cmd.txt ,把文件写到cmd.txt,不输出在控制台
ls >> cmd.txt ,把文件追加写到cmd.txt
重定向输入:
如 wall > cmd.txt,把文本内容发给所有人
12、修改系统的默认系统级别
常用3和5
3 - 多用户状态(有NFS)
NFS - Network File System 网络文件系统,联网系统
5 - 图形界面
PS.设置用户权限: sudo chmod 777 目录
4表示读,2表示写,1表示执行.
第一位表示文件所有者,第二位表示和所有者在同一用户组的用户,第三位表示不在同一用户组的用户权限.
755表示文件所有者可读写,执行.
第二位5表示与所有者在同一用户组的可读,可执行,不可写.
第三位5表示其它组可读,可执行,不可写. 转载于Joewalker在本人空间也有详细说明 参考技术A http://wenku.baidu.com/view/6f955c5177232f60ddcca1f8.html自己进去看看吧,貌似自己可以下载下来 参考技术B 1)文件操作
vi FileName 打开文件 FileName,并将光标置于第一行首。
vi +n FileName 打开文件 FileName,并将光标置于第 n 行首。
vi + FileName 打开文件 FileName,并将光标置于最后一行。
vi + /pattern File 打开文件 File,并将光标置于其中第一个于 pattern 匹配的字符串处。
vi –r FileName 在上次正用 vi 编辑 FileName 发生系统崩溃后,恢复FileName。
vi File1 … Filen 打开多个文件,依次对之进行编辑。
:%!xxd 按十六进制查看当前文件
:%!xxd -r 从十六进制返回正常模式
:n1,n2 co n3 将 n1 行到 n2 行之间的内容拷贝到第 n3 行下。
:n1,n2 m m3 将 n1 行到 n2 行之间的内容移至第 n3 行下。
:n1,n2 d 将 n1 行到 n2 行之间的内容删除。
:n1,n2 w filename 将 n1 行到 n2 行之间的内容保存到文件 filename 中
:n1,n2 w! Command 将文件中n1行到n2行的内容作为 Command的输入并执行之,
若不指定 n1、n2,则将整个文件内容作为 Command 的输入。
:r! Command 将命令 Command 的输出结果放到当前行。
:nr 文件> 把文件>插入到第n行
:so 文件> 读取文件>,再执行文件里面的命令(文件中的命令应该都是一些ex命令)
:l1,l2w 文件> 把第l1和第l2行之间的文本写到文件>中去
:w >> 文件> 添加到文件>末尾. 也可以使用行号
:e! 重新编辑当前文件,忽略所有的修改
·(、[、、]、)对应显示
% 显示当前(、[、 、、] 、)的对应项
) :光标移至句尾
( :光标移至句首
:光标移至段落开头
:光标移至段落结尾
·(、[、、]、)内数据选择
daB 删除及其内的内容 (在非v可视模式下)
diB 删除中的内容
ab 选择()中的内容
ib 选择()中的内容( 不含() )
aB 选择中的内容
iB 选择中的内容( 不含 )
·语法提示与自动补齐
★ 插入模式下的单词自动完成
★ 行自动完成(超级有用)
·设置ctags
#ctags -f /usr/share/vim/vim63/funcs.tags -R /opt/j2sdk/src /usr/src/kernels/2.6.9-5.EL-i686
^p 自动补齐上下文已有相近项
^n 自动补齐~/.tags中的相近函数
^[ 显示~/.tags中的光标下的函数的原型,
按^t退出函数
:pta 函数名 预览窗口快速打开相应函数所在文件,并将光标定位在对应函数的开头
K 显示光标下的C函数的man说明手册
·变量定位
gd 转到光标下局部变量的定义处
Gd 转到光标下全局变量的定义处
·编译选项
:cn 命令会把你带到下一个出错地点,而不考虑它在什么文件里。
:cc 命令会向你显示当前错误的编译器输出信息;
