楔子
Redis虽然是一个缓存,但是它也可以作为一个消息队列。所以redis还是比较有野心的,本来在缓存方面就已经把memcached给干掉了,但还想在消息队列的方向上闯一闯。不过虽说Redis支持消息队列,但是它还是作为缓存更加的专业,大公司很少有将redis作为消息队列来使用的,因此消息队列的话一般还是使用rabbitmq、activemq之类的会比较好。
发布订阅模式
在 Redis 中提供了专门的类型:Publisher(发布者)和 Subscriber(订阅者)来实现消息队列。
不过在介绍消息队列之前,先抛出几个概念,这样理解下文会更加轻松一些,当然都是老生常谈的内容了。
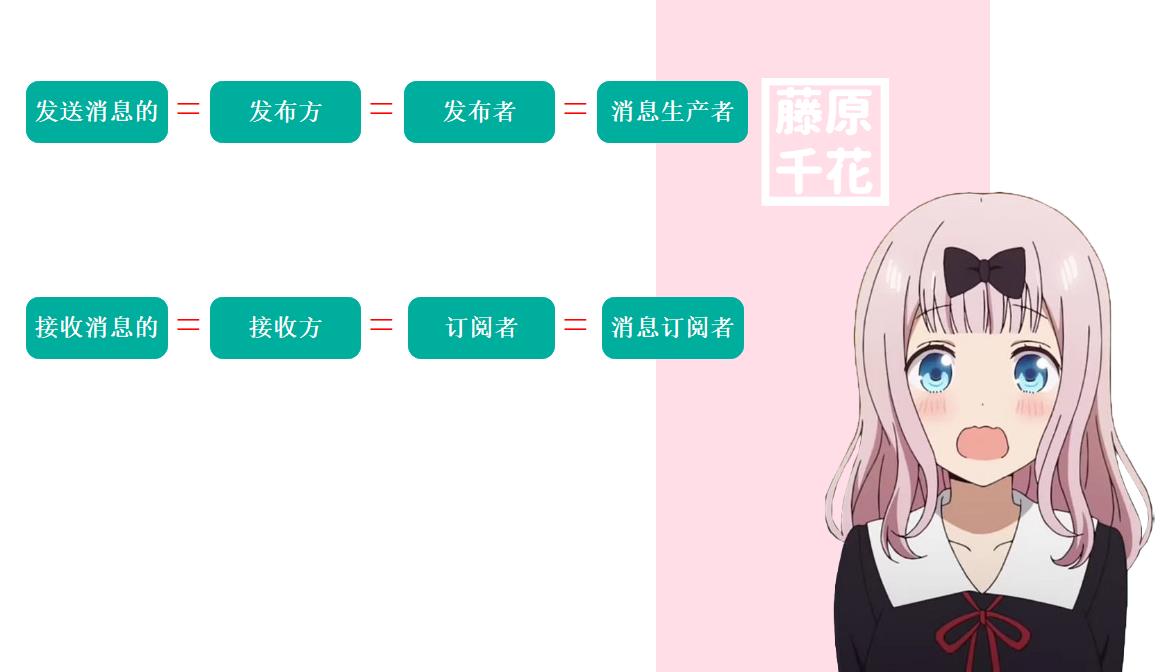
发布消息的叫做发布方或发布者,也就是消息的生产者。接收消息的叫做消息的订阅方或订阅者,也就是消费者,用来处理生产者发布的消息。
除了发布和和订阅者,在消息队列中还有一个重要的概念:channel,指的是管道,可以理解为某个消息队列的名称。首先消费者先要订阅某个 channel,然后当生产者把消息发送到这个 channel 中时,消费者就可以正常接收到消息了,如下图所示:
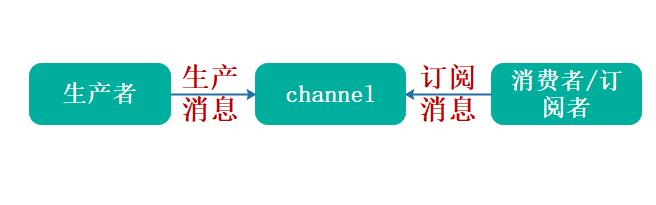
普通订阅与发布
消息队列有两个重要的角色,一个是发送者,另一个就是订阅者,对应的命令如下:
发布消息:publish channel "message"订阅消息:subscribe channel
下面我们来看具体的命令实现。
订阅消息
127.0.0.1:6379> subscribe channel1 channel2 # 可以同时订阅多个频道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
1) "subscribe"
2) "channel2"
3) (integer) 2
注意:当我们订阅某个频道的时候,就阻塞在这里了。
就类似于微信公众号一样,你关注了某个公众号,那么当公众号上面发表文章的时候,你就可以收到。此时操作公众号的人就是消息发布者,你就是消息订阅者,公众号就是消息队列,往公众号上面发表的文章就是消息。
发送消息
我们上面的订阅者在订阅之后,就处于阻塞状态,因此我们需要再开一个终端。
127.0.0.1:6379> publish channel1 "mea: please please money"
(integer) 1
127.0.0.1:6379> publish channel2 "mea: please please money"
(integer) 1
127.0.0.1:6379>
返回值表示成功发送给了几个订阅方,所以这里的 1 就表示成功发给了一个订阅者,这个数字可以是 0~n,这是由订阅者的数量决定的。如果有两个订阅者,那么返回值就是2。
然后我们来看看订阅者:
127.0.0.1:6379> subscribe channel1 channel2
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
1) "subscribe"
2) "channel2"
3) (integer) 2
1) "message"
2) "channel1" # channel1 接收到消息
3) "mea: please please money"
1) "message"
2) "channel2" # channel2接收到消息
3) "mea: please please money"
主题订阅
主题订阅说白了,和模糊匹配是类似的。假设我们需要订阅好几个消息队列,但它们都是以log开头的,那么我们就可以通过psubscribe log*来自动订阅所有以log开头的队列。
比如我们上面的channel1、channel2,我们就可以通过psubscribe channel*实现,至于消息发布者则不需要变。
当然主题订阅也可以是多个,比如:psubscribe log* db*,订阅所有以log开头、db开头的消息队列。
Python操作Redis的发布订阅
# 订阅者
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 调用pubsub方法返回一个订阅者
sub = client.pubsub()
# 订阅两个队列
sub.subscribe("ch1", "ch2")
# 监听,此时处于阻塞状态
for item in sub.listen():
# 一旦发布者发布消息,这里就可以接收到
# item["channel"]是频道,item["data"]是接收到了内容
print(item["channel"], item["data"])
# 发布者
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 发布者很简单,直接发布消息接口