:cl 会生成一个列有项目所有错误的列表,以供浏览这些错误
3]光标移动
·字符
h 光标左移一个字符。
l 光标右移一个字符。
·字
w 或 W 光标右移一个字至字首。
B 或 b 光标左移一个字至字首。
E 或 e 光标右移一个字至字尾。
·句 光标移至句尾。
( 光标移至句首。
·段) 光标移至段落开头。
光标移至段落结尾。
·行k 或 Ctrl+p 光标上移一行。
j 或 Ctrl+n 光标下移一行。
Enter 光标下移一行。
nG 光标移至第 n 行首。
n+ 光标下移 n 行。
n- 光标上移 n 行。
n$ 光标移至第 n 行尾。
0 光标移至当前行首。
$ 光标移至当前行尾。
·屏幕
H 光标移至屏幕顶行。
M 光标移至屏幕中间行。
L 光标移至屏幕最后行。
Ctrl+u 向文件首翻半屏。
Ctrl+d 向文件尾翻半屏。
Ctrl+f 向文件尾翻一屏。
Ctrl+b 向文件首翻一屏。
nz 将第 n 行滚至屏幕顶部。不指定 n 时将当前行滚至屏幕顶。
4插入
# 在文件中插入行号(不是显示行号,是插入!)
★:g/^/exec "s/^/".strpart(line(".")." ", 0, 4)
·光标
i 在光标前插入。
a 在光标后插入。
·行
I 在当前行首插入。
A 在当前行尾插入。
o 在当前行之下一新行插入。
O 在当前行之上新开一行插入。
5)替换
r 替换当前字符。
R 替换当前字符及其后的字符,直至按 ESC 键。
s 从当前光标位置处开始,以输入的文本代替指定数目的字符。
S 删除指定数目的行,并以所输入的文本代替。
6)修改
ncw 或 nCW 修改指定数目的字符。
nCC 修改指定数目的行。
:r filename 将文件 filename 插入在当前行之下
7)查找替换
/ 把狭义单词 写到 搜索命令行
/ 把广义单词 写到 搜索命令行
:g/str/s/str1/str2/g
第一个g表示对每一个包括s1的行都进行替换,
第二个g表示对每一行的所有进行替换
包括str的行所有的str1都用str2替换
:%s/f $/for$/g 将每一行尾部的“f ”(f键和空格键)替换为for
:%s/^/mv /g 在每一行的头部添加“mv ”(mv键和空格键)
:s/fred/a/g 替换fred成register a中的内容,呵呵
:g/显示含或的行
# 替换一个visual区域
# 选择一个区域,然后输入 :s/Emacs/Vim/ 等等,vim会自动进入:模式
:'s/Emacs/Vim/g 前面的'是vim自动添加的
# 在多个文档中搜索
:bufdo /searchstr
:argdo /searchstr
复制与剪切
xp 交换前后两个字符的位置
ddp 上下两行的位置交换
:g/fred/t$ 拷贝行,从fred到文件末尾(EOF)
9)窗口操作
:vne [filename]
:sp [filename]
:S [filename]
:new [filename]
:^w + ^r 交换两个窗口的位置
^w = 窗口等宽
:res -n 窗口高度减小n
:res +n 窗口高度增大n
:vert res -n
:vert res +n
10)DOS格式文本转成Unix格式文本
:1,$s/^M//g
11)书签
在阅读和编写大的程序文件时,利用标记(书签)功能定位是十分有帮助的。
将光标移到想做标记的位置。假如做一个名为“debug1”的标记,那么用户可在命令模式下输入做标记的命令“mdebug1”,然后敲入回车键,一个名为“debug1”的标记就做好了。
接下来用户可以随意将光标移到其它的位置,当在命令模式下输入“`debug1”后,就能快速回到“debug1”的标记所在行的行首。
馨竹 2007-12-24 19:13
12)删除操作
:%s/r//g 删除DOS方式的回车^M
:%s= *$== 删除行尾空白
:%s/^(.*)n1/1$/ 删除重复行
:%s/^.pdf/new.pdf/ 只是删除第一个pdf
:%s/// 又是删除多行注释(咦?为什么要说「又」呢?)
:g/^s*$/d 删除所有空行
:g!/^dd/d 删除不含字符串'dd'的行
:v/^dd/d 同上 (译释:v == g!,就是不匹配!)
:g/str1/,/str2/d 删除所有第一个含str1到第一个含str2之间的行
:v/./.,/./-1join 压缩空行
:g/^$/,/./-j 压缩空行
:s/p1/p2/g:将当前行中所有p1均用p2替代
:n1,n2s/p1/p2/g:将第n1至n2行中所有p1均用p2替代
:g/p1/s//p2/g:将文件中所有p1均用p2替换
ndw 或 ndW 删除光标处开始及其后的 n-1 个字符。
d0 删至行首。
d$ 删至行尾。
ndd 删除当前行及其后 n-1 行。
x 或 X 删除一个字符。
Ctrl+u 删除输入方式下所输入的文本。
^R 恢复u的操作
J 把下一行合并到当前行尾
V 选择一行
^V 按下^V后即可进行矩形的选择了
aw 选择单词
iw 内部单词(无空格)
as 选择句子
is 选择句子(无空格)
ap 选择段落
ip 选择段落(无空格)
D 删除到行尾
x,y 删除与复制包含高亮区
dl 删除当前字符(与x命令功能相同)
d0 删除到某一行的开始位置
d^ 删除到某一行的第一个字符位置(不包括空格或TAB字符)
dw 删除到某个单词的结尾位置
d3w 删除到第三个单词的结尾位置
db 删除到某个单词的开始位置
dW 删除到某个以空格作为分隔符的单词的结尾位置
dB 删除到某个以空格作为分隔符的单词的开始位置
d7B 删除到前面7个以空格作为分隔符的单词的开始位置
d) 删除到某个语句的结尾位置
d4) 删除到第四个语句的结尾位置
d( 删除到某个语句的开始位置
d) 删除到某个段落的结尾位置
d 删除到某个段落的开始位置
d7 删除到当前段落起始位置之前的第7个段落位置
dd 删除当前行
d/text 删除从文本中出现“text”中所指定字样的位置,
一直向前直到下一个该字样所出现的位置(但不包括该字样)之间的内容
dfc 删除从文本中出现字符“c”的位置,一直向前直到下一个该字符所出现的位置(包括该字符)之间的内容
dtc 删除当前行直到下一个字符“c”所出现位置之间的内容
D 删除到某一行的结尾
d$ 删除到某一行的结尾
5dd 删除从当前行所开始的5行内容
dL 删除直到屏幕上最后一行的内容
dH 删除直到屏幕上第一行的内容
dG 删除直到工作缓存区结尾的内容
d1G 删除直到工作缓存区开始的内容
修改命令操作
r 更改当前字符
cw 修改到某个单词的结尾位置
c3w 修改到第三个单词的结尾位置
cb 修改到某个单词的开始位置
cW 修改到某个以空格作为分隔符的单词的结尾位置
cB 修改到某个以空格作为分隔符的单词的开始位置
c7B 修改到前面7个以空格作为分隔符的单词的开始位置
c0 修改到某行的结尾位置
c 修改到某个语句的结尾位置
c4 修改到第四个语句的结尾位置
c( 修改到某个语句的开始位置
c) 修改到某个段落的结尾位置
c 修改到某个段落的开始位置
c7 修改到当前段落起始位置之前的第7个段落位置
ctc 修改当前行直到下一个字符c所出现位置之间的内容
C 修改到某一行的结尾
cc 修改当前行
5cc 修改从当前行所开始的5行内容
. 重复上一次修改!