client.publish("ch1", "屑女仆1")
client.publish("ch1", "屑女仆2")
client.publish("ch2", "屑女仆3")
当执行发布者的时候,会发现订阅者多了几条输出,至于内容显然是发布者发布的内容。
Python操作Redis,订阅者还有几种方式。
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
sub = client.pubsub()
sub.subscribe("ch1", "ch2")
while True:
# 这种方式会瞬间返回,如果有消息得到消息,没有消息会返回None
item = sub.get_message()
if item:
print(item["channel"], item["data"])
或者开启一个新的线程去监听。
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
sub = client.pubsub()
sub.subscribe("ch1", "ch2")
def handler(item):
print(item["channel"], item["data"])
# 给每一个频道注册一个处理函数,当频道有消息时,会自动将消息传递给处理函数
# 注意:上面的pubsub中订阅的频道都要有对应的处理函数
# 假设我们只给ch1注册了处理函数,那么执行的时候就会报错:Channel: \'ch2\' has no handler registered
sub.channels.update({"ch1": handler, "ch2": handler})
# 开启一个线程运行,会返回新开启的线程对象,注意:因为是单独开了一个线程,所以这里不会阻塞的,会直接往下走
th = sub.run_in_thread()
print("xxx")
print("yyy")
print("zzz")
# 先启动订阅者,再启动发布者,程序输出如下
"""
xxx
yyy
zzz
ch1 屑女仆1
ch1 屑女仆2
ch2 屑女仆3
"""
# 注意:这里程序依旧会卡住,因为开启的线程是非守护线程
# 所以即便主线程执行完毕,也依旧会等待子线程
# 解决的办法有两种:
# 一种是在run_in_thread中加上一个参数daemon=True,设置为守护线程,这样主线程就不会等待了
# 另一种是手动停止,我们说sub.run_in_thread会返回新开启的线程,然后调用其stop方法即可
th.stop() # 通过这种方式,我们可以在任意时刻停止监听。
对于主题订阅,发布者代码不用变,只需要将订阅的sub.subscribe换成sub.psubscribe即可。
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
sub = client.pubsub()
sub.psubscribe("ch*")
def handler(item):
print(item["channel"], item["data"])
# 对于开启新的线程去监听,要将之前的self.channels换成self.patterns
sub.patterns.update({"ch*": handler})
sub.run_in_thread()
取消订阅
既然有订阅,那么就要取消订阅,就类似于取关(o(╥﹏╥)o)。
使用unsubscribe channel1 channel2可以取消订阅多个channel,同理对于psubscribe ch*,也有punsubscribe ch*取消订阅指定模式的频道。比较简单,不再赘述。
注意事项
发布订阅模式存在以下两个缺点:
无法持久化保存消息,如果 Redis 服务器宕机或重启,那么所有的消息将会丢失;发布订阅模式是"发后既忘"的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
然而这些缺点在 Redis 5.0 添加了 Stream 类型之后会被彻底的解决。
除了以上缺点外,发布订阅模式还有另一个需要注意问题:当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是 client-output-buffer-limit pubsub 32mb 8mb 60。
小结
这一节介绍了消息队列的几个名词,生产者、消费者对应的就是消息的发送者和接收者,也介绍了发布订阅模式的几个命令:
subscribe channel:普通订阅publish channel message:消息推送psubscribe pattern:主题订阅unsubscribe channel:取消普通订阅punsubscribe pattern:取消主题订阅