13Set 选项设置
set all 列出所有选项设置情况。
set term 设置终端类型。
set ignorecase 在搜索中忽略大小写。
set list 显示制表位(^I)和行尾标志($)。
set number 显示行号。
set showmode 示用户处在什么模式下
set report 显示由面向行的命令修改国的行数目。
set terse 显示简短的警告信息。
set warn 在转到别的文件时,若没有保存当前文件则显示 No write 信息。
set autowrite 在“:n”和“:!”命令之前都自动保存文件
set nomagic 允许在搜索模式中,使用前面不带\的特殊字符。
set nowrapscan 禁止 vi 在搜索到达文件两端时,又从另一端开始。
set mesg 允许 vi 显示其他用户用 write 写到自己终端上的信息。
autoindent (ai) noai 使新行自动缩进,和上(下)行的位置对齐
autoprint (ap) ap 每条命令之后都显示出修改之处
autowrite (aw) noaw 在:n,:!命令之前都自动保存文件
beautify (bf) nobf 在输入的时候忽略所有的控制字符(除了制表键(tab),换行(newline),进纸(formfeed))
directory= (dir=) /tmp 存放缓冲区的目录名
edcompatible noedcompatible 在替换的时候使用类ed的用法
errorbells (eb) errorbells 出错的时候响铃
exrc (ex) noexrc 允许在主目录(home)外面之外放.exrc文件
hardtabs= (ht=) 8 设置硬制表的边界
ignore case (ic) noic 正规式里忽略大小写
lisp nolisp 打开lisp模式
list nolist 显示所有的制表键和行的结尾
magic agic 可以使用更多的正规表达式
mesg mesg 允许向终端发送消息
number (nu) nonumber 显示行号
open open 允许开放和可视化
optimize (opt) optimize 优化吞吐量,打印时不发回车
paragraphs= (para=) IPLPPPQPPLIbp 设置 & 的分界符
prompt prompt 命令模式下的输入给出:的提示符
readonly (ro) noro 除非用!号否则不准保存文件
redraw noredraw 当编辑的时候重绘屏幕
remap remap 允许宏指向其他的宏
report= 5 如果影响的行数>这个数的话就报告
scroll 1/2 window 下卷屏幕时滚动屏幕的数目, 同样这也是z命令输出的行数(z 输出2倍滚屏的大小)
sections= SHNHH HU 定义节的末尾(当使用命令[[ 和 ]] 时)
shell= (sh=) /bin/sh 缺省的SHELL,如果设置了环境变量SHELL的话,就使用变量
shiftwidth= (sw=) 8 当使用移动(shift)命令时移动的字符数
showmatch (sm) nosm 显示, , (, ), [, 或者 ] 的匹配情况
showmode noshowmode 显示你处在什么模式下面
slowopen (slow) 插入之后不要立刻更新显示
tabstop= (ts=) 8 设置制表停止位(tabstop)的长度
taglength= (tl=) 0 重要标记的字符个数(0表示所有的字符)
tags= tag, /usr/lib/tags 定义包含标记的文件路径
term= 设置终端类型
terse noterse 显示简短的错误信息
timeout (to) timeout 一秒钟后键盘映射超时
ttytype= 设置终端类型
warn warn 显示"No write since last change"信息
window= (w=) 可视模式下窗口的行数
wrapmargin= (wm=) 0 右边距,大于0的话最右边的单词将折行,留出n个空白位置
wrapscan (ws) ws 查找到文件尾后再重头开始
writeany (wa) nowa 可以保存到任意一个文件去
14特殊字符
^ 匹配字符串位于行首。
$ 匹配字符串位于行尾。
. 用在模式串中,表示任何单个字符。
在命令模式下,重复上次的命令。
* 在模式串中,表示其前字符可出现任意多次。
[] 用在模式串中,表示指定方位内字符,其中可用-表示一个字
符范围,用^表示不在某个范围内的字符。
ESC 从插入状态转换到命令状态
^[ 功能同 ESC
15]大小写转换
guu 行小写
gUU 行大写
g~~ 行翻转(当然指大小写啦)
guw 字小写(狭义字) 译注:建议对比iw
gUw 字大写(狭义字)
g~w 字翻转(狭义字)
vEU 字大写(广义字)
vE~ 字翻转(广义字)
ggguG 把整个文章全部小写(ft!bt!)
16) 跳转足迹'. 跳到最后修改的那一行 (超级有用)(ft,怎么又是这个评价)
`. 不仅跳到最后修改的那一行,还要定位到修改点
依次沿着你的跳转记录向回跳 (从最近的一次开始)
依次沿着你的跳转记录向前跳
:ju(mps) 列出你跳转的足迹
17)命令历史
:history 列出历史命令记录
:his c 命令行命令历史
:his s 搜索命令历史
q/ 搜索命令历史的窗口
q 命令行命令历史的窗口
: 历史命令记录的窗口
18]寄存器
# 列出寄存器(Registers)
:reg 显示所有当前的registers
"1p 表示引用register,1表示一个名字叫做1的register,p就是粘贴(paste)命令
译释:
"也用来定义register
先输入 ",表示定义register
然后输入名字,如0~9,a~z
然后执行删除或复制命令,如dd或y,
或者是visual模式下的d(删除选中的部分)或y(复制选中的部分)
则被删除或复制的部分就被存入了这个命名的register
观察:一个特殊的register, "" ,里面存储了一个匿名的删除/复制
在你执行dd或y的时候,被作用的部分被存到了""中
19命令行
"ayy@a 把当前行作为一个Vim命令来执行
译释:"ayy 是定义当前行到register a,然后@a是执行register a中存储的指令
10yy copy 当前行以下10行
11 排序
:%!sort -u 使用sort程序排序整个文件(用结果重写文件)
!1) sort -u 排序当前段落 (只能在normal模式下使用!!)
:.,+5!sort 排序当前行及以下5行
20) 列操作
:%s= [^ ]+$=&&= 复制最后一列
:%s= f+$=&&= 一样的功能
:%s= S+$=&& ft,还是一样
:s/(.*).*)/2"1/ 颠倒用:分割的两个字段
:%s(w+s+))str1:1str2: 处理列,替换所有在第三列中的str1
:%sw+)(.*s+)(w+)$:321: 交换第一列和最后一列 (共4列)
·.vimrc
" Use Vim settings, rather then Vi settings (much better!).
set nocompatible
"c风格的缩进
:set expandtab "不使用tab只使用空格
:set cindent shiftwidth=4
"自动缩进
:set ai
"语法
":set filetype=java
:set syntax=java
"键入)、] 、,显示(、[、
:set showmatch
"手工定义折叠
:set foldmethod=manual
"标签文件位置
set tags=/usr/share/vim/vim63/funcs.tags
"在插入模式下通过按[Ctrl]N自动地将任何类、方法或者字段名补齐
set complete+=k
" 不要用声音烦我!
set visualbell
"历史
:set history=50
"显示行列位置
:set ruler
"设置字符编码
set fileencodings=gb2312
"set encoding=euc-cn
"设置ruler
set ruler
"显示当前命令
set showcmd
"incsearch
set incsearch
" allow backspacing over everything in insert mode
set backspace=indent,eol,start
"自动检测文件类型
:filetype on 参考技术C 百度文库有 好几十页 自己可以下载去 真想学的话 0积分下载
Linux——MySQL高阶语句杂而精
目录标题
按关键字排序
通过select查询出来的数据使用order by 语句来实现排序
order by 前面也可以使用where子句对查询结果进一步过滤
排序可针对一个或多个字段
ASC:升序,默认排序方式
DESC:降序
按单字段排序
降序
select id,name,level from player where level>=45 order by level desc;
查看player表的id,name,level字段where判断level值大于等于45。
且order by 对 level 字段进行排序 desc为降序从大到小。
升序
select id,name,level from player where level>=45 order by level ;
查看player表的id,name,level字段where判断level值大于等于45。
且order by 对 level 字段进行排序 为升序从小到大,默认值为ASC可以不写。
多字段排序
原则:
order by 之后的参数,使用 ,分割,优先级实按先后顺序而定,例
select id,name,hobby from info order by id asc,hobby desc;
查看info表的id,name,hobby字段先对id进行升序,再对hobby降序
select id,name,hobby from info order by hobby descid asc;
查看info表的id,name,hobby字段先对hobby进行降序,再对id升序
小结:order by 之后的第一个参数只有在出现相同的数值,第二个字段才有意义
- or/and
或/且
select * from info where score >70 and score <=90;
查看info表中score字段中大于79且小于等于90的数据
select * from info where score >70 or score <=90;
查看info表中score字段中大于70或小于等于90的数据
嵌套/多条件
select * from info where score >70 or (score >75 and score <=90);
查看info表中score字段中大于70或大于75且小于等于90的数据
括号内是一个集合
查询不重复的记录
select distinct 字段 from 表名;格式
select distinct hobby from info;
查看info表中hobby字段的内容且不重复
distinct 必须放在最开头
distinct只能使用需要去重的字段进行操作,即去重的字段才能操作排序不是去重的字段则不行
distinct去重多个字段时,含义是:几个字段同时重复时才会被过滤