使用它们之后就可以完成单个频道和多个频道的消息收发,但发送与订阅模式也有一些缺点,比如“发后既忘”和不能持久化等问题,然而这些问题会等到 Stream 类型的出现而得到解决,关于更多 Stream 的内容后面文章会详细介绍。
实现消息队列的其它方式
在 Redis 5.0 之前消息队列的实现方式有很多种,比较常见的除了我们上文介绍的发布订阅模式,还有两种:List 和 ZSet 的实现方式。
List 和 ZSet 的方式解决了发布订阅模式不能持久化的问题,但这两种方式也有自己的缺点,接下来我们一起来了解一下,先从 List 实现消息队列的方式说起。
List版消息队列
List 方式是实现消息队列最简单和最直接的方式,它主要是通过 lpush 和 rpop 存入和读取实现消息队列的,如下图所示:
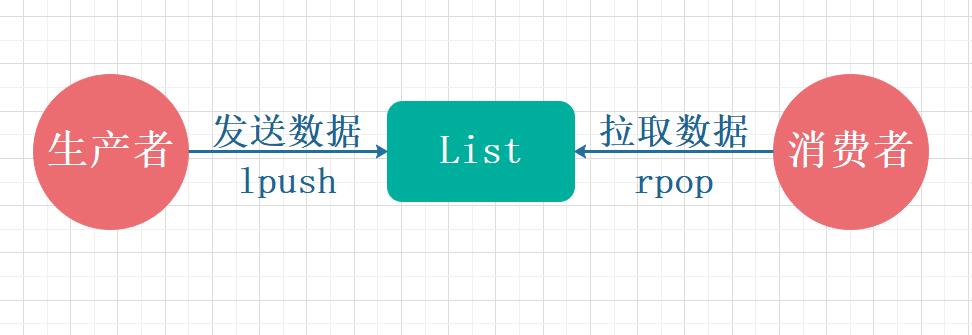
List 使用命令的方式实现消息队列:
127.0.0.1:6379> lpush channel message1
(integer) 1
127.0.0.1:6379> lpush channel message2
(integer) 2
127.0.0.1:6379> rpop channel
"message1"
127.0.0.1:6379> rpop channel
"message2"
127.0.0.1:6379>
lpush用于生产消息,rpop用于消费消息。
然后我们使用Python来操作List模拟消息队列。
import threading
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
def producer(messages: list):
for message in messages:
client.lpush("mq", message)
print("生产者往队列mq里放入消息:", message)
def consumer():
while True:
# brpop里面可以传入一个timeout,表示设置超时时间,默认为0,会一直阻塞
print("消费者从队列mq中消费了消息:", client.brpop("mq"))
t1 = threading.Thread(target=producer, args=([f"message{_}" for _ in range(10)],))
t2 = threading.Thread(target=consumer)
t1.start()
t2.start()
for t in threading.enumerate():
if t is not threading.main_thread():
t.join()
"""
消费者从队列mq中消费了消息: (\'mq\', \'message0\')
生产者往队列mq里放入消息: message0
生产者往队列mq里放入消息: message1
消费者从队列mq中消费了消息: (\'mq\', \'message1\')
生产者往队列mq里放入消息: message2
消费者从队列mq中消费了消息: (\'mq\', \'message2\')
生产者往队列mq里放入消息: message3
消费者从队列mq中消费了消息: (\'mq\', \'message3\')
生产者往队列mq里放入消息: message4
消费者从队列mq中消费了消息: (\'mq\', \'message4\')
生产者往队列mq里放入消息: message5
消费者从队列mq中消费了消息: (\'mq\', \'message5\')
消费者从队列mq中消费了消息: (\'mq\', \'message6\')
生产者往队列mq里放入消息: message6
消费者从队列mq中消费了消息: (\'mq\', \'message7\')
生产者往队列mq里放入消息: message7
消费者从队列mq中消费了消息: (\'mq\', \'message8\')
生产者往队列mq里放入消息: message8
消费者从队列mq中消费了消息: (\'mq\', \'message9\')
生产者往队列mq里放入消息: message9
"""
我们看到使用List实现了一个类似于队列的方式,但这显然也是有其优缺点的
优点
消息可以被持久化,借助 Redis 本身的持久化(AOF、RDB 或者是混合持久化),可以有效的保存数据;消费者可以积压消息,不会因为客户端的消息过多而被强行断开。
缺点
消息不能被重复消费,一个消息消费完就会被删除;没有主题订阅的功能。
ZSet 版消息队列
相比于之前的List 和发布订阅方式,ZSet 版消息队列在实现上要复杂一些,但 ZSet 因为多了一个 score(分值)属性,从而使它具备更多的功能,例如我们可以用它来存储时间戳,以此来实现延迟消息队列等。
它的实现思路和 List 相同也是利用 zadd 和 zrangebyscore 来实现存入和读取,这里就不重复叙述了,可以根据 List 的实现方式来实践一下,看能不能实现相应的功能。如果写不出来也没关系,我们会在后面学习延迟队列,到时候会用 ZSet 来实现。
优点
支持消息持久化;相比于 List 查询更方便,ZSet 可以利用 score 属性很方便的完成检索,而 List 则需要遍历整个元素才能检索到某个值。
缺点
ZSet 不能存储相同元素的值,也就是如果有消息是重复的,那么只能插入一条信息在有序集合中;ZSet 是根据 score 值排序的,不能像 List 一样,按照插入顺序来排序;ZSet 没有向 List 的 brpop 那样的阻塞弹出的功能。
小结
这一节我们介绍了消息队列的另外两种实现方式 List 和 ZSet,它们都是利用自身方法,先把数据放到队列(自身的数据结构)里,再使用无限循环读取队列中的消息,以实现消息队列的功能,相比发布订阅模式,这两种方式的优势是支持持久化,当然它们各自都存在一些问题。
消息队列的终极解决方案--stream(上)
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
发布订阅模式 PubSub,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;列表实现消息队列的方式不能重复消费,一个消息消费完就会被删除;有序集合消息队列的实现方式不能存储相同 value 的消息,并且不能阻塞读取消息。
基础使用
Stream 既然是一个数据类型,那么和其他数据类型相似,它也有一些自己的操作方法,例如:
xadd:添加消息;xlen:查询消息的长度;xdel:根据消息ID删除消息;del:删除整个stream,当然del可以删除任意的key;xrange:读取区间消息;xread:读取某个消息之后的消息;
我们看一下具体如何操作。
添加消息
语法:xadd key ID field1 string1 field2 string2······
127.0.0.1:6379> xadd my_stream * name mea age 19
"1594952987816-0"
127.0.0.1:6379>
其中*表示Redis使用的规则:时间戳+序号的方式自动生成ID,当然你也可以指定自己的ID
查询消息的长度
语法:xlen key
127.0.0.1:6379> xlen my_stream
(integer) 1
127.0.0.1:6379> xadd my_stream * name hanser age 28 # 再添加一条
"1594953077142-0"
127.0.0.1:6379> xlen my_stream # 长度变为2
(integer) 2
127.0.0.1:6379>
删除消息
语法:xdel key 消息ID·····,可以同时删除多个
127.0.0.1:6379> xlen my_stream
(integer) 2
127.0.0.1:6379> xdel my_stream 1594953077142-0
(integer) 1
127.0.0.1:6379> xlen my_stream
(integer) 1
127.0.0.1:6379>
删除整个stream
直接使用del,它可以删除任意多个任意的key
127.0.0.1:6379> del my_stream
(integer) 1
127.0.0.1:6379>
查询区间消息
xrange key start end count n,这里的start和end指的是消息ID。
127.0.0.1:6379> # 添加几条消息
127.0.0.1:6379> xadd mq * name satori age 17
"1594953403230-0"
127.0.0.1:6379> xadd mq * name koishi age 16
"1594953410148-0"
127.0.0.1:6379> xadd mq * name scarlet age 400
"1594953422249-0"
127.0.0.1:6379> xadd mq * name morisa age unknow
"1594953438554-0"
127.0.0.1:6379> # 查询
127.0.0.1:6379> xrange mq 1594953410148-0 1594953438554-0
1) 1) "1594953410148-0"
2) 1) "name"
2) "koishi"
3) "age"
4) "16"
2) 1) "1594953422249-0"
2) 1) "name"
2) "scarlet"
3) "age"
4) "400"
3) 1) "1594953438554-0"