对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 group by 语句来实现, group by 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(count)、求和(sum)、求平均数(avg)、最大值(max)、最小值(min), group by 分组的时候可以按一个或多个字段对结果进行分组处理
语法:
select 字段, 聚合函数 from 表名, (where 字段名 (匹配) 数值) group by 字段名;
例:
select count(name),level from player where level>=45 group by level;
对player进行分组,筛选范围/条件是level大于等于45的 ‘name’ ,level相同的会默认分在一个组
分组排序
select count(id),hobby from info group by hobby;
对info表中hobby相同的id进行数量统计,并按照相同hobby进行分组
select count(id),hobby from info group by hobby order by count(id) desc;
基于上一条操作,结合order by 把统计的id数量进行按降序排列
限制结果条目=从第几行开始查询几条结果
在使用 mysql select 语句进行查询时,结果集返回的是所有匹配的记录。有时候仅需要返回第一行或者前几行,这时候就需要用到limit子句
语法
select column1,column2,... from table_name limit [offset,] number
offset,number:
limit 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。
如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的位置偏移量是0,第二条是1,以此类推。第二个参数是设置返回记录行的最大数目。
offset:索引下标
number:索引下标之后的几位
结合 order by 排序:
select * from info order by id desc limit 3,4
查询info表中id字段从第三天条记录开始后的四条记录以升序的方式查看
设置别名
设置别名在 MySQL查询时,当表的名字比较长或者表内某些字段比较长是,为了方便书写或者多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简介明了,增强可读性
语法:
对于列的别名:select column_name as alias_name from table_name;
对于表的别名:select column_name from table_name as alias_name;
#as可以省略
在使用as后,可以用alias_name 代替 table_name,其中as 语句是可以选的。as之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名或字段时不会被改变的
列别名的设置示例:
select name as 姓名,score as 成绩 from info
表数据别名设置例:
select i.name as 姓名,i.score as 成绩 from info as i;
使用场景:
对复杂的表进行查询的时候,别名可以缩短查询语句
多表相连查询的时候(通俗易懂、减短SQL语句)
as作为连接语句
create table tmp as select * from info;
此处as起到的作用:
1、创建一个新表tmp 定义表结构,插入表数据(与info表相同)
2、但是“约束”没有被“复制”过来,但是如果原表设置了主键,那么附表的:default 字段默认设置一个0
相似:
克隆、复制表结构
create table tmp (select * from info);
#也可以加入where判断语句
create table test1 as select * from info where score >=60;
从info表“复制”要求score>=60的内容到新建的test1中
通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来
常用通配符都是跟like(模糊查询)一起使用的,并协同 where子句共同来完成查询任务,常用的通配符有两个,分别是:
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
查询名字是c开头的记录
模糊查询%示例:
select * from info where name like 'l%';
模糊查询_示例:
select * from info where name like 'l_s_';
结合使用
select * from info where name like 'l_%_';
子查询
定义、示例
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语句。
子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一步的查询过滤
子语句可以与主语句所查询的表相同,也可以是不同表
相同表(一条查询语句中查询的是相同的表):
select name,score from info where id in (select id from info where score>80);
以上主语句:select name,score from info where id
子语句(结果集):select id from info where score>80
in:将主表和子表关联/连接起来的语法
in 之后的子查询语句会给他提供的一个范围(集合),作为 in 之前 where 的判断条件
示例:
查询info表id 为1,3,5,7的数据(通过子查询的方式)
单表查询方式:
select * from info where id in (1,3,5,7)
子查询方式
create table num (id int(4));
insert into num values(1),(3),(5),(7);
select * from info where id in (select id from num);
子查询不仅可以在select 语句中使用,在inert、update、delete中也同样适用
支持多层嵌套
in 语句是用来判断某个值是否在给定的集合内(结果集),in 往往和select 搭配使用
可以使用not in 表示对结果集取反
子查询-别名as