2) 1) "name"
2) "morisa"
3) "age"
4) "unknow"
127.0.0.1:6379>
127.0.0.1:6379> # -表示第一条消息、+表示最后一条消息
127.0.0.1:6379> xrange mq - +
1) 1) "1594953403230-0"
2) 1) "name"
2) "satori"
3) "age"
4) "17"
2) 1) "1594953410148-0"
2) 1) "name"
2) "koishi"
3) "age"
4) "16"
3) 1) "1594953422249-0"
2) 1) "name"
2) "scarlet"
3) "age"
4) "400"
4) 1) "1594953438554-0"
2) 1) "name"
2) "morisa"
3) "age"
4) "unknow"
127.0.0.1:6379>
127.0.0.1:6379> # count n表示限定数量,这里是返回两条
127.0.0.1:6379> xrange mq - + count 2
1) 1) "1594953403230-0"
2) 1) "name"
2) "satori"
3) "age"
4) "17"
2) 1) "1594953410148-0"
2) 1) "name"
2) "koishi"
3) "age"
4) "16"
127.0.0.1:6379>
虽然这里查询用的是消息ID,但是也要像索引一样注意先后关系。start对应的消息要在end对应的消息之前,类似于索引。
查询某个消息之后的消息
语法:xread count n streams xxx MESSAGE_ID
从名为xxx的stream中,读取消息ID为MESSAGE_ID的后n条消息
127.0.0.1:6379> xread count 2 streams mq 1594953410148-0
1) 1) "mq"
2) 1) 1) "1594953422249-0"
2) 1) "name"
2) "scarlet"
3) "age"
4) "400"
2) 1) "1594953438554-0"
2) 1) "name"
2) "morisa"
3) "age"
4) "unknow"
127.0.0.1:6379>
127.0.0.1:6379> # 该消息后面只剩一条消息了,所以即便count为2,所以也只返回了一条
127.0.0.1:6379> xread count 2 streams mq 1594953422249-0
1) 1) "mq"
2) 1) 1) "1594953438554-0"
2) 1) "name"
2) "morisa"
3) "age"
4) "unknow"
127.0.0.1:6379>
并且该命令还提供了一个可以阻塞读取的参数block,我们可以使用它读取某条数据之后的新增数据。
比如:xread count 1 block streams mq $
$表示最后一条,此时程序会阻塞,会一直读取最后一条数据之后的新增数据,既然阻塞,那么肯定要开启两个终端才会看得到现象。
127.0.0.1:6379> xread count 1 block 0 streams mq $ # 程序就卡在了这里
127.0.0.1:6379> xadd mq * name mea age 19 # 新开一个窗口,添加数据
"1594969025661-0"
127.0.0.1:6379>
127.0.0.1:6379> xread count 1 block 0 streams mq $
1) 1) "mq"
2) 1) 1) "1594969025661-0"
2) 1) "name"
2) "mea"
3) "age"
4) "19"
(44.51s)
127.0.0.1:6379> # 此时接收到了新添加的数据,另外此时监听也就结束了。
Python实现stream
from pprint import pprint
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
def producer():
id_lst = []
for _ in [
{"name": "mashiro", "age": 17},
{"name": "satori", "age": 17},
{"name": "koishi", "age": 17}]:
id_lst.append(client.xadd("ch", _))
return id_lst
def consumer():
id_lst = producer()
# 第二个参数和第三个参数默认是"-"和"+",也就是全部读取
# 当然我们也可以使用xread,具体参数可以看注释
msg = client.xrange("ch", id_lst[0], id_lst[-1])
pprint(msg)
consumer()
"""
[(\'1594956361922-0\', {\'age\': \'17\', \'name\': \'mashiro\'}),
(\'1594956361929-0\', {\'age\': \'17\', \'name\': \'satori\'}),
(\'1594956361934-0\', {\'age\': \'17\', \'name\': \'koishi\'})]
"""
消息队列的终极解决方案--stream(下)
下面我们使用消息分组,不过在开始使用消息分组之前,我们必须手动创建分组才行,以下是几个和 Stream 分组有关的命令,我们先来学习一下它的使用。
消息分组命令
创建消费者群组
语法:xgroup create <stream_key> <group_key> <ID>
127.0.0.1:6379> xgroup create mq group1 0-0
OK
127.0.0.1:6379>
mq:stream的keygroup1:分组的名称0-0:表示从第一条消息开始读取
如果从当前最后一条消息向后读取的话,那么使用$即可。
127.0.0.1:6379> xgroup create mq group2 $
OK
127.0.0.1:6379>
读取消息
语法:xreadgroup group <group_key> <consumer_key> [count n] streams <stream_key>
group_key:创建的分组名consumer_key:消费者名,随便指定即可count n:每次读取的数量,可选,不指定全部返回stream_key:队列名称
127.0.0.1:6379> xreadgroup group group1 c1 count 1 streams mq > # 结尾应该还有个>,表示读取下一条消息
1) 1) "mq"
2) 1) 1) "1594953403230-0"
2) 1) "name"
2) "satori"
3) "age"
4) "17"
127.0.0.1:6379>
127.0.0.1:6379> xreadgroup group group1 古明地觉 count 1 streams mq > # 消费者名字随便起
1) 1) "mq"
2) 1) 1) "1594953410148-0"
2) 1) "name"
2) "koishi"
3) "age"
4) "16"
127.0.0.1:6379>
这个参数类似于xread,也可以设置阻塞读取。
127.0.0.1:6379> xreadgroup group group1 c2 streams mq > # 不指定count,将消息全部消费完
1) 1) "mq"
2) 1) 1) "1594953422249-0"
2) 1) "name"
2) "scarlet"
3) "age"
4) "400"
2) 1) "1594953438554-0"
2) 1) "name"
2) "morisa"
3) "age"
4) "unknow"
3) 1) "1594969025661-0"
2) 1) "name"
2) "mea"
3) "age"
4) "19"
127.0.0.1:6379> xreadgroup group group1 c2 streams mq > # 此时已经获取不到消息了
(nil)# 另外,我们这里消费者数量是不受限制的,它们消费的都是同一个队列里面的数据
127.0.0.1:6379> xreadgroup group group1 c2 block 0 streams mq > # 开启阻塞监听状态
127.0.0.1:6379> xadd mq * name nagisa age 21 # 在另一个终端中向mq中发送一条数据
"1594970144178-0"
127.0.0.1:6379>
127.0.0.1:6379> xreadgroup group group1 c2 block 0 streams mq >
1) 1) "mq"
2) 1) 1) "1594970144178-0"
2) 1) "name"
2) "nagisa"
3) "age"
4) "21"
(119.02s)
127.0.0.1:6379> # 我们看到这里收到了数据,并且提示我们等待了119.02秒
消息消费确认
一般消息接收完了,我们会回复一个确认信息,告知我们消费完毕,命令:xack key group-key ID······
127.0.0.1:6379> xack mq group1 1594970144178-0
(integer) 1
127.0.0.1:6379>