先查询info表id,name字段
select id,name from info;
以上命令可查看到info表的内容(结果集)
将结果集作为一张表进行查询的时候,我们也需要用到别名,示例:
select id from (select id,name from info);此时会报错
ERROR 1248 (42000):Every derived table must have its own alias
原因:
select * from 表名,此为标准格式,而以上的查询语句,“表名”的位置其实是一个结果集,mysql并不能识别,而此时给与结果集设置一个别名,并且以select a.id,name from a;的方式查询,将此结果集视为一张表就可以正常查询出数据了
所以:
select a.id from (select id,name from info) a;
相当于:
select info.id,name from info;
select 表.字段,字段 from 表;
子查询-exists
select count(*) as number from tmp where exists (select id from tmp where name='zhangsan')
as number将count统计的结果作为number(列名)返回
exist:布尔值判断,后面的子查询语句是否成立的一个判断真或假
where:之后跟条件判断
加exists:只是为了判断exists之后的条件是否成立
成立,则正常执行主语句的匹配
不成立,则不会执行主语句查询
count 为计数,sum为求和,使用sum求和结合exists,如子查询结果集不成立的话,输出为null
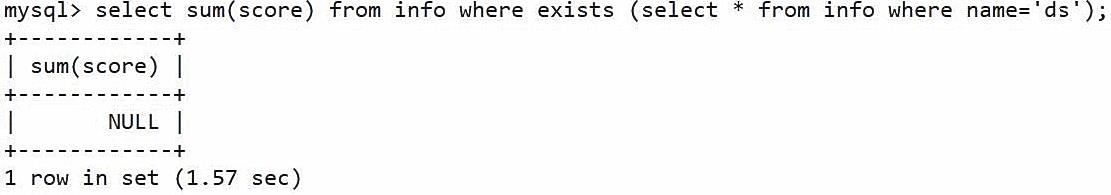
视图
数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了映射
好比水中捞月的情景,动态保存结果集(数据)
视图我们可以定义展示的条件
示例:
需求:满足80分的学生展示在视图中
这个结果会动态变化,同时可以给与不同的人群(例如权限范围)展示不同的视图
创建视图
create view v_score as select * from info where score>=80;
查看视图
select * from v_score;
修改原表数据
update info set score='6' where name='wangwu;'
查看视图此时视图也随之改变
select * from v_score;
小结:
为什么说视图好比水中捞月,如果月亮(原表数据)发生改变倒影(视图)也会随之晃动改变,但是只对水中的倒影用石头打进行改变但月亮还是那个月亮不会改变,所以只是单方面的对应,起到了一定安全性的效果
null值
定义:
通常使用NULL来表示缺失的值,也就是在表中该字段时没有值的
如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL关键字,不使用则默认可以为空
在向表内插入记录或者更新记录时,如果该字段没有NOT NULL并且没有值,这时候新记录的该字段将被保存为NULL。需要注意的是,NULL值与数字 0 或者空白(spaces)的字段是不同的,值为NULL的字段时没有值的。
在SQL语句中,使用IS NULL可以判断表内的某个字段是不是NULL值,相反的勇IS NOT NULL可以判断不是NULL值
查询info表结构,id和name字段是不允许空值的
null值和控制的区别类似于空气和真空的区别
空值长度为0,不占空间,NULL值的长度为null,占用空间
is null无法判断空值
空值使用"=“或者”<>"来处理(!=)
count()计算时,NULL会忽略,空值会加入计算
验证
alter table info add column address varchar(50);
update info set address='nj' where score >=70;
统计数量:检测null是否会被加入统计中
select count(address) from info;
将info表中其中一条数据修改为空值
update info set address=' ' where name='wangwu';
统计数量检测空值是否会被添加到系统中
select count(address) from info;
查询null值
select * from info where is null;
查询不为空的值
select * from info where is not null;
正则表达式
MySQL正则表达通常是在检索数据库记录的时候,根据指定的匹配模式匹配记录中符合要求的特殊字符串。
MySQL的正则表达式使用 REGEXP 这个关键字来指定正则表达式的匹配模式
REGEXP 操作符所支持的匹配模式如下:
^匹配文本的开始字符
$匹配文本的结束字符
.匹配任何单个字符
*匹配零个或多个在它面前的字符
+匹配前面的字符1次或多次
字符串匹配包含指定的字符串
p1|p2匹配 p1 或 p2
[...]匹配字符集合中的任意一个字符
[^...]匹配不在括号中的任何字符
{n}匹配前面的字符串n次
{n,m}匹配前面的字符串至少 n 次,至多 m 次
^表示匹配开始字符,但需要看 ^所处的位置例如:[^]表示不包含^[],则表示以…为开头
示例^
select id,name from info where name regexp '^li'查询name字段li开头的数据
示例$
select * from info where address regexp 'j$';查询address字段j结尾的数据
示例.
select * from info where name regexp 'l..i';查询name字段 l 后有两个任意字符后有个i的数据
示例*
select * from info where name regexp 'g*';查询name字段匹配g零次或者多次
示例+
select * from info where name regexp 'b+';查询name字段中b匹配至少一次或多次的数据
示例字符串
select * from info where name regexp 'iu';查询name中指定的字符串
示例p1|p2
select * from info where name regexp 'wu|is';查询name字段中包含wu或者is的数据
示例[...]
select * from info where name regexp '[g,1]';匹配集合中任意一个字符
示例[^...]
select * from info where name regexp '[^lisi]';匹配除了lisi的任何字符
示例{n}
select * from info where name regexp 'o{2}';匹配前面字符串2次
select * from info where name regexp 'o{1,2}';匹配前面字符串至少一次至多2次
运算符
MySQL的运算符用于对记录中的字段值进行运算。MySQL的运算符共有四种,分别是算术运算符、比较运算符、逻辑运算符和位运算符
算术运算符
+ 加法
-减法
*乘法
/除法
%取余
在除法运算和求余运算中,除数不能为0,若除数是 0,返回的结果则为 NULL。如果有多个运算符,按照先乘除后加减的优先级进行运算,相同优先级的运算符没有先后顺序
例
select 1+2,2-1,2*3,5/3,6%2,4/2;
create table js select 1+2,5-1,2*3,5/3,6%3,4/2;创建名为js的表把运算结果作为表内容
desc js;查看表结构除法默认为最多小数后四位
比较运算符
字符串的比较默认不区分大小写,可使用binary来区分
常用比较运算符(比较对象:数字,字符)
= 等于
!=或<>不等于
LIKE通配符匹配
>大于
>=大于等于
<小于
<=小于等于
IS NULL判断一个值是否为NULL
IS NOT NULL判断一个值是否不为NULL
BETWEEN AND两者之间
GREATEST两个或多个参数时返回最大值
LEAST两个或多个参数时返回最小值
IN在集合中
等于(=)
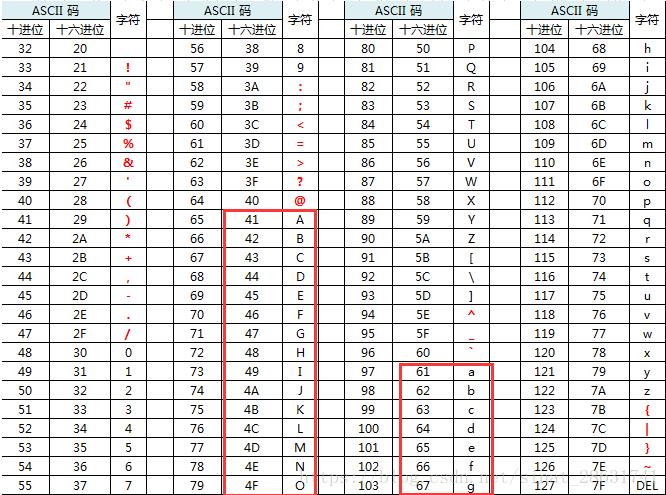
用来判断数字、字符串和表达式是否相等的,如果相等则返回1,|如果不相等则返回0。如果比较的两者有一个值是NULL,则比较的结果就是NULL。
其中字符的比较是根据ASCII码来判断的,如果ASCII码相等,则表示两个字符相同;如果ASCII码不相等,则表示两个字符不相同。例如字符串(字母)比较: (‘a’ > ‘b’)其实比较的是底层ascll码
如果比较的是多字符,例如’abc’=‘acb’,是这么比较的?(字符顺序进行比较第一位比完比第二位一旦比对出结果则返回)
如果比较的是多字符,例如:‘abc’<'baa’是如何比较的?
与Linux返回值表达相反,Linux中运行正常返回的是0,运行异常返回的是非0值
不等于(!=或<>)
用于针对数字、字符串和表达式不相等的比较,如果不相等则返回1,如果相等则返回0,与等于(=)的返回值相反,同时不等于(!=,<>)无法用于判断是否为null
大于、大于等于、小于、小于等于运算符
大于(>)运算符用来判断左侧的操作数是否大于右侧的操作数,若大于返回1,否则返回0,同样不能用于判断NULL
小于(<)运算符用来判断左侧的操作数是否小于右侧的操作数,若小于返回1,否则返回0,同样不能用于判断NULL
大于等于(>=)判断左侧的操作数是否大于等于右侧的操作数,若大于等于返回1,否则返回0,不能用于判断NULL
小于等于(<=)判断左侧的操作数是否小于等于右侧的操作数,若小子等于返回1,否则返回0,不能用于判断NULL
两者之间(between…and…)
此较运算通常用于判断一个值是否落在某两个值之间。例如,判断某数字是否在另外两个数字之间,也可以判断某英文字,母是否在另外两个字母之间,具体操作,条件符合返回1,否则返回0
示例:
select 4 between 2 and 6,5 between 6 and 8,'c' between 'a' and 'f';
比较过程中是包含两边参数的值
当有两个或多个参数时,返回其中最大/最小值,如果一个为null,则返回null(least greatest)
示例:
select least(1,2,3),least('a','b','c'),greatest(1,2,3),greatest('a','b','c');

数字比较、按大小排列
字母比较,a-b顺序,字母越前越"小"
在/不在集合中(in ,not in )
IN判断已告知是否在对于的列表中,如果是返回1,否则返回0
NOT IN判断一个值是否不在对应的列表中,如果不在则返回1,否则返回
示例:
select 2 in (1,2,3,4,5),'c' not in ('a','b','c');

通配符匹配
LIKE用来匹配字符串,如果匹配成功则返回1,反之返回0.LIKE支持两种通配符:’%‘
用于匹配任意数目的字符,而’_‘只能匹配一个字符。NOT LIKE正好跟LIKE相反,如果没有匹配成功则返回1,反之返回0
判断某字符串能否匹配成功,分单字符匹配和多字符匹配,也可以判断不匹配,具体操作如下所示
select 'bdgn' LIKE 'bdq_ ','kge' LIKE '%c', 'etc' NOT LIKE ' %th';

逻辑运算符
逻辑运算符又被称为布尔运算符,通常用来判断表达式的真假,如果为真返回1,否则返回0,真和假也可以用TRUE和FALSE表示。MysQL中支持使用的逻辑运算符有四种
not 或 ! 逻辑非
and 或 && 逻辑与
or逻辑或
xor逻辑异或
逻辑非(not 或 !)