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 ack 确认消息已经被消费完成,整个流程的执行如下图所示:
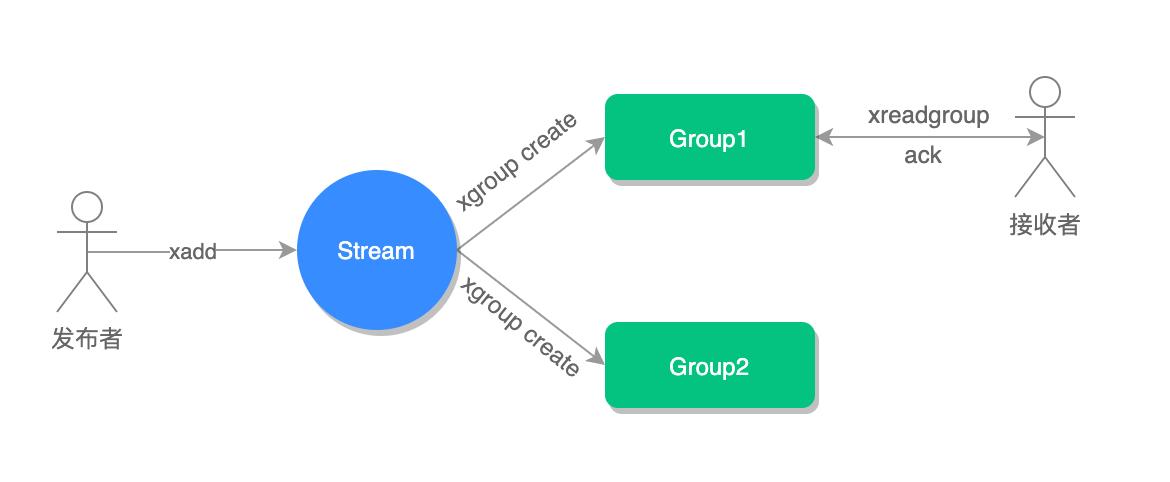
查询未确认的消费队列
127.0.0.1:6379> xpending mq group1
1) (integer) 5 # 未确认(ack)的消息数量为 1 条
2) "1594953403230-0"
3) "1594969025661-0"
4) 1) 1) "c1"
2) "1"
2) 1) "c2"
2) "3"
3) 1) "\\xe5\\x8f\\xa4\\xe6\\x98\\x8e\\xe5\\x9c\\xb0\\xe8\\xa7\\x89"
2) "1"
127.0.0.1:6379>
127.0.0.1:6379> xack mq group1 1594953403230-0 1594969025661-0 # 确认两条
(integer) 2
127.0.0.1:6379> xpending mq group1 # 还剩下三条
1) (integer) 3
2) "1594953410148-0"
3) "1594953438554-0"
4) 1) 1) "c2"
2) "2"
2) 1) "\\xe5\\x8f\\xa4\\xe6\\x98\\x8e\\xe5\\x9c\\xb0\\xe8\\xa7\\x89"
2) "1"
127.0.0.1:6379>
xinfo 查询相关命令
1. 查询流信息:xinfo stream stream_key(队列)
127.0.0.1:6379> xinfo stream mq
1) "length"
2) (integer) 6 # 队列中有6个消息
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1594970144178-0"
9) "groups" # 2个消费分组,我们上面的group1 group2
10) (integer) 2
11) "first-entry"
12) 1) "1594953403230-0"
2) 1) "name"
2) "satori"
3) "age"
4) "17"
13) "last-entry"
14) 1) "1594970144178-0"
2) 1) "name"
2) "nagisa"
3) "age"
4) "21"
127.0.0.1:6379>
查询消费组消息:xinfo groups stream_key
127.0.0.1:6379> xinfo groups mq
1) 1) "name"
2) "group1" # 消息分组名称
3) "consumers"
4) (integer) 3 # 3个消费者
5) "pending"
6) (integer) 3 # 三个未确认的消息
7) "last-delivered-id"
8) "1594970144178-0"
2) 1) "name"
2) "group2"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "1594953438554-0"
127.0.0.1:6379>
查询消费组成员信息:xinfo consumers stream_key group_key
127.0.0.1:6379> xinfo consumers mq group1
1) 1) "name"
2) "c1" # 消费者名称
3) "pending"
4) (integer) 0
5) "idle"
6) (integer) 25214247
2) 1) "name"
2) "c2"
3) "pending"
4) (integer) 2
5) "idle"
6) (integer) 24613903
3) 1) "name"
2) "\\xe5\\x8f\\xa4\\xe6\\x98\\x8e\\xe5\\x9c\\xb0\\xe8\\xa7\\x89" # 中文名的消费者
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 25200911
127.0.0.1:6379>
删除消费者:xgroup delconsumer stream-key group-key consumer-key
127.0.0.1:6379> xgroup delconsumer mq group1 c2
删除消费组:xgroup destroy stream-key group-key
127.0.0.1:6379> xgroup destroy mq group1
(integer) 1
127.0.0.1:6379>
小结
感觉消息队列的话,发布订阅和主题订阅不是很难,但是stream的命令有点头疼,这里介绍的不是很详细。建议自己理解一下,并实际动手操作。