逻辑非将跟在他后面的值取反,如果not后面的操作数为0时,所得值为1:
如果操作数为非0时,所得值为0;
如果操作数为NULL时,所得值为NULL
小结;返回值为0, 1, null值(根据匹配条件判断为何值)
select not 2,!3,not 0,!(4-4);

逻辑与(AND或&)
AND 和 &&都是逻辑与运算符,具体语法规则为:
当所有操作数都为非零值并且不为NULL时,返回值为1
当一个或多个操作数为0时,返回值为0;操作数中有任何一个为NULL时,返回值为NULL
select 2 and 1,2 && 0 , 0 && null,2 and null;

and 和 && 作用相同
AND -1中没有0 或者NULL,所以返回值为1
AND 0中有操作数0,所以返回值为0;
AND NULL虽然有NULL,所以返回值为NULL
null 和 0 返回值为0
逻辑或(OR)
OR是逻辑或运算符,具体语法规则为:
当两个操作数都为非NULL值时,如果有任意一个操作数为非零值,则返回值为1,否则结果为0:
当有一个操作数为NULL时,如果另一个操作数为非零值,则返回值为1,否则结果为NULL
假如两个操作数均为NUL时,则返回值为NULL
select 2 or 3 ,0 or null,1 or 1,0 or 0;

逻辑异或
XOR表示逻辑异或,具体语法规则为:
当任意一个操作数为NULL时,返回值为NULL;
对于非NULL的操作数,如果两个操作数都是非 0值或者都是0值,则返回值为1;
如果一个为0值,另一个为非0值,返回值为1
select 2 xor 3, 0 xor 1,1 xor 0,1 xor null,null xor 0;

位运算符
位运算符是在二进制数上进行计算的运算符。
位运算会先将操作数变成二进制制数进行位运算。
然后再将计算结果从二进制数变回十进制数。
& 按位与
| 按位或
^ 按位异或
! 取反
<< 左移
>> 右移
按位与运算(&) ,是对应的二进制位都是1的,它们的运算结果为1,否则为0,所以10 & 15的结果为10.
select 10 & 15;
按位或运算(|) ,是对应的二进制位有一个或两个为1的,运算结果为1,否则为0, 所以101 15的结果为15
select 10 | 15;
按位异或运算(^) ,是对应的二进制位不相同时,运算结果1,否则为0,所以10^ 15的结果为5
select 10 ^ 15 ;
按位取反(~) ,是对应的二进制数逐位反转,即1取反后变为0,0取反后变为1,数字1的二进制是0001,取反后变为1110,数字5的二进制是0101,将1110和0101进行求与操作,其结果是二进制的0100,转换为十进制就是4;
select 10 &~1;
以上运算符优先级
1:!
2:~
3:^
4:*,/,%
5:+,-
6:>>,<<
7:&
8:|
9:=,<=>,>=,<=,<>,!=,IS,LIKE,REGEXP,IN
10:BETWEEN,CASE,WHEN,THEN,ELSE
11:NOT
12:&&,AND
13:OR,XOR
14::=
15:
16:
连接查询
MySQL的连接查询,通常都是将来自两个或多个表的行结合起来,基于这些表之间的共同字段,进行数据的拼接。首先,要确定一个主表作为结果集,然后将其他表的行有选择性的连接到选定的主表结果集上。使用较多的连接查询包括:内连接、左连接和右连接
模板
create table test1 (a_id int(11) default null,a_name varchar(32) default null,a_level int(11) default null);
create table test2 (b_id int(11) default null,b_name varchar(32) default null,b_level int(11) defauult null);
insert into test1(a_id, a_name, a_level) values(1, 'aaaa', 10);
insert into test1(a_id, a_name, a_level) values(2, 'bbbb', 20);
insert into test1(a_id, a_name, a_level) values(3, 'cccc', 30);
insert into test1(a_id, a_name, a_level) values(4, 'dddd', 40);
insert into test2(b_id, b_name, b_level) values(2, 'bbbb', 20);
insert into test2(b_id, b_name, b_level) values(3, 'cccc', 30);
insert into test2(b_id, b_name, b_level) values(5, 'eeee', 50);
insert into test2(b_id, b_name, b_level) values(6, 'ffff', 60);
内连接
MySQL中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在FROM子句中使用关键字INNER JOIN来连接多张表,并使用 on 字句设置连接条件,内连接是系统默认的表连接,所有在from 字句后可以省略inner 关键字,只使用 关键字 jion 同时有多个表时,也可以连续使用 inner join 来实现多表的内连接,不过为了更好 性能,建议最好不要超过三个表
select a.a_id,a.a_name,a.a_level from test1 as a inner join test2 b on a_id=b_id;
select a_id,a_name,a_level from test1 inner join test2 on a_id = b_id;
左连接
左连接也可以被称为左外连接,在FROM子句中使用LEFT JOIN或者LEFT OUTER JOIN关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
select * from test1 left join test2 on test1.name=test2.name
左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为NULL
右连接
右连接也被称为 右外连接,在 from 字句中 使用 right join 或者 right outer join关键字来表示,右连接跟左连接正好相反,他是以右表为基础表,用于接受右表中的所有行,并用这些记录与记录左表中的行进行匹配
select * from test1 right join test2 on a.name=b.name;
在右表连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹配的行,这些记录在左表中以null 补足
以上是关于Linux 常用命令(要求全而精)的主要内容,如果未能解决你的问题,请参考以下文章